
Data Science Roundup #89: Relational Networks, Narrative Fallacy, Wine Pairings & more!

A brand new neural network architecture is proposed and tested by the folks at DeepMind—this is a big deal. Also, why basically everything that sports commentators say is gibberish 🏀🏈⚽
And plenty more, of course. Have a great week!
- Tristan
❤️ Want to support us? Forward this email to three friends!
🚀 Forwarded this from a friend? Sign up to the Data Science Roundup here.
Two Posts You Can't Miss
A Simple Neural Network Module for Relational Reasoning
This is cool. The authors of this (very accessible) paper propose a new neural network architecture that natively understands the way that various entities relate to one another:
…the capacity to compute relations is baked into the RN architecture without needing to be learned, just as the capacity to reason about spatial, translation invariant properties is built-in to CNNs, and the capacity to reason about sequential dependencies is built into recurrent neural networks.
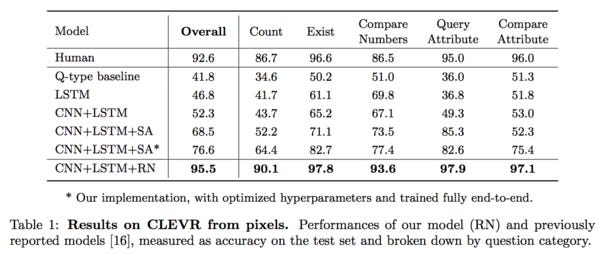
Relational reasoning is a core reasoning skill, and one that neural networks have not performed well on to-date. The authors go on to show that their network design performs at a superhuman level on certain challenging relational reasoning tasks like “What size is the cylinder that is left of the brown metal thing that is left of the big sphere?” The chart below contains their results. Impressive. There is also a blog post if you prefer.
The Blissful Ignorance of the Narrative Fallacy
I love this post. Sure, it’s entertaining and has a very worthwhile lesson, but I mostly love it because it so eloquently encapsulates why I fell out of love with sports:
Spoiler Alert! This post discussed the risks of the narrative fallacy and the dangers of our uncontrollable urge to explain things - even when there is nothing to explain. If you would like to continue to enjoy watching sports in all its dramatic glory then stop reading now. This post can help you to make better business decisions but may quell some of the bliss of sports entertainment.
It goes on to explore Steph Curry’s record-setting three-pointer record of November 7, 2016 as simply an unlikely yet entirely predictable point on a statistical distribution. While you may realize this to be the case, when you look hard at this fact you realize that a huge number of narratives about the world look just like it. Learning to recognize and discard these narratives will make you a more effective thinker.
The most accurate of all time is probably “because statistics”, but that doesn’t sell many jerseys.
multithreaded.stitchfix.com • Share
From our Readers!
Want to see your deep thoughts here? Shoot me an email! 📧
Reader Ethen Liu has been creating a library of tutorials for the past two years, painstakingly documenting his process of learning tools like Keras, NetworkX, Spark, and many more. I’ve recently been picking up Spark and found the tutorials included in this repo extremely worthwhile. Check it out, and give Ethen a star while you’re there ⭐⭐
This Week's Top Posts

Interactive Analytics: Redshift vs Snowflake vs BigQuery
Periscope’s evaluations of data warehouse technologies are always must-reads. They did an evaluation of Periscope vs Redshift in early 2015 that was hugely influential, and now they’re back with more.
After running a bunch of benchmarks, they choose Redshift on a price / performance basis, although they admit that their use case is very particular: high and consistent volume of queries, moderate dataset size (gigabytes, not terabytes). My belief is still that Snowflake and BigQuery are more optimal for most internal BI use cases but this was excellent data nonetheless.
Last year, after nerding out a bit on TensorFlow, I applied and was accepted into the inaugural class of the Google Brain Residency Program. The program invites two dozen people, with varying backgrounds in ML, to spend a year at Google’s deep learning research lab in Mountain View to work with the scientists and engineers pushing on the forefront of this technology. The year has just concluded and this is a summary of how I spent it.
TL;DR: tried to transform old video footage into 4K, unsuccessful, optimistic about future potential. Great read.
How big data can help you pick better wine
NLP + cluster analysis = really great wine recommendations. Great visualizations.
I’m beginning to believe that hiring is the single biggest challenge in analytics: from startups to large enterprises, finding talent is the biggest factor keeping leaders from getting insights from their data. This post gives advice for how to evaluate potential product analyst hires and is a solid read. I’m starting to think, though, that the bigger task might actually be growing skillsets internally—there just isn’t enough existing talent to fill the roles that exist.
You Can Probably Use Deep Learning Even If Your Data Isn't That Big
Last week I linked to a post called Don’t use deep learning; your data isn’t that big. This author took issue with those conclusions and wants to set the record straight: “You can still use deep learning in (some) small data settings, if you train your model carefully.”
Nothing says machine learning can’t outperform humans, but it’s important to realize perfect machine learning doesn’t, and won’t, exist.
I don’t know if this is actually a paradox…I think it’s more of a shift of mental model from the world where explicit programming is much more predictable. Humans are not built to reason probabilistically, and we’ll probably be intolerant of machines that do.
Data Viz of the week

New viz type: "packed bar chart". Click through for more.
Thanks to our sponsors!
Fishtown Analytics: Analytics Consulting for Startups
At Fishtown Analytics, we work with venture-funded startups to implement Redshift, Snowflake, Mode Analytics, and Looker. Want advanced analytics without needing to hire an entire data team? Let’s chat.
Stitch: Simple, Powerful ETL Built for Developers
Developers shouldn’t have to write ETL scripts. Consolidate your data in minutes. No API maintenance, scripting, cron jobs, or JSON wrangling required.
The internet's most useful data science articles. Curated with ❤️ by Tristan Handy.
If you don't want these updates anymore, please unsubscribe here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue
915 Spring Garden St., Suite 500, Philadelphia, PA 19123