
A Year of Innovation in AI (Part 1 of 2)
My attempt to bring myself up-to-date on the latest and greatest.
My favorite thing about writing this newsletter is that it creates a forcing function for me to stay current. I know you will be surprised to hear it, but with a demanding job and two little ones (7 and 4 now!) I don’t have … a tremendous amount of mental bandwidth for just being fascinated about new developments in tech. Which really creates a lot of FOMO for me right now given the exciting things that are going on in AI.
My learning trajectory on AI since November 2022 has been, roughly:
Pre-November 2022: yeah I get it bert and gpt-2 are pretty cool. And I understand transformers. But they’re not that useful yet.
November 2022: holy crap that happened overnight.
December 2022: quickly learn how RAG and fine-tuning work. Understand OpenAI’s RLHF process (conceptually).
March 2023: Play with GPT-4. Impressed, obviously. Although clearly not anywhere close to predictable or similar to the way one would interact with another human to produce quality results.
All of 2023: Watch context windows increase. Neat! RAG is getting very capable, very quickly. Watch the tool stack explode overnight. Invest in some of them that have traction. Unclear how the space will really shake out though. Learn how to do basic prompt engineering. Have ChatGPT write a ton of bedtime stories for my kids.
After that, things become both noisier and less substantive. Yes, absolutely, there has been a ton of application-level innovation over the past year (which is awesome), but I do feel like there was a categorically different thing happening in 2022-23 where the state-of-the-art was moving fast, not just application space.
You can actually see that in the below chart—-after consistent progress on MMLU benchmarks for several years, things have basically been flat since GPT-4’s launch in March of ‘23.
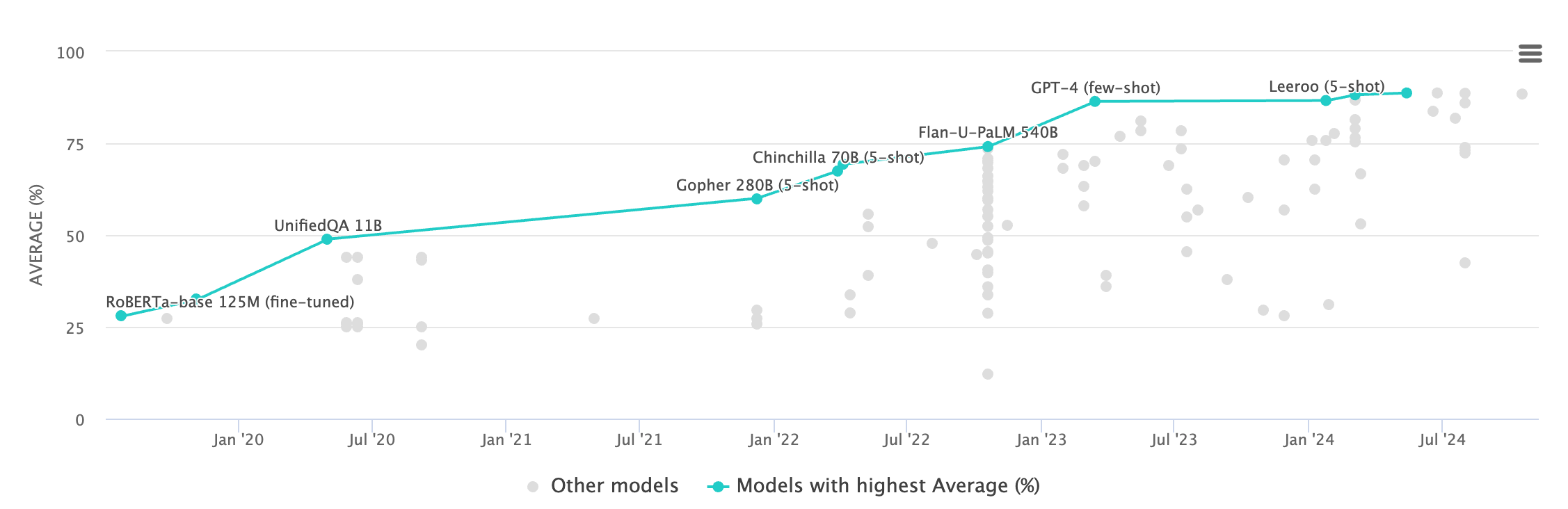
Ok—I understand: MMLU benchmarks aren’t everything, agree. But still—to me, the shape of this line to me is highly correlated with how quickly I feel like I’ve needed to update my mental model on the cutting-edge capabilities in AI.
But then—but then!—the DeepSeek news become The Major Story of the entire news cycle for like 1-2 weeks. Not tech news, but all news, given the impact on the stock market and (theoretically) US/China relations. Which is an impressive feat given everything else going on in the world (👀). DeepSeek upended several things-we-thought-we-knew about the bleeding edge of AI research, and as such, earned the attention it got.
But I’m not here to talk about DeepSeek. You’ve heard enough about that elsewhere. Instead, what I want to do is use the opportunity to ask: what priors need updating from the past year about the bleeding edge of AI capability? I have a few:
Reasoning models
Chain of thought
“Research” models
Model distillation
Pre-training vs. inference-time compute
Dramatic decline in the costs of pre-training
There’s no way I can cover all of this in a single issue, so expect more from me on this the next time I write. Let’s dive in.
Reasoning Models and Chain-of-Thought
Since it came out, I have been using o1, which is the first model that OpenAI classified as a ‘reasoning model’. o1 is not the only reasoning model; DeepSeek R1 has gotten a ton of press of late, Gemini has one, etc.
On some level, cool, I get it, there is some secret sauce happening that helps it think critically:
Reasoning models, like OpenAI o1 and o3-mini, are new large language models trained with reinforcement learning to perform complex reasoning. Reasoning models think before they answer, producing a long internal chain of thought before responding to the user. Reasoning models excel in complex problem solving, coding, scientific reasoning, and multi-step planning for agentic workflows.
But…honestly that doesn’t help me that much. It’s too hand-wave-y for me. Fortunately, the docs go deeper, providing some guidance for how to think about what is happening under the hood, how to prompt a reasoning model differently than a ‘standard’ LLM, and how to adjust the ‘juice’ (compute cycles) spent on a response. These docs do feel helpful from a mental model perspective and give you what you need as a user to interact with the model. But…I still feel fairly unsatisfied.
I’ve gone through and read a bunch of the original research. Take a read of this paper, for example—the paper I most often see cited when thinking about CoT. Read the examples of chain-of-thought prompting. I’ll wait.
I mean … isn’t this freaking obvious? Use RLHF and COT prompting and magically you get a model that can reason better?
Anyway, after spending hours trying to get to some kind of ground truth here, here’s where I’m at:
I think the designation “reasoning model” is mostly a marketing term, although one that does represent higher performance on certain reasoning-oriented benchmarks.
CoT is one key strategy of reasoning models. Both in the RHLF layer, but also in the productization of the model. There is a lot of secret sauce included here, where aspects of the approach are obfuscated for (IMO) commercial reasons.
Another key strategy is simply using more inference-time compute.
I’m sure that there is more that I’m missing here. But that seems like the basics of it. The idea that there are two “tracks” for models currently—one for ‘standard’ LLMs and another for ‘reasoning models’ seems…kind of silly honestly. Why would I ever want to use intelligence that doesn’t ‘reason’? Why wouldn’t we just incorporate these techniques into every model moving forwards? Maybe that’s the plan, but the current landscape feels very muddled.
“Research” Mode
I haven’t yet used o1-pro or o3-pro. But Tyler Cowen is not usually this gushy:
In an economics test, or any other kind of naturally occurring knowledge test I can think of, it would beat all of you (and me).
Its rate of hallucination is far below what you are used to from other LLMs.
Yes, it does cost $200 a month. It is worth that sum to converse with the smartest entity yet devised. I use it every day, many times. I don’t mind that it takes some time to answer my questions, because I have plenty to do in the meantime.
I also would add that if you are not familiar with o1 pro, your observations about the shortcomings of AI models should be discounted rather severely. And o3 pro is due soon, presumably it will be better yet.
I take Tyler’s opinion here very seriously and the benchmarks are truly impressive.
Apparently what is happening here—primarily—to produce these results is that there is significantly greater inference-time compute being dedicated to the response. It’s more of a batch-based interaction, sometimes taking 5-30 minutes, vs. a conversational interaction. The other major improvement is the native ability to use both a web browser and Python, although this is not the first time models have had this capability.
Here’s another overview, with more detail, of the experience of generating a report via research mode. Very interesting.
Honestly, it’s the time-on-task, more than the $200/month price tag, that is a limitation for me. If you can’t give me an answer to something reasonably quickly, I’ve unfortunately had to move on in my day…and likely assign the deeper task to an actual human. I can understand why this might be different for an economics professor, but I have a hard time imagining how to make this fit into my current life. Maybe I am being insufficiently creative.
I’ve officially updated my mental model—apparently hallucination and lack of citations are just not a problem in this world, which makes me think that they were also just a temporary speed bump on the overall path to highly effective AI.
This is one of the most clear examples of the shift from pre-training to inference-time compute.
Model Distillation
From Ben Thompson:
Distillation is a means of extracting understanding from another model; you can send inputs to the teacher model and record the outputs, and use that to train the student model. This is how you get models like GPT-4 Turbo from GPT-4. Distillation is easier for a company to do on its own models, because they have full access, but you can still do distillation in a somewhat more unwieldy way via API, or even, if you get creative, via chat clients.
Distillation obviously violates the terms of service of various models, but the only way to stop it is to actually cut off access, via IP banning, rate limiting, etc. It’s assumed to be widespread in terms of model training, and is why there are an ever-increasing number of models converging on GPT-
4oquality. This doesn’t mean that we know for a fact that DeepSeek distilled4oor Claude, but frankly, it would be odd if they didn’t.
This is a fascinating fact that I’m not sure I fully appreciated a year ago when thinking about the competitive dynamics in the model space. It seems that distillation is quite effective, meaning that the cost involved for training anything but the leading edge model can go down significantly, whereas the cost of training a leading edge model likely cannot (there is no “teacher” model to distill from!). This makes a hard strategic position—that of the leading-edge model provider—even harder.
Relatedly, Sam Altman recently came out with his most recent blog post. While somewhat meandering, you can almost read his “three observations” as an attempt to explain this strategic position:
1. The intelligence of an AI model roughly equals the log of the resources used to train and run it. These resources are chiefly training compute, data, and inference compute. It appears that you can spend arbitrary amounts of money and get continuous and predictable gains; the scaling laws that predict this are accurate over many orders of magnitude.
2. The cost to use a given level of AI falls about 10x every 12 months, and lower prices lead to much more use. You can see this in the token cost from GPT-4 in early 2023 to GPT-4o in mid-2024, where the price per token dropped about 150x in that time period. Moore’s law changed the world at 2x every 18 months; this is unbelievably stronger.
3. The socioeconomic value of linearly increasing intelligence is super-exponential in nature. A consequence of this is that we see no reason for exponentially increasing investment to stop in the near future.
If you want to paint a picture where a leading-edge model provider has a strong strategic moat, these are the things you would have to believe. You have to be so bullish on Altman’s third point that you are willing to fund the exponentially-increasing costs of compute and believe that the tax from followers distilling your models is worth paying because the leading edge is just that valuable.
===
I hope you found the above useful. To be clear, I write all of it with some level of vulnerability. I am not an AI expert; my goal here is just to synthesize and translate. In my next issue I’d like to hit another couple of topics and then bring it back around to how I believe all of these AI trends will likely impact analytics / data engineering. I think we have a lot of reasons to be optimistic!
Until then..!
Tristan
vfdvdf
xasdcdsa