
Big Data is Dead.
Plus: Directing the attention of large organizations.
This is the week that everyone else found out about DuckDB.
Duck was already popular in the narrow confines of Data Twitter…being maybe the single favorite technology of the past year with that crew. But this past week MotherDuck CEO Jordan Tigani authored a post that jumped to the top of HN—Big Data Is Dead—and now everyone’s on the train. Reddit asks “What’s the hype around DuckDB?” and got 92 comments. I won’t attempt to link to everything that’s been written since, but it’s fair to say that this duck has officially flown the coop.
Before saying more, I do want to be up-front about my affiliation: I’m both an investor in MotherDuck and an unabashed supporter of both Jordan and DuckDB. But it’s hard to read this post and not feel like you’re reading something really special. Jordan’s time running BigQuery means that he just knows more about the shape of cloud data warehouses and their usage patterns than almost any human alive, and even if you don’t care at all about DuckDB, you’ll learn a ton from the post. Here’s a great example:
A huge percentage of the data that gets processed is less than 24 hours old. By the time data gets to be a week old, it is probably 20 times less likely to be queried than from the most recent day. After a month, data mostly just sits there. Historical data tends to be queries infrequently, perhaps when someone is running a rare report.
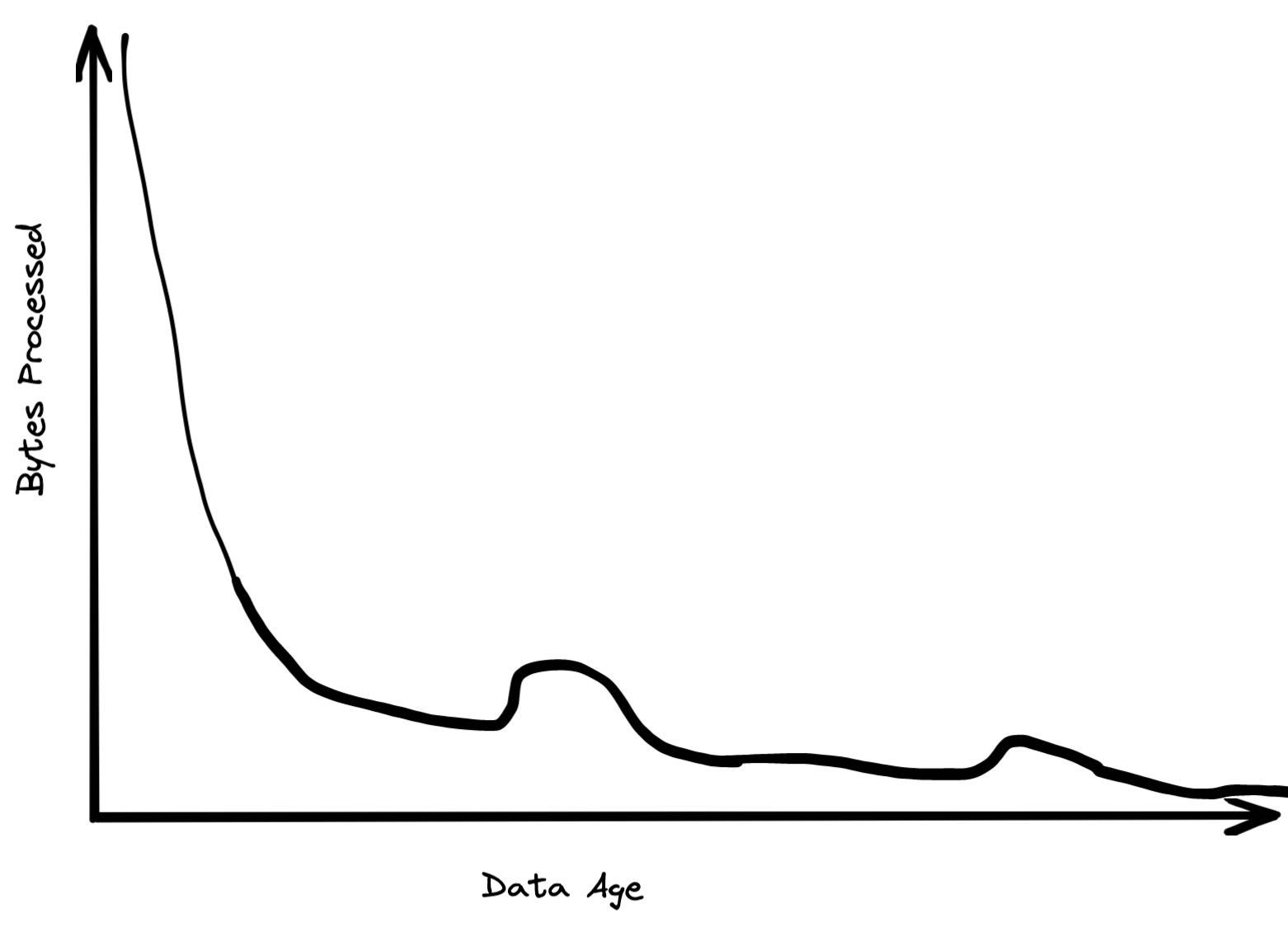
Data storage age patterns are a lot flatter. While a lot of data gets discarded pretty quickly, a lot of data just gets appended to the end of tables. The most recent year might only have 30% of the data but 99% of data accesses. The most recent month might have 5% of data but 80% of data accesses.
That’s just…useful to know. I wish the large database vendors would talk about this stuff themselves, as these types of insights are invaluable when thinking about data product design, data model design, or cost analysis. (Maybe they do and I’m not aware?)
Anyway…the whole post is incredibly valuable and it’s written by one of the most knowledgeable humans in our industry. You should read it. My personal experience is roughly similar; most of the ~75 companies I’ve personally worked with have had small-to-medium data. Even dbt Labs, a digital native company with a product that has a lot of usage, don’t have huge data… We do have reasonably-sized event tables, but very rarely do we need to process more than a TB at a time.
—
Insight must emerge from within the organization.
Beautiful and salient as ever, Stephen tells a story about how we direct our attention—as individuals and as organizations—and how we often misattribute failing to pay attention for failing to see. This hits hard for me, for what I have been very good at in my career (in the post’s metaphor) is teaching other people to see. I have been far less successful at helping others direct their attention.
This shows up inside of our company, and has basically forever. This section of the post is where it all comes together:
The question, then, is how does one prevent the gaze of an organization (…) from becoming listless and glancing past the mortal threats staring directly at them?
If the organization cannot see, it needs better eyes. It needs to sharpen the mechanical processes that collect and make basic sense of its environment. It needs its sensory input to be fast, comprehensive, and reliable.
If the organization cannot pay attention, it needs executive function: top-down processes that select for salient stimuli, while suppressing irrelevant ones. It must discriminate between what matters and what doesn’t. It needs better focus.
The hard part (for me) about forcing an organization to direct attention is that this inherently reduces individual agency:
To limit sight and direct attention is to own someone else’s world.
As a one-time data practitioner and now as a leader of a company of 400 people, these two things feel conflicted. I want to preserve the agency and autonomy of every one of these 400 humans, but I also want us all to focus on a shared set of priorities.
My default tendency on assuming the CEO seat in 2016 was to assume that everyone will figure everything out for themselves and consensus will emerge. At scale, this turns out to not be a successful strategy (lol), and I have learned to be better at this over the years. But it’s still probably my weakest area as a leader. It consistently shows up in every one of my annual 360’s.
My guess is that if you’re on a similar journey, from data practitioner to leader, that you may struggle with this as well. You shouldn’t take any advice from me on this subject, but I will tell you what I try to focus on.
The tension above could be reframed as the tension between the individual and the group. In any human group, there is tension between the identities of the individuals and the identity of the group. But without the group, no human can achieve to their fullest potential—none of us ever achieves anything meaningful on our own.
So: you, as a leader, are directing the attention of the group just enough for it to cohere, and thereby enabling each individual to perform at the top of their game. It’s a hard ridgeline to navigate, but when you do it just right the results are magical.
—
Benn argues that for the propaganda value of data teams:
The point of the dashboard isn’t to make decisions. It’s to keep the mission at the front of everyone’s mind. It’s to make sure everyone sees the impact of the work they’re doing. It’s to rally a company around a sales team pushing through their final sprint. It’s to use data, not to tell detached truths, but to connect with people emotionally, to make them trust the process, and to help them believe, despite all the odds stacked against startups, that theirs can go out and hit a hard six.
This is not wrong. I’m increasingly finding opportunities to do the same. Even things as simple as choosing what dashboards get sent to what channels on what cadence is an act of team alignment, motivation, and agenda-setting.
—
I added a new term to my lexicon this week: exploratory programming. Maybe you knew it; it even has a Wikipedia page.
This has been a word that I’ve needed for years now. It’s clear that some programming is useful for building production systems and some programming is useful for exploring hypotheses (this fits just as well for a Jupyter notebook as a hackathon demo). What I didn’t realize was how much history and thought there has been around the latter…I always just thought of it as “hacky code” but this is a much better mental frame.
This is a really good read Tristan.
The paragraph that stood out for me was this:
"My default tendency on assuming the CEO seat in 2016 was to assume that everyone will figure everything out for themselves and consensus will emerge. At scale, this turns out to not be a successful strategy (lol), and I have learned to be better at this over the years. But it’s still probably my weakest area as a leader. It consistently shows up in every one of my annual 360’s."
This is a problem I face frequently as a junior data analyst presenting the result of my analysis and reports. It's definitely at a smaller scale than yours. Many times I feel like I would rather let the users have the interactive charts and decide for themselves what it means to them. After all, I'm not the marketing expert, they are. So, drawing conclusions from the data may be far-fetched or short-sighted. And I could be narrowing down all the stories the data has to tell into just one. I have started to include my own insights in the reports, but finding the balance between delivering insights and letting other people use their thinking is still a massive work in progress