
50 Useful ML APIs. Airflow x 2. Command line tips. Sergey's Thoughts on AI. [DSR #134]

❤️ Want to support us? Forward this email to three friends!
🚀 Forwarded this from a friend? Sign up to the Data Science Roundup here.
The Week's Most Useful Posts
Data’s Inferno: 7 Circles of Data Testing Hell with Airflow
Real data behaves in many unexpected ways that can break even the most well-engineered data pipelines. To catch as much of this weird behaviour as possible before users are affected, the ING Wholesale Banking Advanced Analytics team has created 7 layers of data testing that they use in their CI setup and Apache Airflow pipelines to stay in control of their data.
This is potentially the best post I have ever seen on data integrity testing. I believe data engineering reliability is probably the single biggest area of weakness in sophisticated data organizations today, and almost every organization could learn a lot from the CI practices outlined in this post.
Google Cloud Composer is now in Beta
Speaking of Airflow…
Today, Google Cloud is announcing the beta launch of Cloud Composer, a managed Apache Airflow service, to make workflow creation and management easy, powerful, and consistent.
Over the past 2-3 years, Airflow has gone from being one option for orchestration to being the option for orchestration. It’s now an Apache project, has hundreds of contributors, and I almost never find myself having conversations about what were previously other solutions to this problem (Luigi, Azkaban, Oozie…).
There are certainly other managed Airflow solutions, but this is the first one released by a major cloud provider to my knowledge, which means its going to be a lot cheaper than the other options out there today. Likely more reliable, too.
If you’re running Airflow and managing the infrastructure yourself, this deserves a look.
Command Line Tricks For Data Scientists
Aspiring to master the command line should be on every developer’s list, especially data scientists. Learning the ins and outs of your terminal will undeniably make you more productive.
I really could not agree more. I’ve personally made the transition from GUI to command line over the past two years and, while still not an expert by any stretch, am now far more efficient for it. This post includes basic stuff (like head) but eventually gets pretty real with sed and awk.
If you’re interested in improving your productivity, command line proficiency is probably your single best investment.

Another creative post from FlowingData. The above image is a 3-D printed heatmap of shots made by Steph Curry. The post contains around 20 similar prints, each with analyses like this:
Stephen Curry of the Golden State Warriors makes a lot of threes and shoots mid-range shots fairly evenly across the floor. The most distinguishing characteristic is how far away from the line that Curry makes threes. This is more obvious when you actually hold the distribution and compare it against others.
I’m not an NBA fan, but I am super-interested about what cheap, good 3-D printing will do to the accessibility of data. If people more frequently held physical copies of data analyses, would that change their emotional responses? Would it improve accessibility? Would we be able to identify patterns more easily?
50+ Useful Machine Learning & Prediction APIs
Wow—the cloud ML API space has certainly grown quickly. The first of these APIs were being released circa 2015 and now there are really quite a lot of them. The article groups them into image recognition, NLP, translation, and prediction.
If you’re solving one of these tasks in an upcoming project, it may make sense to see what’s available off the shelf first.
Alphabet: 2017 Founders’ Letter
Sergey Brin’s annual letter this year was heavily focused on AI. It likely doesn’t contain anything brand new to you, but I found it to be one of the most concise framings for the current state of computing. A couple of quotes:
The new spring in artificial intelligence is the most significant development in computing in my lifetime. When we started the company, neural networks were a forgotten footnote in computer science; a remnant of the AI winter of the 1980’s. Yet today, this broad brush of technology has found an astounding number of applications.
The Pentium IIs we used in the first year of Google performed about 100 million floating point operations per second. The GPUs we use today perform about 20 trillion such operations — a factor of about 200,000 difference — and our very own TPUs are now capable of 180 trillion (180,000,000,000,000) floating point operations per second.
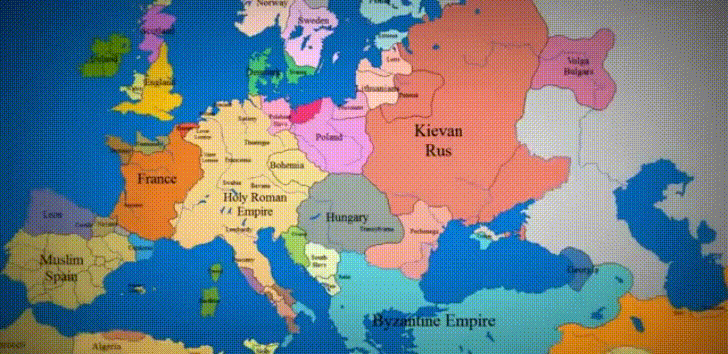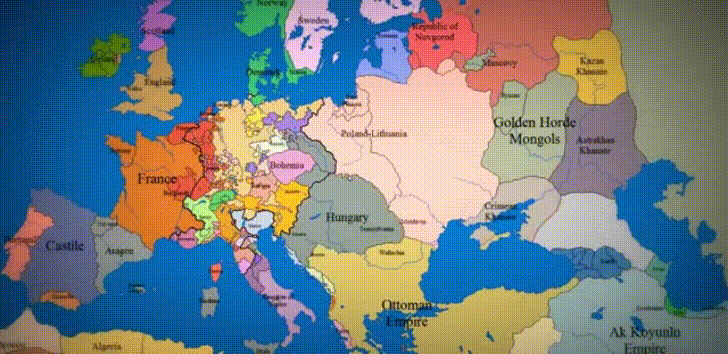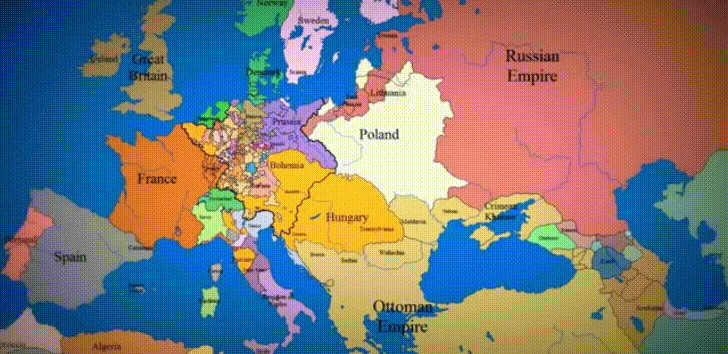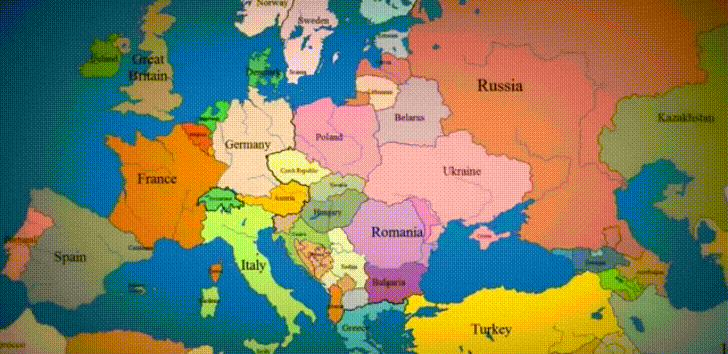
Data Viz of the Week
“1,000 years of History in 10 Seconds”
What a powerful tool to understand European history! There are so many stories contained in this image! The Irish struggle for independence, the rise and fall of the Ottoman Empire, the myriad of principalities that arose in the vacuum of power after the Holy Roman Empire collapsed. And of course, the conquest of basically all of Russia by the Golden Horde. I really think this is so cool…wish I could step through it frame-by-frame.
Thanks to our sponsors!
Fishtown Analytics: Analytics Consulting for Startups
At Fishtown Analytics, we work with venture-funded startups to implement Redshift, Snowflake, Mode Analytics, and Looker. Want advanced analytics without needing to hire an entire data team? Let’s chat.
Stitch: Simple, Powerful ETL Built for Developers
Developers shouldn’t have to write ETL scripts. Consolidate your data in minutes. No API maintenance, scripting, cron jobs, or JSON wrangling required.
The internet's most useful data science articles. Curated with ❤️ by Tristan Handy.
If you don't want these updates anymore, please unsubscribe here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue
915 Spring Garden St., Suite 500, Philadelphia, PA 19123