
America's Next Topological Model
Gardening, not architecture

...when you build a thing you cannot merely build that thing in isolation, but must also repair the world around it, and within it, so that the larger world at that one place becomes more coherent, and more whole; and the thing which you make takes its place in the web of nature, as you make it.”
― Christopher W. Alexander, A Pattern Language

Data teams have learned a lot from software teams, and will certainly learn much more, but one area we cannot emulate our software engineering peers is organizational topology. This is due to the breadth and intricacy of data’s involvement across the org. While it's reasonable for a software engineer on a given team to go an entire stint at a company without interacting with, say, customer support, or perhaps finance (the specific departments may vary), this is generally untrue of data teams. Everybody is hooked into data, and the ur-stakeholder is not just the product, but the total functioning of the organization itself. For example, revenue may be nominally a finance metric, but it’s critical for the entire organization. An embedded product analyst will likely interact with everyone from marketing operations to the CEO.
Put another way, that means instead of making arbitrary divisions based on standard business areas, focusing on greater alignment between the organization's knowledge graph and people graph. Far from shipping the org chart, this is an alignment that moves in both directions, organizing people around the ways data flows as much as organizing data projects around groups of people.
🎉 It’s the most wonderful time of the year (for analytics engineers)! Coalesce 2023 is jumping off October 16-19 with in-person events in San Diego, Sydney, and London as well as our famous virtual vibes. Register now to be part of the data world’s most loved conference 🤗.
Let's consider a simplified example data team to bring this out of the abstract:
Product analyst: relies heavily on click event data to run experiments.
Financial analyst: relies on a shared set of SaaS inputs and your transactional database to build a revenue report.
Marketing analyst: relies on a shared set of SaaS inputs and your transactional database to build a customer 360 report.

A common pattern to handle this setup today would be 'hub and spoke', using a central team to land and stage the data, then have the embeds build on top of this in separate areas of a shared project or in separate projects that import the central project (and potentially others).
There are problems with both shared and separate projects for this approach though:
If sharing a project, the size and complexities can slow down development pace and unnecessarily couple separate workflows.
If splitting up projects with historically existent tooling, you created a very brittle and complex set of dependencies that required difficult manual maintenance.
Often their outputs drift into silos as well due to the difficulties in unifying the separated workflows.
Due to these issues, we end up making concessions based on the constraints of our tools and organization, not necessarily what makes the most sense for the data and people.
For instance, click event data tends to be complex and voluminous. Wouldn't it make more sense for the product analyst to own the entire transformation vertical for that data source? Why arbitrarily force them to go to a separate team to, say, unnest a JSON field differently, and all the ensuing downtime that handoff would take?
On the other hand, our finance and marketing analysts are actually working from a shared set of components, but they are better served to separate past a certain level to simplify their projects and allow independent development.
We also need to consider that consumers expect to combine elements from all of these groups into a kaleidoscope of metrics. These teams cannot be siloed from each other, or each other’s stakeholders. Changing the definition of revenue impacts all the other data groups and the entire organization.
Something like the below would make a lot more sense for our organization:
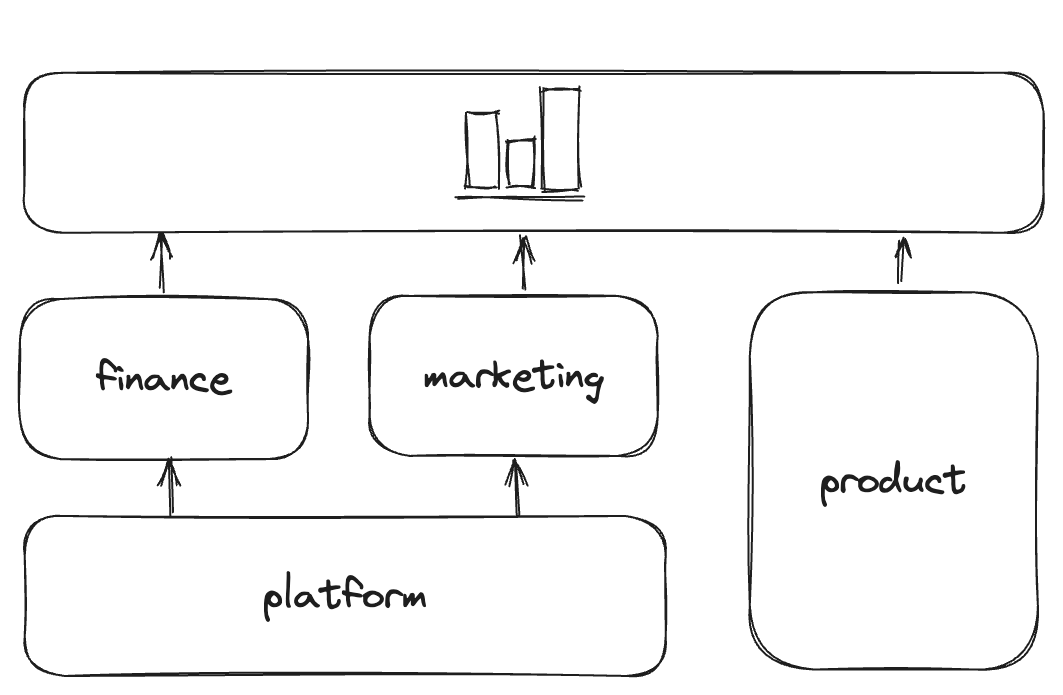
To achieve this at scale though, we need the shape, data types, and columns to be stable, tested, and versioned. We need ways to reach into other projects, as well as govern what can be reached. We need tooling that allows us to treat the inputs and outputs of our projects like APIs, with the projects as transformational nodes in a (meta)DAG.
Water can be a useful metaphor for this kind of emergent DAG design, particularly where data flows are concerned. I believe that the more we can let data flow like water, along paths of least resistance, the more effectively we manage it. Like water, the less we arbitrarily, rigidly move and split data, the more it can form vibrant watersheds and ecosystems in the areas it naturally flows to, providing more abundant value.

If you could remove the solid architectures placed around your data and let it flow freely, what shapes and grooves would it form?
Put another way, if you could structure your projects and teams in any way, without technical constraints, what would that look like?
These questions, and the tools and patterns that form the answer to them, are the underpinnings of data mesh. There’s a lot of complex language and heated opinion surrounding this paradigm, but I think it can be summed up quite simply by my favorite card from Brian Eno’s Oblique Strategies:

Given tooling that allows us to treat our data inputs and outputs as APIs, how can we become stewards of our data as a vibrant ecosystem, rather than architects devising clever towers. As this tooling prepares to enter the mainstream for analytics engineers, it’s a chance for us to strip away complexity and find the simple, natural heart of the data mesh pattern. Understanding basic data mesh principles, we can nurture more productive, interesting, and intuitive data platforms.
People cannot live in nature without changing it...this is true of all creatures; they depend upon nature, and they change it. What we call nature is, in a sense, the sum of the changes made by all the various creatures and natural forces in their intricate actions and influences upon each other and upon their places. Because of the woodpeckers, nature is different from what it would be without them. It is different also because of the borers and ants that live in tree trunks, and because of the bacteria that live in the soil under the trees. The making of these differences is the making of the world.
— Wendell Berry
Elsewhere on the massive multimedia mesh
Abhi is always a fountain of wisdom, he’s written one of the most popular issues of this very newsletter before! Here he is in a wide-ranging interview full of great ideas as always.
Vicki Boykis brings her legendary thoroughness and clarity to bear on embeddings, perhaps the most important and hand-waved-over part of the LLM use-cases folks reach for these days (chat-your-docs etc). Highly recommended.
This could be called ‘Everything I wish I knew about A/B testing, but was afraid to ask’. Jonathan Fulton is at experimentation platform Eppo, so he knows this stuff deeply. Comprehensive and thorough, with a smooth gradient of complexity as it progresses so you can jump off if it gets deeper than you need (also true of Vicki’s work above). If, like me, you come from a non-traditional background (I studied music in college 🤷♀️) this kind of generous knowledge sharing is vital. Great stuff!