
A Catalog Is All You Need
Last year I asked you to give Iceberg a REST. This year, it finally got one.


Way back in 2018 it took me a day or two of banging my head against my keyboard to connect two on-premise SQL Servers with external tables.1 “How could it be hard?” I thought. As I learned more in the intervening years, I came to appreciate the work (and luck) required to pull off the user experience I dreamed of. Today, I’m here to say it largely just works 2 — almost boringly so. Exactly how it should be.
So today I want to show you a “simple” dbt demo that’s been years in the making. The big shift it points to: the catalog is becoming the unit of interoperability — not for one query engine, but for all of them. In practice: your local dbt project can write a table straight into the catalog another team already works in — no warehouse-specific export, no copy job.
After that, we’ll cover:
Why a catalog is a bookmark, not a technology
How far we’ve come since I last wrote about Iceberg
The behind-the-scenes work making this possible
What might come next
Some homework
The demo
As far as dbt projects go, it’s dead simple — only 4 models and one seed, whose profile specifies DuckDB as the target. It runs on my laptop. But it’s also so much more: data is being written directly to a data platform with only DuckDB SQL and its Iceberg extension.
TL;DR: changing one line in dbt_project.yml turns my local DuckDB into a multi-catalog stack that federates across data platforms, writing directly into the built-in, proprietary managed catalogs of both Snowflake and Databricks (“Horizon” and “Unity Catalog” respectively).
# this is it. this is the demo.
models:
aws_cloud_cost:
+catalog_name: horizon # or 'unity' / 'lakekeeper' / 'ducklake' / 'polaris'Look at how the demo project is laid out, because the file boundaries are the org chart:
catalogs.ymlis where the gritty infrastructure stuff lives that, at most, a few folks set up once and tweak only occasionallythe
catalog_nameconfig: what everyone else uses, e.g.catalog_name: horizon
The complexity stays, but it gets put where it belongs: in YAML that a platform team configures once, not in every analyst’s Spark config, JAR classpath, or stored procedure.
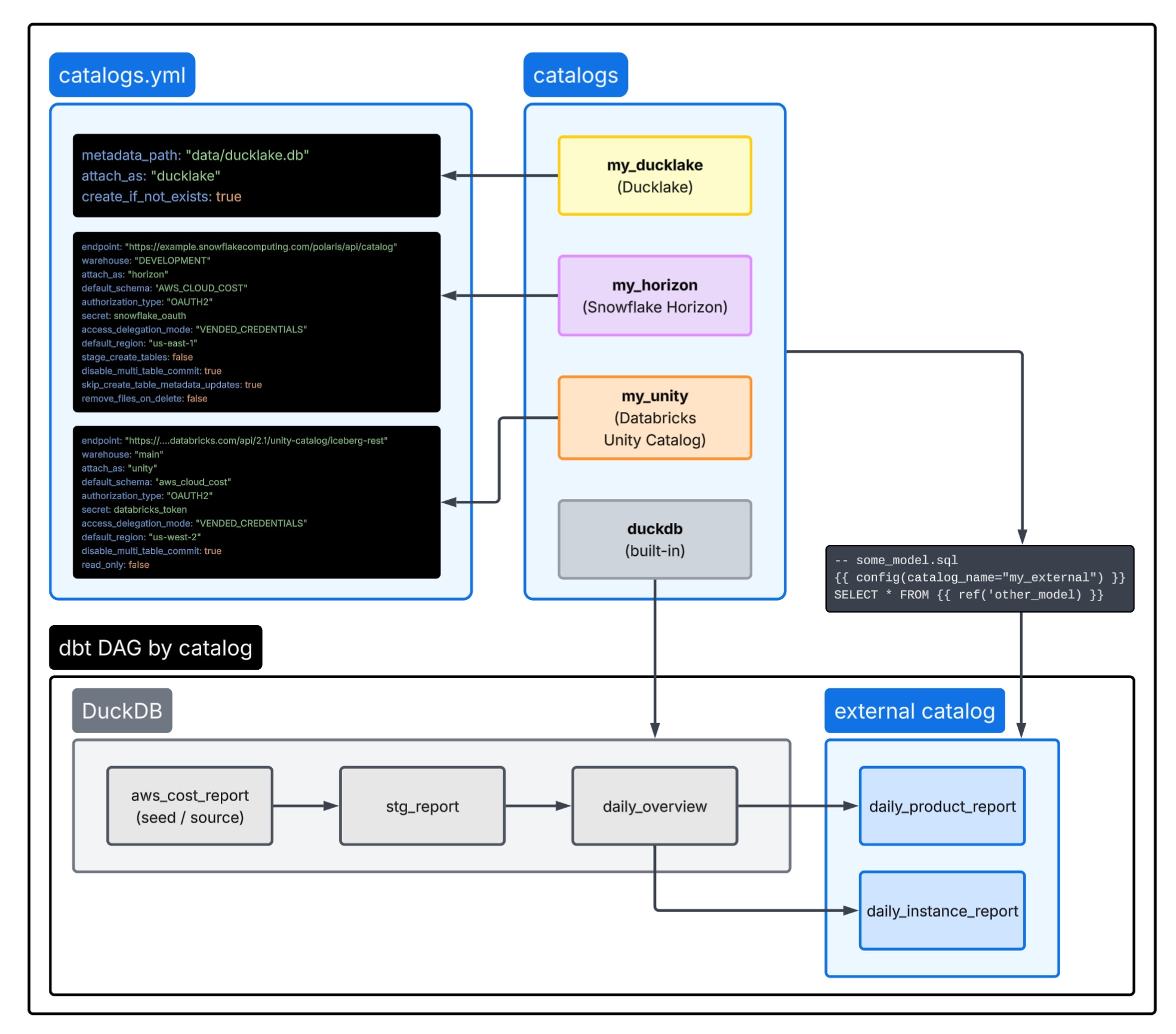
No platform-to-platform copy job. No Spark cluster and its requisite Java dependencies. No private preview, “coming soon” hand-waving. One project, one engine, and a table that lands wherever the data needs to be so other teams can access it.
The final unbundling
This demo proves what Tristan said in October last year:
Open data infrastructure is pluggable, standards-based, and not tied to any one compute engine.
The Iceberg REST catalog (IRC) is the standard, the engine is whatever you use, and the “plug” is a dbt resource you can reference with one line of YAML.
A catalog is a bookmark. It’s a dog-eared page in your dbt project that says “these tables go here”, doing the same job that schemas and databases do today. But this time, “here” is no longer locked inside a mainframe or the nearly equivalent walled garden of a cloud data platform — the kind that takes years to migrate into and out of. Now a catalog can just be: the place marketing reads from. The place the ML pipelines eat from. The place raw source data lands.
Iceberg Is An Implementation Detail (2024), by former “townie”, Amy Chen (now ClickHouse’s Iceberg PM), is as relevant as ever: Apache Iceberg is working when you don’t have to think about it! This is why it was vital to make catalogs first-class citizens in dbt, defined in catalogs.yml, so that every analytics engineer on the team can then use that catalog by name, and not think of anything else beyond.
Checking my homework
Last March I published Iceberg?? Give it a REST!, in which I make the case that the database catalog unbundled from its query engine is the key to unlocking the future that many others and I envision. Databases have long used catalogs to mean the top-level namespace into which you put your tables and views. Many query engines like Trino and Spark have long had the concept of a catalog. But not until the Iceberg REST catalog did we have a primitive that readily integrates with virtually all query engines. This is the future we live in now.
At the end of the blog I also made a bold prediction.
“Perhaps this moment comes when data platform catalogs support external writes3, and this will be true in six months. Time will tell!”
Time has told: both Snowflake and Databricks now have general availability for writing directly to their proprietary catalogs (Horizon and Unity Catalog, respectively)4.
The sheer amount of cooperation (and competition) by the data platform vendors on open source data infrastructure is truly a sight to behold, especially on Iceberg. It makes me think of the Antarctic Treaty: unglamorous, yet fundamental to scientific research. Apache Iceberg is the data community’s Antarctica — territory, neutral by treaty, where the ecosystem can compete and cooperate at the same time. As I told Tristan on the podcast back in March: the making of a treaty is the treaty. The goodwill is the standard.
There’s no shortage of recent evidence indicating that things will continue to improve, notably:
Databricks’ OpenSharing announced last week
Snowflake’s GA announcement at their summit for reads and writes to the default Horizon catalog from external engines
Both Snowflake and Databricks have docs on how to connect to one another’s Iceberg catalogs.
What a time to be alive!
The journey to an uncoupled catalog is taken one PR at a time
Fixes in this space are thorny! The bug might live in the catalog implementation, the extension, the engine, or the adapter. But thanks to open source, many shoutouts are due — both to dbters and to Duck Labs (née DuckDB Labs)5.
Here at dbt Labs, my colleagues and I have been working on and thinking about the abstraction of external catalogs for years. Today the underlying abstraction of the IRC is stable and fully-featured enough to evolve dbt’s catalog abstraction to its final form6.
Duck Labs also deserves praise for the fixes and features they’ve been shipping (a number of them shipped by yours truly). Check out New DuckDB-Iceberg Features in v1.5.3 to get a sense of how mature the DuckDB Iceberg integration is (spoiler: it’s in stable territory, will soon support Iceberg v3, and begin work on v4). To learn more about the dbt <> DuckDB collaboration happening on Iceberg, check out the “technical weeds”7 section below for the PRs that are required to make the demo work.
What’s next?
Once the catalog is the abstraction, the underlying format starts to look more like a swappable implementation detail. So the next frontier isn’t just covering every IRC and engine — it’s standardizing across lakehouse formats.
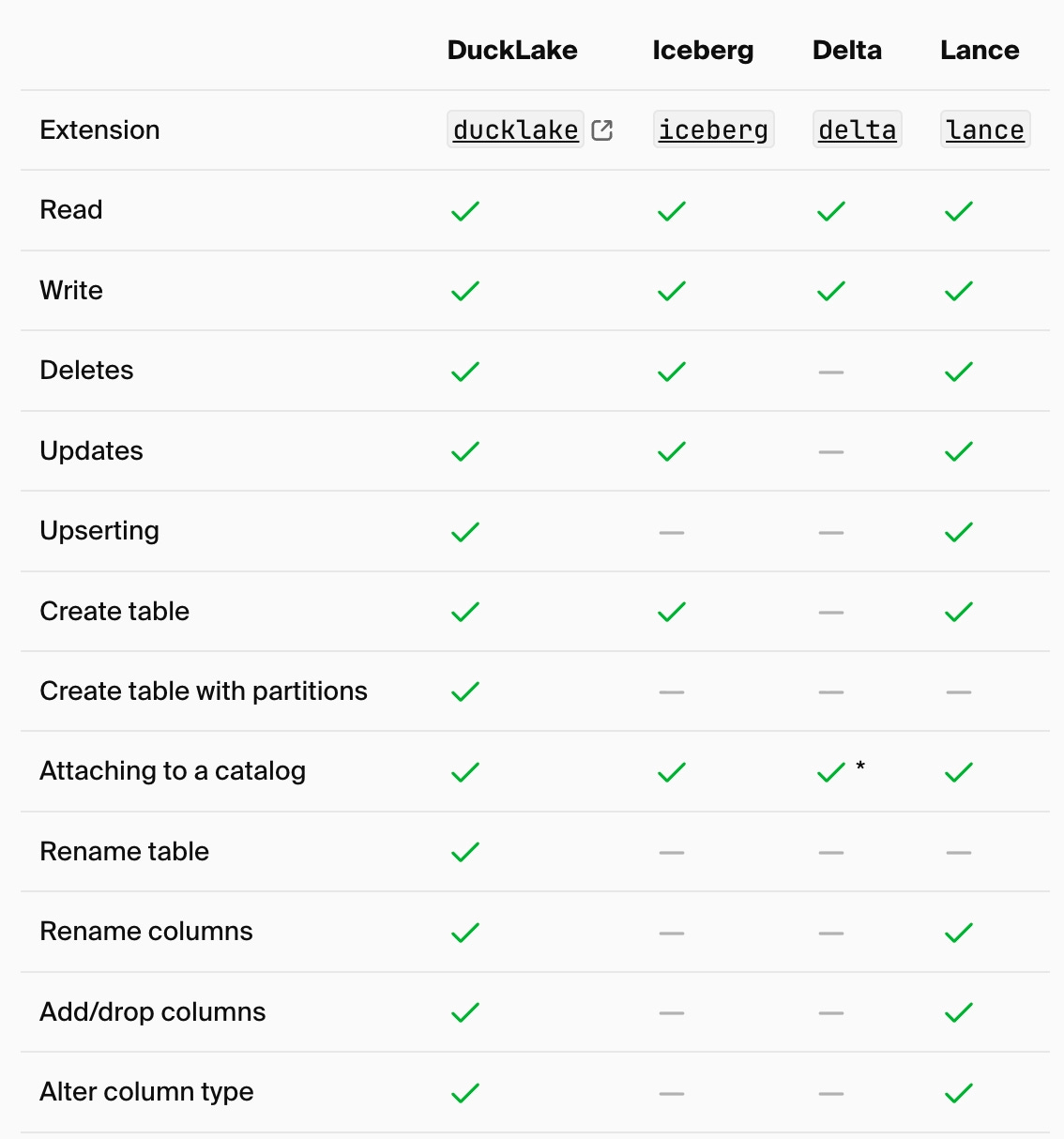
DuckLake is the test case: the best-supported format in DuckDB today (no surprise — both came out of Duck Labs), built to solve the “many files problem,” one of Iceberg’s biggest knocks. But Iceberg v4 tackles that directly. So I’ll predict:
DuckLake will be remembered less as a competitor to Iceberg than as a forcing function to improve it.
And if a shinier format shows up tomorrow, the ecosystem absorbs it — because:
a catalog (abstraction) is all you need
Your homework
Want to start down the Iceberg rabbit hole today? I highly recommend you (ideally in collaboration with an AI agent):
understand what IRC use cases are already supported by your current data platform
connect with PyIceberg to whatever IRC you have available to answer basic questions about your data (better yet, use this iceberg explorer agent skill)
follow your data platform’s quickstart guide to create and connect to an Iceberg REST catalog
If you have a handle on those, you’re unblocked to embark on these game-changing quests:
Point laptop DuckDB at your platform’s Iceberg catalog and read production tables — you’ve unblocked dev and CI without a warehouse bill.
Hand a dataset to another team by writing it into their catalog — no FTP, no copy jobs, no “can you grant my service account access to your bucket?” Congratulations: you just did cross-platform Mesh by hand.
p.s. Technical weeds
You’re still here?! Cool! Let me regale you with the nuance that’s been papered over in the past few months. The change I’ve been chewing on most is dbt-core#15239, which enables DuckDB to write to Unity Catalog, Snowflake Horizon, and others.
On the DuckDB side, there have been a number of changes:
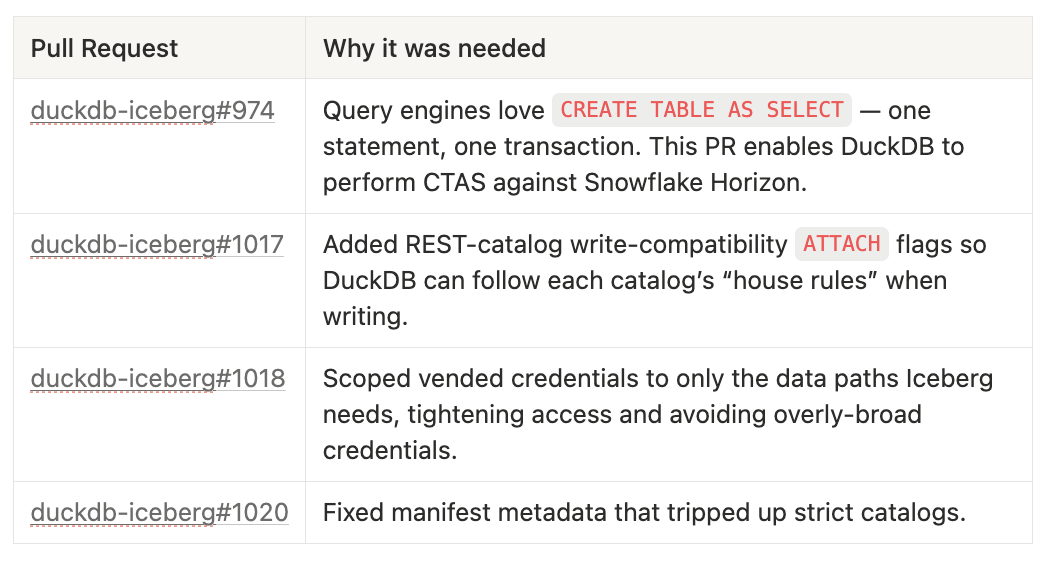
Currently both dbt and DuckDB have to encode how each IRC differs slightly from the others. The true end state is that IRCs either:
continue to standardize
advertise any necessary differences to query engines via the
capabilities/REST endpoint (see: this proposal linked within apache/iceberg#10462)
pro-tip: external tables will happily join across servers — just don’t try to push 1M rows through one, or you’re gonna have a bad time
Of course, there’s some caveats:
There’s still work to enable incremental materializations
writing to an Iceberg table is never going to be as fast as writing to your laptop or within the walled garden of a proprietary data platform (but that’s not the point!)
At the time of writing, these changes aren’t yet shipped in a stable DuckDB release. They’ll land with DuckDB 1.5.4; until then, you can build the duckdb-iceberg extension from source and build dbt Core v2 from dbt-core#15239.
In Apache Iceberg REST catalogs parlance, “external writes” means the ability for a query engine to write directly to an Iceberg catalog that is owned and managed by someone else. This is no small feat, and much more complicated than just reading from someone else’s Iceberg catalog.
While I’m grading myself: I closed the March podcast with three wishes for the year ahead — push-based catalog updates, progress on the small-files problem, and external writes. Two of the three are landing as you read this. The ecosystem is moving faster than even its optimists.
We’d not be here today if not for the brain power devoted by folks at:
dbt Labs: @colin-rogers-dbt, @cmcarthur, and @jtcohen6. Special shoutout to @VersusFacit and @ajhlee-dbt for landing the new-and-much-improved v2 of the dbt
catalogsspecDuck Labs: Huge shoutout specifically to @Tishj and @Tmonster for their tireless work on the DuckDB adapter
the current most Iceberg-related discussion and previous ones and PRs and features and
As is tradition, the weeds live at the bottom of the post so the big picture can stay big.
This is great Anders! Im over here building demos with tools like Spark and PyIceberg to write to our Horizon catalog and it seems like I come back to the demo each week to update something about it given changes from the last week.
This space is moving very quickly and loving to see the changes. Really excited for V4, and for customers to really leverage V3 once it's got more maturity across different engines.