
13 Questions. Specialization in the Data Team. Literate Programming. Data Catalogs. [#258]

New podcast episode! This time, my co-host Julia takes a turn on the hot seat and graciously allows me to ask her about her backstory as a math nerd, VC, and so much more. This is a fun one :) As always, reviews and recommendations are *very* helpful as this thing gets off the ground.
Enjoy the issue!
- Tristan
My 13 Questions
Last week I got the opportunity to get together at an offsite with the dbt Labs leadership team (6 humans, all vaccinated + covid tests for any potential exposures). It was…so great. Zoom meetings are just not that good for big picture thinking and idea generation. Or at least, they aren’t for me.
Coming back from that 48-hour period, my brain has been buzzing. Not wanting to lose some of that perspective before reengaging with reality, I took some time to write down a list of questions that feel important to me today. My main takeaway: whatever it is that we are doing as an industry right now, it is still early days. There is a lot that we do not know, but (and this is what makes it exciting) the fundamental shifts that have unlocked the modern data landscape appear to be quite persistent. So we have time to figure this out, to get good at it.
Click through for the full conversation below…lots of good threads came out of this. I’m still very much following along in the conversation so please do jump in!
On specialization in the data team
Fantastic Erik Bernhardsson blog post all organized around the engagement on this tweet:
Remember that image that I posted a few issues ago? Erik’s saying that’s too many roles. My first (very human) response to that is defensiveness…I’ve been a part of the industry movement towards the data engineer / analytics engineer / data analyst / data scientist 4-role-team, so I immediately hear a perspective like this as criticism! But, letting the moment pass and thinking more analytically about Erik’s perspective, there’s a lot of good stuff to unpack. Let me hit a few high notes.
First, I think I’ve been living with some dissonance here. I’ve been talking publicly about distinct roles while only personally hiring generalists to do data work. At dbt Labs we have never specialized our data roles—we train all client-facing humans to work across the entire stack. It’s for exactly the reason that Erik mentions:
Reduction of transaction cost. If every project involves coordinating 1,000 specialists, and each of those specialists have their own backlog with their own prioritization, then (a) cycle time would shoot up, with a lot of cost in terms of inventory cost and lost learning potential (b) you would need a ton more project management and administration to get anything done.
Even as we are building our own internal analytics team, we’re hiring folks with the same full-stack expectation. If data is fundamentally about generating insights, you need to be able to pursue those insights as an autonomous agent (not a ticket in a queue) if you want to want to get anywhere.
Second, Erik focuses a lot on the “tooling is bad” argument. I 100% agree that tooling is helping to create this specialization problem. My perspective, though, is that it’s not that it is “bad”…it’s that it is disconnected and inflexible.
Modern tooling built for software engineers has some pretty consistent traits that you, as a user, can expect:
All or appreciably all of the functionality of the product will be exposed via its API.
It will have a CLI and language bindings for all major languages, all built on top of its API, allowing it to be integrated into any existing internal tooling ecosystem.
It will generally be built on the Unix philosophy: “Make each program do one thing well.”
These things in combination give software engineers control when constructing their tooling, choosing a variety of tools that serve their particular use case and all communicate in common protocols. The impacts of this? Software engineers don’t learn tools as much as they learn coding practices. Adopting new tools becomes straightforward and doesn’t create skillset boundaries among teams of full-stack engineers. (There are certainly exceptions to this…Kubernetes!…but the trend over time is that this becomes more true, not less.)
Wow would data teams look different if all of our tools were built using these principles!! The more you look around, the more you start to see all of the negative impacts of a disconnected tooling ecosystem. What if a single set of data generalists were equally comfortable ingesting, transforming, analyzing, building data products on, creating predictions from, and asserting quality of their data? I think we’re actually starting to see this type of ecosystem come together with companies like TopCoat, LightDash, Continual, Meltano, and us(!).
We (dbt Labs) are not blameless here—we have less API coverage in dbt Cloud than I’d like today!—but are moving in the right direction.
Benn also riffed on the topic of team specialization in his most recent newsletter. It’s good, and you should read it. The one part that I don’t believe is explicitly true is Benn’s dig at self-service / code-free / “analyst-free” experiences:
Real advancement comes from removing friction between analyst and expert, not by replacing analysts with a limited code-free AI.
:shrug: why not both? Insisting on intermediation by analysts between non-analysts and their data feels like just another, dare I say, unnecessary division. As much as I’m sensitive to arguments that understate the value of the data analyst, I’m also sensitive to gatekeeping of who can productively analyze data. My answer to that is: everyone.
Returning to the main thread…how do we get to a place where the industry is made up of “full stack data analysts” (the term we used to use internally before consolidating around “analytics engineers”)? I don’t think any of us has all of the answers, but it seems that there is agreement that the current divisions are suboptimal.
Speaking of barriers between roles, a dbt Slack member asked:
Where does the responsibility of Backend Engineers end and Data Engineers start?
…and the response was fantastic. Worth catching up on the thread if you haven’t read it.
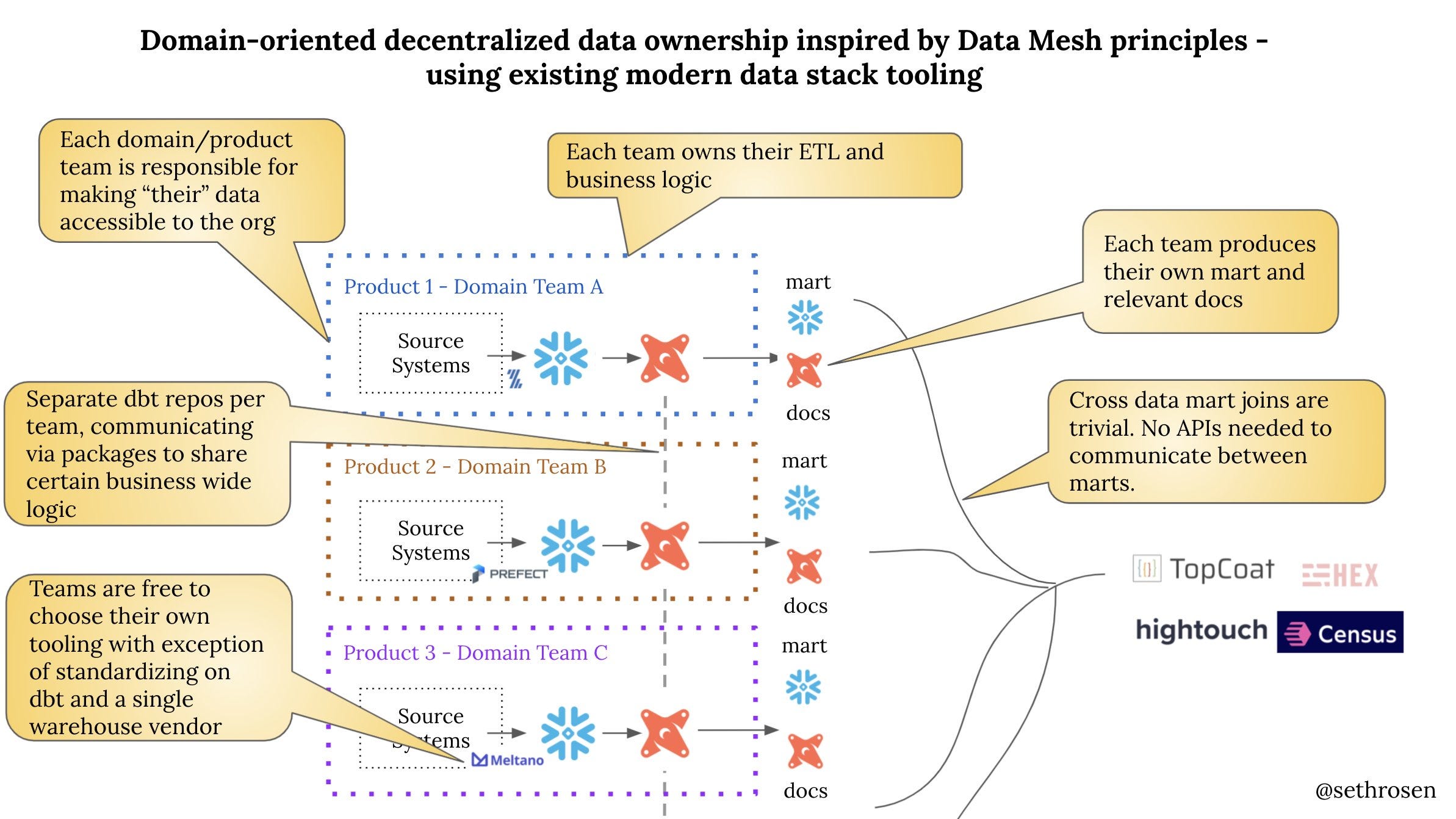
Seth Rosen on Data Mesh
Saying a lot in one image. This made me LOL.
Other stuff…
I recently did a talk at a Mixpanel all hands meeting where I discussed my thesis around vertical-specific data products in the modern data stack. This blog post is a curated version of my comments.
Airbnb published about their Wall testing framework. Comments in Slack about it:
a team at Airbnb built dbt testing on top of Airflow?
Reading through this post, it feels like the team was optimizing for a set of technical criteria, not user experience. But without great UX, developers will choose not to write tests! This approach might work inside of a company that explicitly puts controls in place (“You cannot push to prod without test coverage”) but doesn’t work to change behavior throughout an industry. Let’s make data testing as pleasant as Cucumber!!
Sean Taylor, creator of open source timeseries forecasting library Prophet, was interviewed on the Data Exchange podcast about the evolution of data science. One of the trends he points out: role specialization! The same thing is happening inside of data science as I discussed above, although it looks a little more like stats-focused DS, AI-focused DS, and ML engineering.
Another great podcast from Claire Carroll and Boris Jabes discussing analytics engineering, the dbt community, and more.
Barr Moses and Gordon Wong wrote a fantastic and thoughtful post on the future of data catalogs highlighting the core product problem to solve:
In a past life, one of our former colleagues spent two years building a data dictionary no one used. Why? When his team was done, the requirements were stale and the solution was no longer relevant.
Natty sent me a great post (thanks!!) on the state of the “analytical application stack”. Great quote on why the answer is not an embedded BI product:
Put simply — the iframe is not the right contract between product engineering and data teams.
Long, but great read on the future of this important space.
Finally…
I was recently linked to this wonderful, wonderful page. It had been a while since I had read any Donald Knuth, and every time I return to it it’s inspiring. The below was written in 1984:
I believe that the time is ripe for significantly better documentation of programs, and that we can best achieve this by considering programs to be works of literature. Hence, my title: "Literate Programming."
Let us change our traditional attitude to the construction of programs: Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.
The practitioner of literate programming can be regarded as an essayist, whose main concern is with exposition and excellence of style. Such an author, with thesaurus in hand, chooses the names of variables carefully and explains what each variable means. He or she strives for a program that is comprehensible because its concepts have been introduced in an order that is best for human understanding, using a mixture of formal and informal methods that reinforce each other.