
Breakthrough moments of insight. The metadata quilt. A funeral for a friend.
Storytellers and system builders. A final word on contracts.
If you’re going to be at Coalesce in New Orleans next week, shoot me a message on Slack! I’d love to meet up :D Seriously excited to see so many of you…
Enjoy the issue!
- Tristan
Here’s a fun post: Jennifer Lanni in Science writes about why she teaches her students about scientific failure. In it, she talks about pushing students, used to lab environments with predictable results, to see things they don’t expect:
After a solid hour of struggle and some leading questions on my part, one student finally spoke up. “It doesn’t make sense. The bands look the same size, but the proteins should be different sizes.” Hallelujah! A student had stepped back from seeing what they expected to see and described what the data actually showed.
This paragraph resonated so hard with me. I’ve had the opportunity to train some truly fantastic recent college grads on how to see the world through data and, through that, have had the opportunity to relive my own early-career experiences.
What seems completely universal is that at some point there is just this period of intense struggle, of staring at a screen, of questioning everything—your data, your understanding of the system you’re working with, your own abilities… And then—after hopefully not too many hours!—you hit that breakthrough. Something clicked. You’re not quite sure how you got there, but you see the problem differently and now things make sense.
What’s so magical to me about the first time a data professional experiences this moment is that it is absolutely career-defining. The first time you have this experience, your confidence in yourself and your command of your work just changes in an instant. And it becomes this high that you want to keep reaching for again and again.
Shepherding new folks to this moment and then celebrating with them on the other side of it is just tremendously rewarding.
Do you have a word for this breakthrough moment? Have you experienced it yourself?
Whoah…this post is awesome. Penned by the head of BI at Roche, Omar Khawaja, it’s probably the best post out there on the overlapping quilt of metadata-related product categories. The diagram that brings the whole thing together is here:
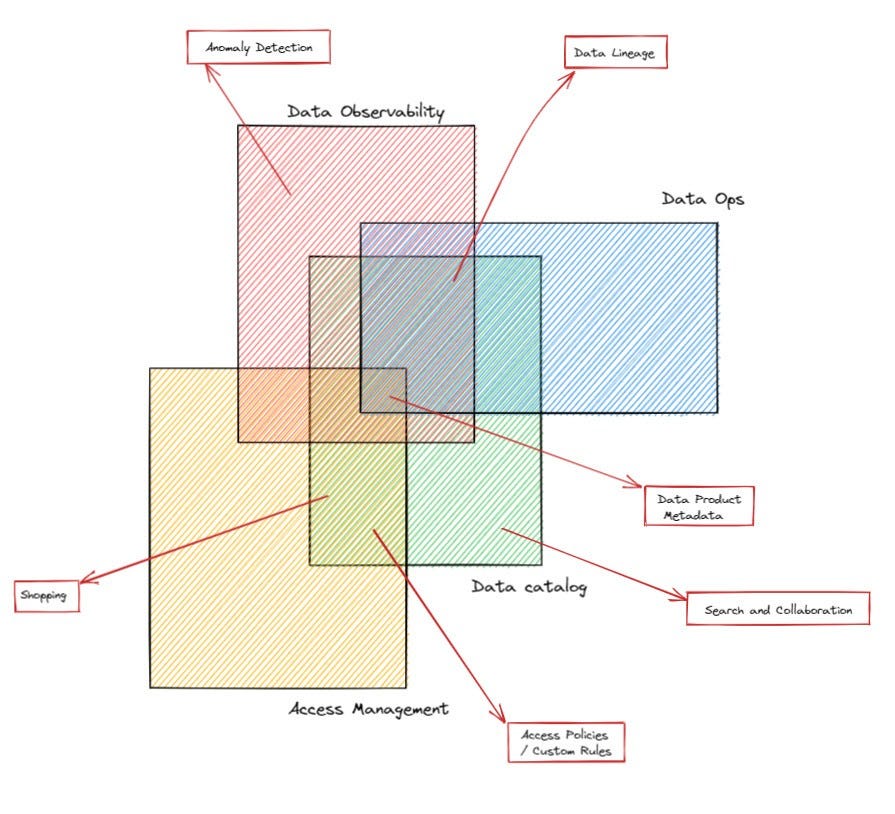
The point the author is making is that all of these product categories have an overlapping set of features, which is what makes it so hard to reason about them (they are not MECE!). I think lineage is a great illustration: look at the diagram above. Lineage is a required featureset of three out of the four categories.
In An Engineer’s Guide to Data Contracts, Adrian Kreuziger outlines how Convoy creates producer-enforced data contracts. It’s a long and technical read, and it’s exactly what the ecosystem needed on this topic IMO. This is the post that takes the topic from high-level to specific, where conversations can become much more grounded.
There is so much to like in the article. Here’s one of my favorite lines:
Data contracts must be enforced at the producer level. If there's nothing enforcing a contract on the producer side, you don't have a contract. That’s a handshake agreement at best, and as the old saying goes: "A Verbal Contract Isn't Worth the Paper It's Written On".
Love this. We had a really fun dbt Community Zoom hangout on the topic of contracts recently which introduced me to the vernacular of “producer-led” and “consumer-led” contracts. I could not agree more that the ideal solution would be producer-led.
The main question I leave this post with: how do I scale this down in complexity for a smaller data team / SWE team? If I want to think about producer-led contracts with a data team of 3 analytics engineers and 12 SWEs, is that achievable?
To that end, David shares some thinking on how to do this in a lightweight way. Perfect? No. Achievable at small team sizes? More likely. This post introduced me to Reflekt:
Reflekt enables Data, Engineering, and Product teams to:
Define tracking plans as
code(see supported tracking plans).Manage and update tracking plans using version control and CI/CD.
Automagically build a dbt package that models the data for tracking plan events for use in a dbt project. Reflekt dbt packages include:
Cool!
Ok, I’ve officially written enough on this topic for now. Thanks Adrian and David for continuing to push forward my understanding on what I think will be an incredibly important topic for the coming years of the MDS.
Well, it was finally our turn. After Benn hypothesized the end of Snowflake and then Fivetran, I knew dbt was not long for this world. It was a lovely funeral—most of us never get to attend our own—and dare I say, almost reverent.
The eulogy went something like this. The year is 2030. While dbt started out simple and elegant, as time went on, it tried to do ever-more. Complexity increased and developer experience degraded. Eventually, the shine wore off and the community migrated elsewhere.
This, dear reader, is not an impossible-to-imagine bogeyman. Our mission as dbt Labs is to empower data practitioners to create and disseminate knowledge—a lofty goal to be sure! And we have a lot of work left to do to get there. So there is no world in which we just rest on our laurels and stop innovating.
The challenge whenever you build a great early product that captures the zeitgeist is to not screw it up. Our task, then, is to continue evolving dbt in support of its mission while keeping that magical developer experience on which everything else has been built.
That is a tall order. But 🤷 I cannot adequately express how uninterested I am in making average things. Fortunately (😅) Benn doesn’t actually seem to believe the thought exercise is a likely outcome:
Despite it all, dbt Labs’ unforgettable start probably isn’t a warning, but a precursor to unforgettable future. No matter how many words we write about it, the final story about dbt is succinct: It’s a damned good product, and it’s not just pretty to think so.
Morgan Krey writes about storytellers and system builders:
What I have found is that there are really only two data roles: System Builders and Storytellers. All of the other titles, from Data Scientist to Analytics Engineer, are really just variations of these same two themes, and there’s one simple question to pick a path: do you love building systems, or telling stories? Or, in the famous words of Marie Kondo, what sparks joy?
This is lovely. I’ve always thought of this dichotomy as researchers vs. librarians, but it’s possible that the library metaphor actually complicated rather than simplified.
Arpit’s post on analysis interfaces is solid. I particularly liked the concept of “bring your own interface,” and loved that AirOps got a shout. AirOps is data activation product that focuses on productivity tooling rather than line of business applications (my words not theirs). Notion, Coda, Sheets, Airtable—if this is how you get work done, check it out.
Appreciate the mention and glad that the article resonated. Cheers!