
Complexity: the new analytics frontier
What it's like doing analytics engineering six years on.


dbt turned 6 years old this year. That means there are dbt projects out there chugging along with almost as many years worth of analytics code lovingly layered on by analytics engineers.
Six years ago, we wanted to work with more leverage, that is, spend less time for more impact and scale. Six years ago, we hoped to be able to collaborate on knowledge represented by our data model the same way software engineers collaborate on a complex codebase.
Looking back on these goals today, how did we do?
I’ll write about what I know — the dbt Labs’ internal analytics project. It’s a decent representation of what folks with mature projects should be experiencing today.
It’s a project that is well seasoned: it is several years old, full of analytics engineering best practices, packages and dbt macros goodness. In other words, it should be everything we hoped it would be: high leverage, modular and collaborative.
At the time of this writing, our internal project has a cool 700+ models in it. 43 humans (mostly outside of the data team) have contributed code across 400+ branches, and over 5000 commits to main so far. Every month, our dbt instance now executes 400,000 (yes, four hundred thousand) dbt runs, and this grew 4x in less than 12 months.
Did we achieve more collaboration on an analytics code base? ✅
Did we achieve more leverage through reusable and modular code? ✅
Did we also buy more complexity, resulting in longer maintenance and debugging cycles? Unfortunately, also ✅ 🤓
Turns out the price of enabling people to build a more complex code base is… a more complex codebase, and everything that comes with that.
So we’re here. We made it. We’ve achieved complexity. Now what?
Now… now we do it again. That is, now we build for a whole new suite of challenges that greater analytics complexity brings to the table.
In the next few sections, I’m going to talk about a few hard things I’m seeing as our internal analytics project scales. I so very much want to hear about your own experience if you’ve been working on a dbt project for a few years. What resonates with you? What have I missed?
Why now? Because in about 24 hours, the dbt Labs leadership team is descending on an undisclosed location [insert cheesy comic theme song] to talk about what we’re doing next. And I’d really love to ground that conversation in what working with dbt feels like for you, today :)
Enough preamble. Here’s my take:
1. Troubleshooting at scale is hard
A full refresh of our internal analytics project takes a little over 21 hours. Finding out why this takes so long, how to make it quicker, and then testing those changes, is pretty hard.

Ok, it looks like I’ve got three big bottlenecks here (and a few smaller ones, but this tab isn’t interactive yet so I can’t see them or the details):

Let’s try to find one in our project docs:
And here’s the lineage that depends on my 3 hour long model run:

Let’s say I figure all this out and begin my refactor. Turns out, its an incremental materialization that reads from a very very large source table. 🤨 If every run takes over 3 hours, I’ve got to come up with a way to test my changes without executing the full run. I have two choices:
manually rewrite the query to pull less data, refactor it, and then hope I remember to put it back the way it was; or
know that I should write a custom macro (like below) that will allow dbt to automagically switch to a small segment of the dataset when I’m in development mode AND know that I can change my target environment in my dbt user settings to take advantage of this macro AND have permissions on my dbt project to change my target environment… 😰


You get the idea.
2. New developer onboarding is hard
Remember how I said a full refresh of our internal project takes 21 odd hours?
That’s exactly how long someone will need to wait the first time they fire off a dbt run to make a copy of production data in their user environment.
Wait, what? 🥺
Let’s back up. dbt does this thing where it allows your developers the ability to transform their data in their own personal environment (exactly like working on code on a branch!). That way you don’t have several people trying out transformations on the same data set at the same time and getting all sorts of conflicts and collisions. Neat, eh?

But first you’ve got to get some data into that environment (usually it’s a separate warehouse schema). Which normally means doing the good ol’ dbt deps, dbt seed and dbt run. On our internal analytics project, those take 1.5 minutes, 2 minutes and 21 hours respectively. 💀
Now, if you’re a snowflake user, you can just clone your production schema into your user environment. But 1) you have to know that option exists and have access to use it and 2) what about everyone else?
Also, when was the last time your computer did 21 hours straight of anything? (other than binge-watching K dramas and installing X Code 👀👀👀👀)
3. Preserving data history + staying idempotent is very very hard
Incremental models and snapshots are the key to preserving history of how your data changes over time. The former is usually used for event data, the latter for snapshots of production tables from your user facing applications, but both have similar goals.
They are not just important for storing history more efficiently and cheaply, but they are the foundational building blocks of being able to say confidently to your stakeholder: “we can roll all of this back and figure out why this number changed, when it changed, and why it changed”.
In other words, this functionality is critical for data and metrics auditability at any large and especially public company.
Sounds great, except the whole point of these features is that data changes. And that means your source data structure changes too. And that means… yup, re-running your incremental models to reflect the changes via a full refresh (yay another 21 hours!) and a growing number of duplicate columns to coalesce in your snapshots.
4. Code ownership at scale is hard
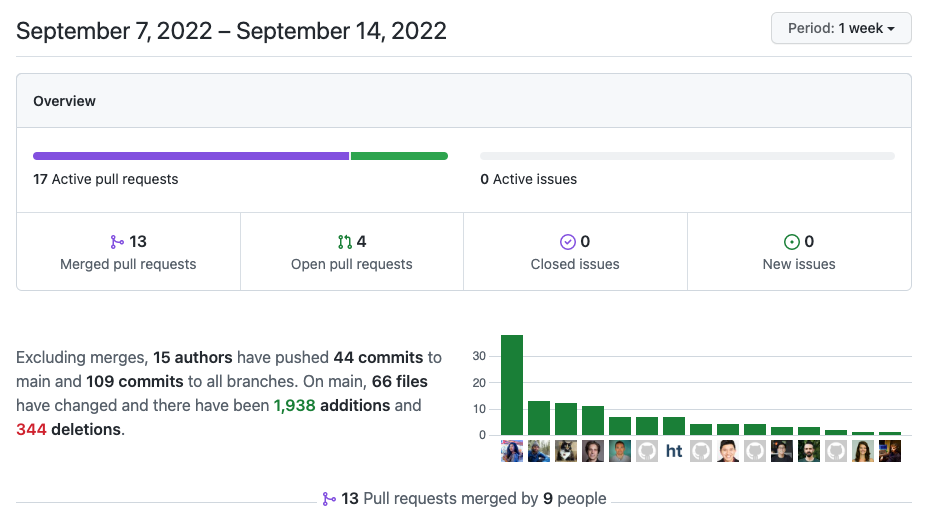
In the last week alone, 13 authors (>30% of the total number of contributors to our internal analytics project EVER) contributed code to the project via 13 pull requests and >100 commits. Why this makes maintenance hard:
If there was a regression somewhere in our project in the last week that caused our weekly (yup, 21-hour-long) full refresh to fail, it would take a long time to identify the specific PR it came from, and trace the impact of rolling back the changes. The earlier in the week the PR was made, the more merge conflict possibilities pop up if we roll back to this older branch.
Permissions are not differentiated enough and anyone who has write access can modify and preview any aspect of the data model. If we wanted to add sensitive data to our project, it would mean exposing the ability to preview the value in the people tables to all 43 contributors and anyone with developer access to the internal analytics project.
These 43 contributors to the data model work across different teams, and care about different parts of the DAG. In order for me as a stakeholder to be alerted on errors in jobs that power models I care about (e.g. those that power Community KPIs), I have to subscribe to failures of the entire job. In other words, anytime the relevant job that happens to also trigger my models fails, I will get an alert and will have to dig in to understand if data I care about is affected.
Folks today solve this problem by splitting code across different repositories (fantastic canonical thread on this on Discourse), but I think that kind of defeats the purpose of what we’re trying to achieve when we say we want to standardize knowledge in one shared data model.
5. Ops/data activation adds more complexity
And finally… if you’ve got a large and complex dbt project and you’re activating your data, you’re adding another entire dimension of complexity to your existing maintenance load.
Let’s imagine that in my exploration of bottlenecks above, I learned via an exposure that the snowplow context splitter is a dependency for important user data that is synced to our CRM via our reverse ETL tool.
Let’s say I wanted to understand how the snowplow data is being used in this export. I open up the relevant sync and learn that we’ve had 18 sync failures consistently on every run. Turns out, some of our input values are too large for the field, and this is failing silently… 😲
The reason? 💀 by notifications.
We already have alerts set up for fatal and major errors (awesome!), and I could make them more granular, but that would also add more noise.
I don’t (yet!) have a way to set up different types of alerts or tests for different reverse ETL scenarios (e.g. making sure value types are syncing as expected and haven’t changed, making sure that the source data is not null, etc…). I also don’t have a good way to set up alerts for things I care about in dbt proper.
The impact of this for me is that I don’t trust my alerting system, and feel like I have to watch all of my jobs to make sure I don’t miss important context without getting overwhelmed by details.
The impact of this for stakeholders I work with is they don’t have visibility into things unless I as their AE know to set up the right alerts and thresholds ahead of time to anticipate most issues — and this will be noisy and erode trust in the entire data process.
So there you have it. These are the 5 things things I’m going to be chewing on as I get on an airplane tomorrow.
What kind of complexity have you been dealing with in your work? What’s keeping you up at night? What do you wish was easier to do today?
Other things that came to mind reading this based on my GitLab experience:
* Doing CI for dbt can be very confusing for new users. Building the mental model of what each step of a CI pipeline is doing and giving the decision tree for whether or not to use a specific test was a huge pain. I wanted it to run automatically but could never get it there (this was pre defer though...)
* PR review was tricky. Does this person need a style or substance review? Do i *really* have enough context to understand the scope of what they're trying to change? Do I *really* know the downstream impact of what the change is?
* How you orchestrate all this is another layer of confusion. Is it possible to have multiple Airflow DAGs that select parts of your dbt DAG but leave you unwittingly not selecting a part of that DAG but it still runs b/c there's an old table in the warehouse and you just don't have tests on that part of it yet? Yes.
* Creating a space where folks outside the team can build models in a less structured way that doesn't affect the rest of the dag (but uses earlier parts of the dag) was a fun challenge. They want to view their work in the BI tool but need "production" to do that!
* How do you surface tests that were built specifically for other ops teams to care about but those folks don't want or need the SQL skill to do their regular job? They just want the output of the failed test to action their work in their tool.
Those are just some of the things that came to mind. But having to worry about those rather than all the other fiddly bits dbt takes care of is much better I'd say :)