
Why data products are critical for business efficiency
If data products are critical data sets, their impact is measured by the breadth of use-cases they support.

You can’t escape the words ‘macroeconomic environment’ these days. The theme of next year in the data space is likely going to be one of efficiency. As you are no doubt in the process of annual planning (as are well all), today’s issue is lightly themed to give you some ideas about how to navigate this shift: from more efficiently operating your data workflows all the way to change communication.
In this issue:
What’s the big deal about data products by Willem Koenders
How we slimmed down slim CI for dbt Cloud by Gabriel Marinho
Demystifying event streams by Charlie Summers
The data informed manifesto by Julie Zhou
Communicating Change by Sean Byrnes
Architecture of a modern startup by Dmitry Kruglov
Enjoy the issue!
-Anna (yes, I’m on Mastodon)
What’s the big deal about data products
by Willem Koenders
This newsletter has talked about data products a whole bunch and this concept isn’t by any means new. That said, I found Willem’s write up on data products to be one of the most clear and compelling I’ve come across.
If you’re still on the fence about the general concept, or just unsure about how to prioritize the right data products without overwhelming your data team, this is the definitive article for you.
Data scientist and business analysts spend a lot of time locating the right data, with data quality issues rearing their ugly head, specifically in any sort of AI model building. In many organizations, the exact same data is actually “cleansed” multiple times by different, separate downstream users, with data remediations not flowing back to the source. [emphasis mine]
This is 👏 exactly 👏 the 👏 right 👏 problem statement. The core issue data products solve in an organization is inefficiency. This isn’t just a matter of not being able to find trustworthy data — it’s a matter of recognizing that some datasets are much more critical than others and that there are features of that dataset that are particularly valuable to surface to your data customers.
Empirically, it turns out that not all Data Domains (and as a result, Data Products) are created equal. If you were able to assess the impact or usability of domains and order them accordingly, you would find that with just a handful of domains you could power the majority of use cases. [emphasis mine]
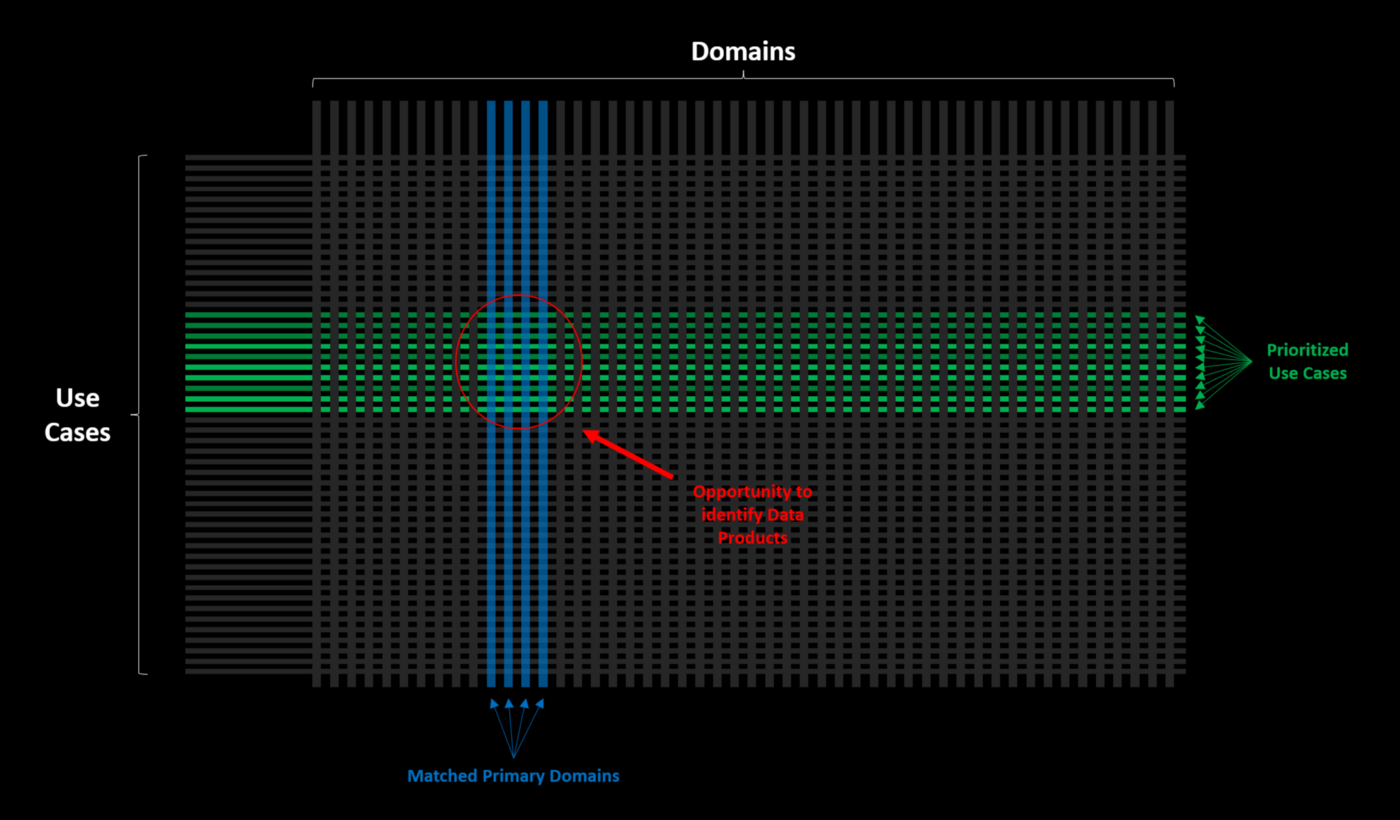
A common example of this I’ve personally come across in many different businesses:
User or Customer dimensions. In other words, this is everything you know about your user and/or customer in one gold standard space easily available to the business. Bonus points if its versioned by time (e.g. state on a given day, end of month, end of quarter etc.). Usually this shows up in a User or Customer 360 dashboard, but it is also likely powering reverse ETL jobs to your CRM and mailing list management software. It is also very likely a common dataset your analytics, finance or operations functions pull from in their analyses of the business. Finally, it is a phenomenal source of features for developing any ML-based model downstream — if you’re doing any sort of customization for the end user of your business’ product, if you’re predicting churn, if you’re forecasting business growth… you get the picture.
What is most clarifying for me in Willem’s article is the fact that downstream use cases are not the data product. The data product is the mutually exclusive, collectively exhaustive dataset that powers many different kinds of use cases.
In other words, data products are critical data, and the impact of working on data products is measured by the breadth of use-cases this critical data serves.
The user/customer dataset I wrote about above could easily have a downstream impact visual that looks like this:

Not only is there intrinsic value created by making this data centrally accessible, but it is also an important impact on the cost (in terms of time and effort) to operate in any of those downstream use-cases.
But there is an effect on the cost side as well. If you consider the same visual above and assume that all downstream systems are business critical, it follows that without a trusted source, completeness and accuracy checks would need to be implemented for each downstream system. However, with a trusted source, the only thing downstream systems need to do, is evidence that their data is consistent with the source they took it from. This can reduce the required number of data quality controls (and the corresponding costs) by a factor of 2 to 5. [emphasis mine]
🎤💥
Elsewhere on the internet…
How we slimmed down slim CI for dbt Cloud
by Gabriel Marinho
This article continues the efficiency theme of today’s Roundup. In this case, Gabriel is talking about efficiency in the development of your data products. The key question — how do you leverage the best of DevOps in your data workflow while adjusting for data-specific gotchas along the way?
CI/CD in the context of data transformation works a little differently than a production software application. The key difference: deploying a production software application doesn’t typically take hours (unless something highly inefficient is going on). Data transformations, on the other hand, can be quite time intensive even with a cloud warehouse because there’s simply so much data being processed (especially in early stages of transformation).
For this reason, data developers often write little shortcuts into their development workflow — testing their changes on only a subset of data. However, when you push your changes up to your version control platform of choice, the best practice to enable true continuous deployment is to test the changes against production — which could be millions of rows.
Gabriel’s article is about how to do this exact thing well. It’s also insight that isn’t specific to dbt Cloud, despite the article title. It’s relevant if you’re deploying your own dbt Core instance as well.
Demystifying event streams
by Charlie Summers
If you missed this talk at Coalesce, or wished for more detail than a live session offers, there’s now a companion blogpost. I highlight this write-up in this issue in particular because this is an incredibly important concept to grasp on the path towards efficiency in your data products.
The general idea is this: event streams don’t have to be a source of constant unpredictable breaking changes for your data team.
The way to avoid this — pair event streams with well defined and designed schemas that tell the outputting microservice what to do with any changes or deviations. (Some may call this data contracts but as a practice this existed way before the term entered the Twittersphere 😉)
Each event output by a microservice is inserted into a single Kafka topic with a well-defined schema. This schema is managed as part of the Kafka Schema Registry. The Schema Registry doesn’t strictly enforce that events comply with the topic’s schema, but any microservice that produces an event that does not comply with the schema will cause downstream failures - a high-priority bug. These bad events are replayed with the correct schema when the microservice is fixed. […]
One very useful feature of the Kafka Schema Registry is it can restrict changes that aren’t compatible with old schema versions. For example, if a data type is changed from an INT to a VARCHAR it will throw an error as the new schema is added.
Beautiful, no? 🧑🍳😙👌
Event schema design (what should the data contract be?) is a deep topic that we can only touch on briefly here. At a high level, we must design for change. A schema will almost always be tweaked and tuned over time as your product changes.
Charlie, I would LOVE to read a deep dive on event schema design best practices sometime. 🤓
The data informed manifesto
by Julie Zhou
I was really intrigued to see this come up on Medium. Julie Zhou is the author of a book I recommend to every new people manager: the making of a manager. It’s a brilliant book that goes into the reality of becoming a people manager — you’re going to feel like you don’t know what you’re doing for a long time (years). The more experience you gain, the more you’ll realize how much more there is to learn — and how to cope with that.
It looks like Julie is now working on a data startup, and this article is a manifesto that (I infer) will guide their development.
A few things that stood out for me as really important guiding principles for building data informed culture that I strongly agree with:
The first step to being data-informed is understanding what data can’t do: give you a purpose. [..] Before you can collect data to help you track what matters, you need to define what actually matters. Information itself is not an evaluation criteria.
In other words, you need to have a clear understanding of the problem you are trying to solve before you collect data or start measuring things.
Setting goals is a skill — you have to practice it to get better.
THIS. I’ve seen folks become a little wary of planning processes because the goals that get set end up being imperfect — macroeconomies change, business environments and direction change, etc. That doesn’t mean we stop setting quantitative goals, it means we learn from what we didn’t account for and improve it in the next iteration.
Everyone has to know the numbers. You cannot outsource a data-informed culture.
This means everyone in your organization, not just everyone on your data or leadership team. If you ask a colleague at random what key business metrics are most important for their business, can they tell you 1) what they are and 2) how are they defined?
Openness to being proven wrong is insufficient. Data-informed teams actively seek out information that might disconfirm their assumptions.
Don’t look for data that confirms your intuition. Look for data that tells you if your intuition is wrong.
I’m very interested to keep an eye on how this startup evolves to help data teams work by these principles more efficiently and effectively.
Communicating Change
by Sean Byrnes
There’s a lot of change in the air right now in organizations. Even if you’re not experiencing massive layoffs directly, the tension is palpable and the number of examples of this being handled poorly is growing.
Sean’s article is a very timely reminder of how to communicate change effectively. The key message: change is constant. Your organization is always going to change, in big or small ways. And as a result, setting expectations about change is the most important part about change communication. Say it early, even if you don’t have a lot of the details. At the very least, tell folks it’s coming. And do this many times. This way by the time the actual change happens, it doesn’t evoke a threat response and folks can focus on the substance of what is changing, and how to move forward.
This is an article worth printing and sticking on your wall.
Architecture of a modern startup
by Dmitry Kruglov
Finally, I really enjoyed this write-up of what it looks like to build a tech stack in a modern startup, and how that evolves as the business grows. My call to the data community: I would love to see a writeup like this for your data stack. What is the MVP version for a data team of one? How does this evolve over time as your team does? What are the tradeoffs? How has this changed in the current macro-economic environment, if at all? 🙏

I'm a data team of one in a Series A startup, and I'm new to the modern data stack. Our current data stack is RedShjft warehouse, DBT (manged by one of our software engineers until I get up to speed), FiveTran, and Looker for semantic layer/visualization. I feel like the Warehouse/ELT/Data Viz combo is the true MVP for a team of one, unless you're just truly a competent data engineer and analyst already, which I think is typically rare for teams of one. A summary of the "How does this evolve over time as your team does?" responses would be super helpful for me as I start to figure out next steps for either a) growing the team and what direction to go or b) what next tools we need to bring in (data visibility, data quality, etc.).