
Becoming an ML Engineer, Screwing up SQL, & a Great Intro to SVM [DSR #100]

Issue # 100 sees the Data Science Roundup community at over 7,000 strong. Thanks for inviting us into your inbox every week :)
- Tristan
❤️ Want to support us? Forward this email to three friends!
🚀 Forwarded this from a friend? Sign up to the Data Science Roundup here.
Two Posts You Can't Miss
I love this article. Working in data science or distributed systems or any field at all where state-of-the-art is changing so constantly, it is a constant struggle to stay current. How do you keep up without completely forgoing any sense of a personal life?
Julia Evans crowdsourced suggestions on Twitter and came back with a ton of great stuff:
i’m on a small team so I read & reread every pull request that comes in until I understand the problem & solution fully
Reading source of what I use is a big one for me. Understand what it does internally but mainly why it does it a certain way.
Whenever I have to look something up for troubleshooting, I go a little deeper or broader than strictly necessary.
Much more in the article. If you’re serious about skill acquisition, you need to make sure that have you the space to actually pursue that within the context of your actual work. If your current job doesn’t support this, consider changing.
How To Become A Machine Learning Engineer
This post blew up on Hacker Noon this week. Excellent curriculum for aspiring ML engineers.
We will walk you through all the aspects of machine learning from simple linear regressions to the latest neural networks, and you will learn not only how to use them but also how to build them from scratch.
This Week's Top Posts
Dangerous Subtleties of JOINs in SQL
It’s so easy to screw up your SQL, even when the dataset is seemingly straightforward. This article discusses two very common errors analysts make in their join logic, and they’re ones you’ve almost definitely made yourself at some point.
While we’re on the topic of common SQL errors, take a look at this article, from way back in 2009, on more ways you can screw up your queries.
This is why we built testing into dbt. If you assert things to be true about your data (not-null and unique fields, referential integrity, etc.), you can begin operating on your data with a high degree of confidence.
Support Vector Machines Tutorial
If you’re not familiar with SVM, kernels, or how to fit hyperplanes, this article is an excellent walkthrough, complete with both math and explanatory viz. High quality.
Data Viz Project | A Collection of data visualizations to get inspired and finding the right type.
If you find yourself defaulting to line graphs like I do, try making this site a part of your regular workflow. It’s an impressive collection of visualizations that lends itself to browsing. See what inspires you!
R Exercises: Answer Probability Questions with Simulation
I love this site: R Exercises has over 1,000 exercises on a huge variety of topics along with their answers.
We’ve been increasingly helping clients out with hiring / interviewing, and we’ve had to think through our own interviewing process as we’ve grown our own team. We’ve come to strongly believe that assessments given as a part of the interview process are critical—not to assess a particular technical skill, but to attempt to get at the overall problem solving process a candidate employs. We’ve built a rudimentary but effective SQL-based test we’re giving to candidates to great effect.
If R is a part of your toolset, this library is a wonderful resource for pulling together your own interview assessment. Or, of course, sharpening your own skills 😊

Analyzing Cryptocurrency Markets Using Python
This is the best article I’ve seen on cryptocurrency analysis. The author goes through a step-by-step process of setting up a Python environment and then does some novel and useful analyses at the end. The fact that prices of different currencies were largely uncorrelated in 2016 but have become correlated in 2017 is perhaps unsurprising, but the visualization is striking nonetheless. Tulip prices were also highly correlated with one another in 1637.
blog.patricktriest.com • Share
An Open Letter to the United Nations Convention on Certain Conventional Weapons
It’s fascinating working in a space where advances are simultaneously mundane (recognize your friends slightly better in Instagram photos!) and legitimately terrifying (build autonomous killer robots that recognize your friends slightly better!). This group of Very Smart People believes that the UN must do something to prevent the latter.
Hysteria or realism—what do you think?
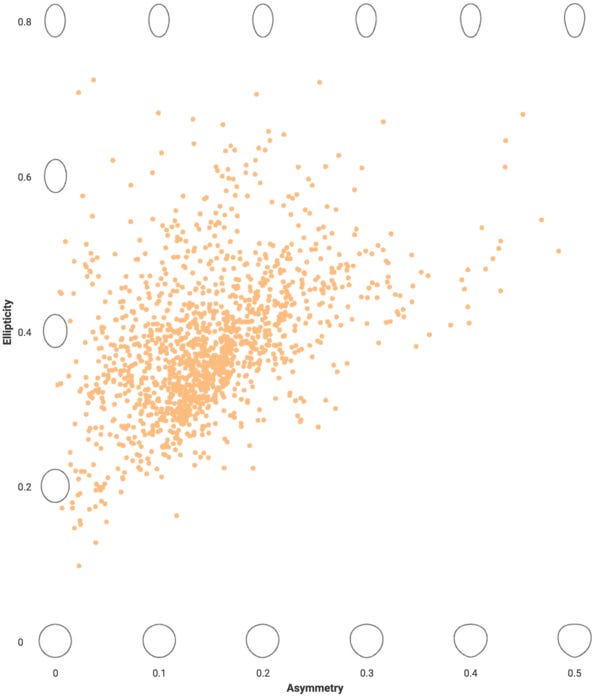
Data viz of the week
This is just one of a whole narrative of very effective interactive viz from a Science article Cracking the Mystery of Egg Shape. I particularly liked the shapes present on the axes here to help you visualize the coefficients.
Thanks to our sponsors!
Fishtown Analytics: Analytics Consulting for Startups
At Fishtown Analytics, we work with venture-funded startups to implement Redshift, Snowflake, Mode Analytics, and Looker. Want advanced analytics without needing to hire an entire data team? Let’s chat.
Stitch: Simple, Powerful ETL Built for Developers
Developers shouldn’t have to write ETL scripts. Consolidate your data in minutes. No API maintenance, scripting, cron jobs, or JSON wrangling required.
The internet's most useful data science articles. Curated with ❤️ by Tristan Handy.
If you don't want these updates anymore, please unsubscribe here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue
915 Spring Garden St., Suite 500, Philadelphia, PA 19123