
Apache Arrow: the Future of Data Science? Data Science in Academia. Web Scraping. [DSR #105]

The Lego map at the end of this article really has me thinking about 3D printing. Has anyone 3D printed a bar graph before? Let me know if you’ve played around with physical data viz.
- Tristan
❤️ Want to support us? Forward this email to three friends!
🚀 Forwarded this from a friend? Sign up to the Data Science Roundup here.
Required Reading
Apache Arrow and the "10 Things I Hate About pandas"
In this post I hope to explain as concisely as I can some of the key problems with pandas’s internals and how I’ve been steadily planning and building pragmatic, working solutions for them.
Wes McKinney knows a thing or two about pandas—he started writing it in his spare time almost a decade ago and continues to be deeply involved. In this post, he tells a story that starts with pandas but goes further, leading eventually to him pulling together a coalition around an Apache project called Arrow.
The motivating force behind the story has been performance at scale. Wes talks about how a bunch of design decisions in pandas still plague the project today. Arrow attempts to provide a “columnar data middleware” that provides zero-copy access between tools like Impala, Kudu, Spark, and Parquet. In his own words: “I strongly feel that Arrow is a key technology for the next generation of data science tools.”
I mentioned Arrow here almost two years ago at this point when the project first started. It’s made a ton of headway since then, and it’s well worth checking out if it’s new to you.
This Week's Top Posts
Learning git is Not Enough: Becoming a Data Scientist After a Science PhD
Some advice about moving into data science after completing a PhD in a natural science from someone who did. My favorite quote is from a section titled “Why tech companies shouldn’t hire you”:
[Tech firms] know that, left alone, a typical science PhD cannot build robust, complex software systems. More fundamentally, science PhDs are often ignorant about the basic tools and conventions of collaborative software development.
Real talk 😰
The Academic Ecosystem is Damaged
In a survey of more than 2,000 psychologists, Leslie John from Harvard Business School discovered that more than 50% of psychologists had waited to decide whether to collect more data until they had checked the significance of their results, thereby allowing them to wait until their hypotheses are confirmed.
☹️
Using Scrapy to Build your Own Dataset
Working on your own projects, solving a problem from beginning to end, is the best way to build your data science skills. That very frequently starts with web scraping to collect your initial dataset. Scrapy, a Python library, is an extremely capable library for building crawlers, and this tutorial is 👌.
New Theory Cracks Open the Black Box of Deep Learning
A new idea is helping to explain the puzzling success of today’s artificial-intelligence algorithms — and might also explain how human brains learn. From Geoff Hinton:
It’s extremely interesting. I have to listen to it another 10,000 times to really understand it, but it’s very rare nowadays to hear a talk with a really original idea in it that may be the answer to a really major puzzle.
www.quantamagazine.org • Share
What is the yearly risk of another Harvey-level flood in Houston?
You’ve likely heard that the flooding in Houston following Hurricane Harvey is reportedly a 500-year or even 1000-year flood event. You’ve perhaps also heard that this is the third 500-year flood that Houston has experienced in a three-year span, which calls into serious question the usefulness or accuracy of the “500-year flood” designation. This made me wonder: what’s our actual best estimate of the yearly risk for a Harvey-level flood, according to the data? That is the question I will attempt to answer here.
Impressive work, excellent writeup 👍👍

When Are Citi Bikes Faster Than Taxis in New York City?
Over 50% of peak hour taxi trips would be faster as Citi Bike rides, and taxis are only getting slower.
Excellent analysis. Useful.
Why SQL is beating NoSQL, and what this means for the future of data
After years of being left for dead, SQL today is making a comeback. How come? And what effect will this have on the data community?
IMO this is a bit of a flawed perspective–both SQL and NoSQL have a role to play in current and future data processing. However, it also presents useful history of the industry that is entirely worthwhile if you’re not familiar.
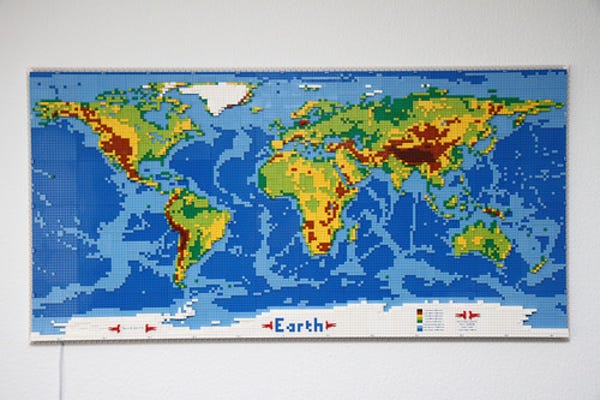
Data viz of the week
Data viz can by physical, too! This is an elevation map of the world in Legos. Ever tried 3D printing one of your KPIs for next quarter?
Thanks to our sponsors!
Fishtown Analytics: Analytics Consulting for Startups
At Fishtown Analytics, we work with venture-funded startups to implement Redshift, Snowflake, Mode Analytics, and Looker. Want advanced analytics without needing to hire an entire data team? Let’s chat.
Stitch: Simple, Powerful ETL Built for Developers
Developers shouldn’t have to write ETL scripts. Consolidate your data in minutes. No API maintenance, scripting, cron jobs, or JSON wrangling required.
The internet's most useful data science articles. Curated with ❤️ by Tristan Handy.
If you don't want these updates anymore, please unsubscribe here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue
915 Spring Garden St., Suite 500, Philadelphia, PA 19123