
Our Biggest Launch Event Yet.
May 14th saw us announce a ton of new capabilities and provides a window into the future.
There is a lot to say today. I’m gonna dive right in.
On Tuesday, May 14th, we held a launch event. We launched 15-20 new capabilities depending on how you count. I couldn’t possibly go through all of these here, but you can read all about them. I am incredibly proud of our team—we’re moving quickly innovating on an incredibly broad set of product capabilities, including dbt code authoring, code execution, data quality, semantic layer, enterprise and multi-cloud capabilities, data catalog, and more.
Each innovation represents a meaningful extension of dbt’s ability to support the end-to-end analytics engineering workflow for companies from early-stage startups to the largest enterprises in the world.
But this event was more to me than just a launch event. It was also a coming out party.
In my intro, I talked about our vision of dbt as the “data control plane.” Here’s the slide:
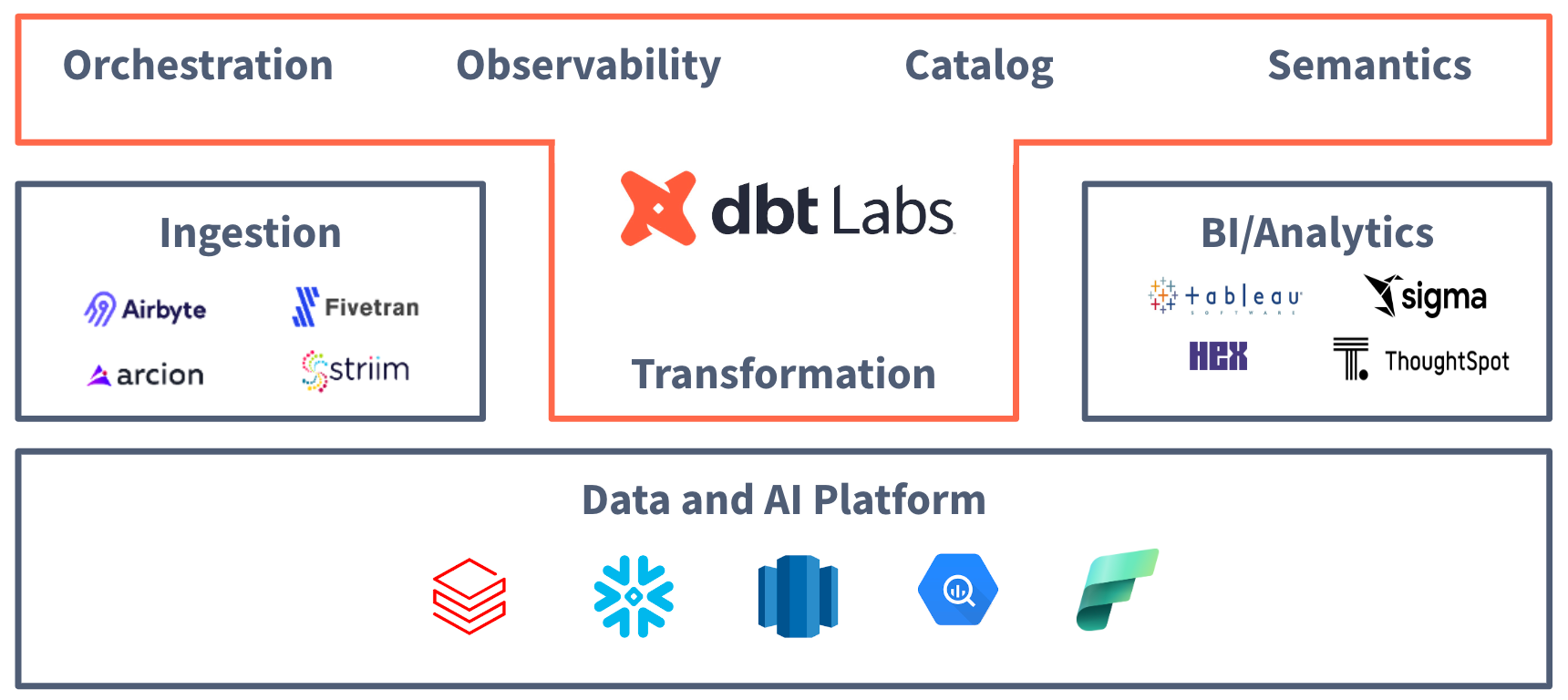
If you’ve followed my writing in this space over the past two years, this is likely not a huge surprise to you. I’ve talked a lot about the consolidation trends in our industry, about how the “modern data stack” as originally conceived in all its buy-and-integrate-12-products glory just isn’t how this industry is going to play out over the coming decade.
dbt has, for a long time, solved a broad set of customer needs: it has never lived exclusively inside of a single box in an industry diagram. All the way back in 2016 dbt shipped with data quality features. Back in 2018 dbt incorporated a lightweight data catalog. And if you look at the usage data, dbt’s data catalog is one of the most widely-adopted data catalogs in the world with tens of thousands of companies using it.
The community intuitively understands that dbt doesn’t live in a single box. Years ago one dbt user replicated much of an entire product category with a single dbt package. More recently, a startup did much the same thing in another category.
dbt created, and exists to facilitate, the analytics engineering workflow. That workflow spans the entire set of underlying activities, regardless of what Gartner decides a particular magic quadrant should be named.
Over the years we’ve extended dbt’s capabilities in orchestration, observability, and cataloging, and customers freaking love them. One of the best things about having an integrated platform is that new capabilities just … magically appear. There is no implementation, no integration, no nothing. No dbt customer had to do any work to get access to dbt Explorer, and now 1,400 companies are actively using it every single week. Given that it just went GA this week, that number is going to grow fast.
Ultimately, our belief in this single-control-plane vision comes from a small number of first principles:
The analytics engineering workflow spans a broad set of activities, and analytics engineers need tooling that respects that inherent unity. Disparate tooling will never adequately achieve this. In simple / small environments, good enough may be good enough, but in large / complex environments it will not be.
Buyers see the problem solved by the data control plane as a single problem and not as a set of discrete problems. They see the problem as “make data work for my business.”
The 800-pound-gorilla vendors in the space all see the problem this way too and their products / roadmaps very clearly recognize this.
The underlying capabilities of many / most of these product categories are very similar. They are all powered by metadata. The experiences built on top of the metadata may differ, but most of the work is in building the underlying metadata platform.
AI will drive innovation across this entire set of experiences, and AI has a centralizing effect. You don’t want 12 AIs with narrow ranges of capabilities, you want one. This is why ChatGPT is multi-modal.
One of the required capabilities of any mature control plane will be being cross-cloud.
When you add all of this up, there is a very clear conclusion. Welcome to the future of the data control plane.
We are far from the only team who has recognized this, and the race is on to fully live up to this vision. As the launches from Tuesday hopefully indicate, our team is moving fast.
===
Two other quick notes that are worth making about Tuesday’s launch events.
Code vs Low-Code: Why not both?
We announced a low-code / no-code experience for authoring dbt models. Here’s a screenshot:
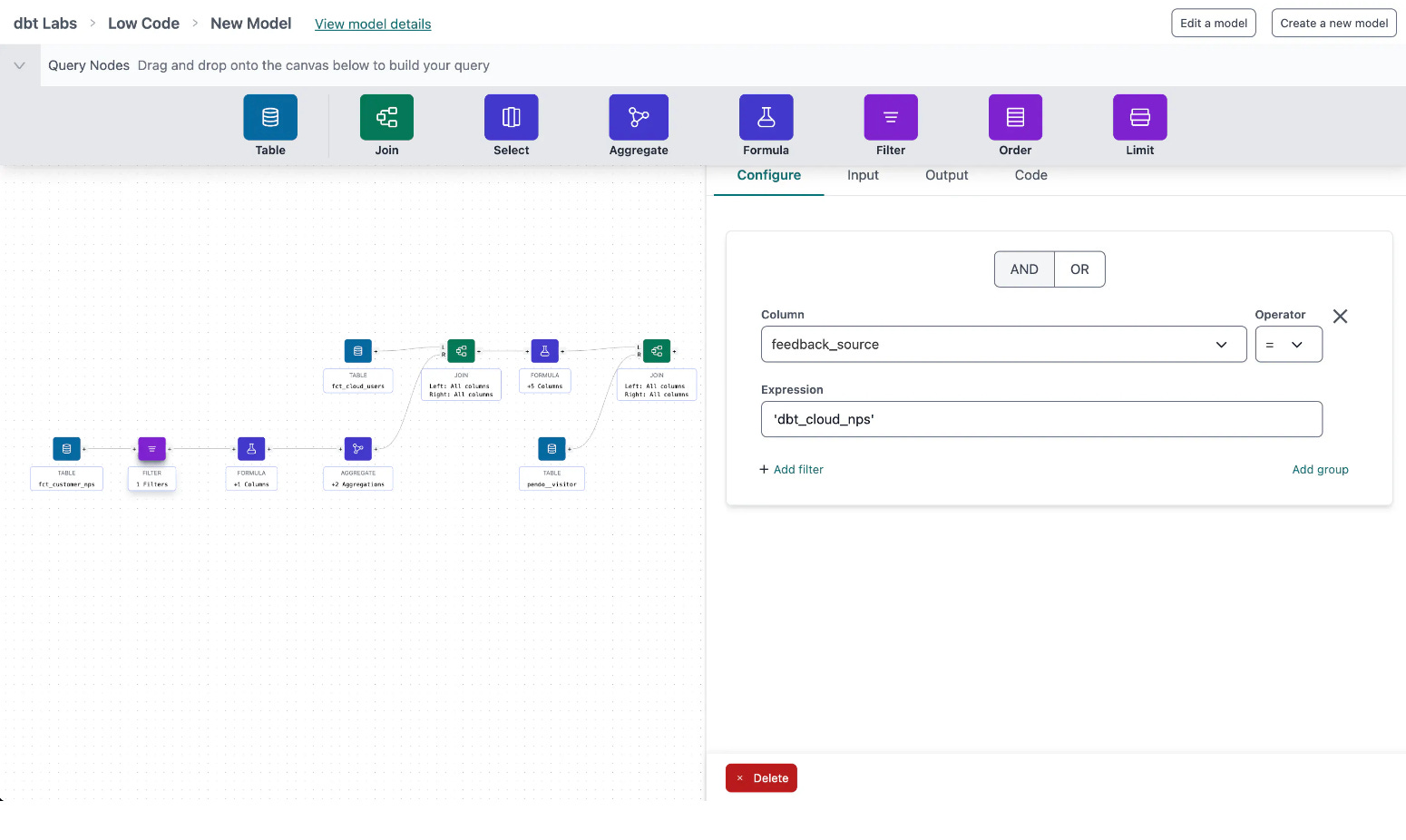
Interfaces like this have been around for a long time: I first used one back in 2003. I think there are good reasons why, if you spend a meaningful percentage of your professional life writing code, you should not want to use this type of interface. But! As analytics engineering becomes more pervasive, we should absolutely want more and more stakeholders to participate. And the inherent visual nature of this type of interface makes it extremely accessible and quick to learn. Sure, you can probably learn SQL from scratch in a couple of days, but you can learn how to manipulate data in a visual interface like this in five minutes.
Accessibility matters. You can see how much we care about this in all areas of dbt—our mission is to empower data practitioners to create and disseminate knowledge, and the more people that can participate in that the better.
There is a perception, however, that this type of visual tooling is directly at odds with our vision for analytics engineering. Here’s how one very awesome community member put it to me in a Slack DM:
In one of the first few blog posts you wrote on the dbt blog and on every job posting on the dbt Labs Careers page, there's this statement:
We believe that:
Code, not graphical user interfaces, is the best abstraction to express complex analytic logic
Data analysts should adopt similar practices and tools to software developers
…
Do these statements not contradict your recent focus on low-code development experiences?
Certainly, we should update our job postings because I can see where this impression comes from. But I don’t think there’s any inherent tension at all between analytics engineering, mature software practices, and low code. As long as the low code product writes code!
The most important thing about our just-announced low code editing experience is that it both reads and writes well-formatted, readable dbt code. This was a hard requirement for me in order for us to invest in this product capability, and we’ve absolutely lived up to it.
Every model you build using this editor is written to its own model file.
The code it generates is standard dbt-sql.
The code written largely complies with our SQL style guide and we’re continuing to make tweaks to make it even better.
Once ready, model code will get get checked into git and will participate in a standard pull request / CI/CD process just like any other code.
Our low-code editor can read hand-written dbt code and build an editor experience around it. So the same model can be both worked on by hand and in the low-code experience by different authors.
I am not interested in having us build some part of the dbt experience that totally throws out all of the fundamental principles of the analytics engineering workflow. We built our new low code editor in a way that acts as a good citizen in that workflow, bringing the maturity of analytics engineering into the hands of a brand new set of users.
I could not be more excited about where this will take dbt and its community in the coming years. There’s a lot to do. If you’re interested in using the beta once it’s ready, sign up here.
AI for dbt
Speaking of code: it turns out that language models are quite good at writing code, including all types of dbt code. Documentation, tests, and more. We announced a new copilot experience for dbt and demoed two initial capabilities: writing tests and writing documentation. There will be plenty more to come in the future, including the ability to create models from scratch.
When we originally went all-in on code as the underlying construct from which to build dbt, we didn’t anticipate the innovation in LLMs that we’re seeing today. But dbt’s design could not be more well-aligned with it. Every aspect of a dbt project is already captured in code, and enabling a large language model to accelerate your dbt development does not require major changes to the product or a major research effort. You should anticipate seeing continued progress on this front.
There is a worldwide conversation going on about how AI will play out, and one of the dimensions of that conversation is about how it will affect the job market. Here is specifically what I believe about how AI will impact the role of data practitioners:
There have never been enough data practitioners to go around. This has always been a huge problem, both for practitioners themselves (who are overworked) and the businesses who employ them (who never feel like they have enough).
dbt already breaks down the problem of analytics engineering into very clear components: testing, documentation, modeling, scheduling, etc. Because there is already a clearly-defined framework, it is very possible to teach AI to do each of these tasks with a high degree of both accuracy and testability.
Because of (2) and based on early estimates from experiments, we believe it is possible to see efficiency improvements from 50-75% in the core tasks of analytics engineering.
Because of (1), these efficiency improvements will not cause businesses to invest less in humans who do this work, but rather more because they are getting so much more value. This is an example of Jevons Paradox.
There is plenty more to say on this topic, much of which centers around the centrality of the semantic layer to the unfolding AI narrative (more here and here). But that will have to be a topic for another day. If you’re interested in getting access to the just-announced beta, sign up here.
Other stuff I’m paying attention to
Sunsetting open source data-diff
This is in itself a non-story: startup releases a subset of its features as OSS, gets some adoption, decides (for whatever reason) that the experiment didn’t work, discontinues support for the OSS distribution. Fine—this is a thing that happens every day, nothing anyone should be surprised about.
What’s interesting is the bigger picture and how this tiny little instance points at something larger. OSS is hard. I constantly talk about OSS as “playing on hard mode.” You might get some real advantages out of your OSS strategy but you also create some real challenges. In a world where cash is free and growth rates are high, the advantages seem to outweigh the disadvantages. When that world shifts, that relationship can sometimes flip for an individual company/project. It is not an accident that Datafold launched this OSS project in 2022 and closed it down in 2024.
There is a TON of OSS in AI right now. Infra, models, etc. It turns out that cash is cheap and growth rates are off the charts in AI. Awesome! If you love OSS, then these conditions are a great way to see a lot of OSS get built.
Finally: open source software without active maintainership is not useful. It quickly gets bricked; software is a living thing. Who maintains OSS is a fascinating and interesting topic, and there are many workable models. But all come with tradeoffs. The truth is though that most OSS projects simply don’t have enough support to continue living on indefinitely and get abandoned.
You can read the post yourself, but sounds like the team at Sigma has made some real progress on the business, which is (IMO) freaking fantastic. Great growth, some solid efficiency gains, put Sigma on a path towards a long-lived part of the data ecosystem!
The longer any innovative data company stays independent, the longer they get to innovate and define their own road. I think the Sigma product is fantastic—have loved it since I think 2018-19?—and I’m excited to see them build the business and product to the next level. Congrats folks.
Are Emergent Abilities of Large Language Models a Mirage?
This paper from a year ago is something I just came across and it makes me question one of the things I thought I knew about LLMs: sudden emergence of properties at certain model sizes.
Abstract follows.
Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models that are present in larger-scale models. What makes emergent abilities intriguing is two-fold: their sharpness, transitioning seemingly instantaneously from not present to present, and their unpredictability, appearing at seemingly unforeseeable model scales. Here, we present an alternative explanation for emergent abilities: that for a particular task and model family, when analyzing fixed model outputs, emergent abilities appear due to the researcher's choice of metric rather than due to fundamental changes in model behavior with scale. Specifically, nonlinear or discontinuous metrics produce apparent emergent abilities, whereas linear or continuous metrics produce smooth, continuous predictable changes in model performance. We present our alternative explanation in a simple mathematical model, then test it in three complementary ways: we (1) make, test and confirm three predictions on the effect of metric choice using the InstructGPT/GPT-3 family on tasks with claimed emergent abilities; (2) make, test and confirm two predictions about metric choices in a meta-analysis of emergent abilities on BIG-Bench; and (3) show to choose metrics to produce never-before-seen seemingly emergent abilities in multiple vision tasks across diverse deep networks. Via all three analyses, we provide evidence that alleged emergent abilities evaporate with different metrics or with better statistics, and may not be a fundamental property of scaling AI models.
Really happy about the new bigger/broader vision! I think most of us are tired of the tool sprawl and ready to consolidate!
One risk of low-code is that it alienates engineers. When you build dashboards in code, you're an engineer. When you build dashboards in Tableau, you're a "dashboard builder." No engineer wants to be a dashboard builder. You'll get a different audience (which is fine, the dbt equivalent of "dashboard builders"), and they won't be engineers. Engineers take pride in writing code, nothing more and nothing less.