
Data tales from across the multiverse
dbt + Iceberg, cost monitoring, AI innovation

Sometimes on here we like to go deep on a single topic, but today I’m here to share with you all a lovingly curated round of thought morsels on dbt and data from around the web.
It’s been very interesting to watch the evolution of what gets written about with dbt over time - familiar topics that pop up time and again while new technologies open up new areas of opportunity. This week we’ve got a classic data migration tale with an Iceberg twist, a very neat exploration of the dbt Cloud API and a new dbt Developer blog on testing best practices - and more.
But first!
We need you - yes, you - to take this year’s State of Analytics Engineering Survey. These really matter - the findings here guide product development, help us all understand where the industry is going and crucially help actually have something to say when we’re doing the annual State of Analytics Engineering webinar.
Building a transaction data lake using Amazon Athena, Apache Iceberg and dbt by Dr Soumaya Mauthoor
Very cool dbt + Iceberg case study in the wild!
The UK Ministry of Justice migrated their data workloads from primarily Glue + Pyspark to run on Athena, Iceberg and dbt. The results are … pretty impressive.

This is a great use case showing how modernizing data systems can lead to wins down the board - decreased cost, increased availability of data (their new system runs daily rather than weekly) and maintainability (more people can contribute to the new system than before).
Why Iceberg?
Iceberg allows Athena to utilise the RENAME TABLE operation. This functionality simplifies the Write-Audit-Publish (WAP) pattern, which is commonly used in data engineering workflows to ensure data quality. WAP involves writing data to a staging environment where any errors can be addressed before the data is released to users. With Iceberg, the interim table can be easily renamed once validation checks have passed, streamlining WAP for full refresh pipelines. Additionally, Iceberg’s time travel feature facilitates WAP for incremental pipelines by allowing historical data access through a FOR TIMESTAMP AS OF <timestamp> filter applied to views built on top of the source table.
I expect we’ll start to see more momentum over the coming year of teams adopting dbt on top of Iceberg (and springboarding from there into cross-platform Mesh).
dbt at Scale: Multiple Project Monitoring by Nuno Pinela
Nuno shares some really nice work showing how he used the Admin API to build custom monitoring across a set of multiple dbt Cloud projects. What for?
With such a dashboard, you can easily track key metrics such as the number of scheduled jobs per project (daily, monthly, etc.), monitor for errors over the last few days, and analyse the overall performance of your data transformations over time. Moreover, the dashboard can provide an interface that allows you to navigate directly to the dbt project, enabling you to quickly investigate and troubleshoot any issues that may arise. Additionally, a live summary of the system’s status, including the running jobs and their progress, can be invaluable in maintaining the health and reliability of your data infrastructure.
This opens up cool use cases where you can see things like model execution time and when jobs are scheduled across various dbt Cloud projects.
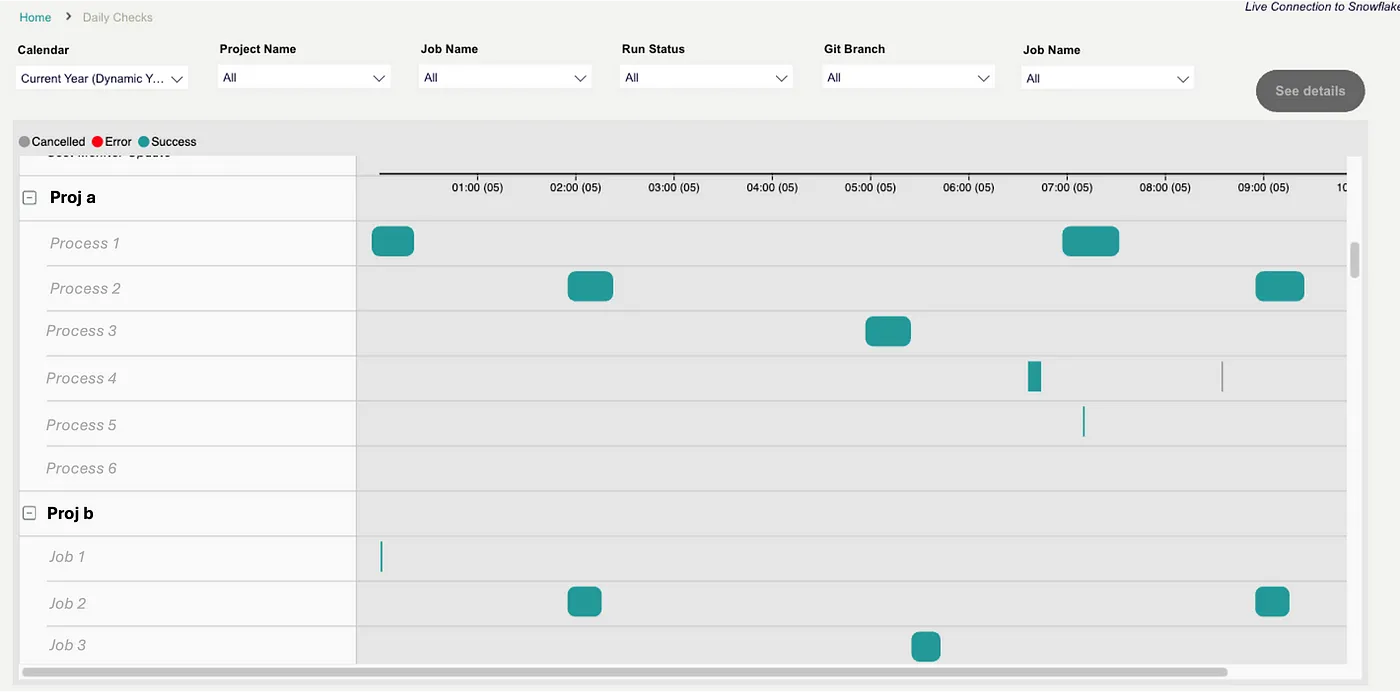
Over time, expect to see more of this living directly within the product - Nuno calls out dbt Explorer as a place where information such as this could live.
Seeing reports from people building this in action is a strong signal that this is a real need for data teams - would love to hear from readers what else you’ve been building using the API (and any improvements you’d like to see us make).
Our journey to Snowflake monitoring mastery by Rob Scriva
Every time the Canva team has a new blog post on their data infrastructure you can be sure it’s going to be worth checking out. This post is a deep dive into how they’ve built metadata monitoring systems to help them get a granular view into their warehouse spend.
This is important because Canva operates on an impressive scale.
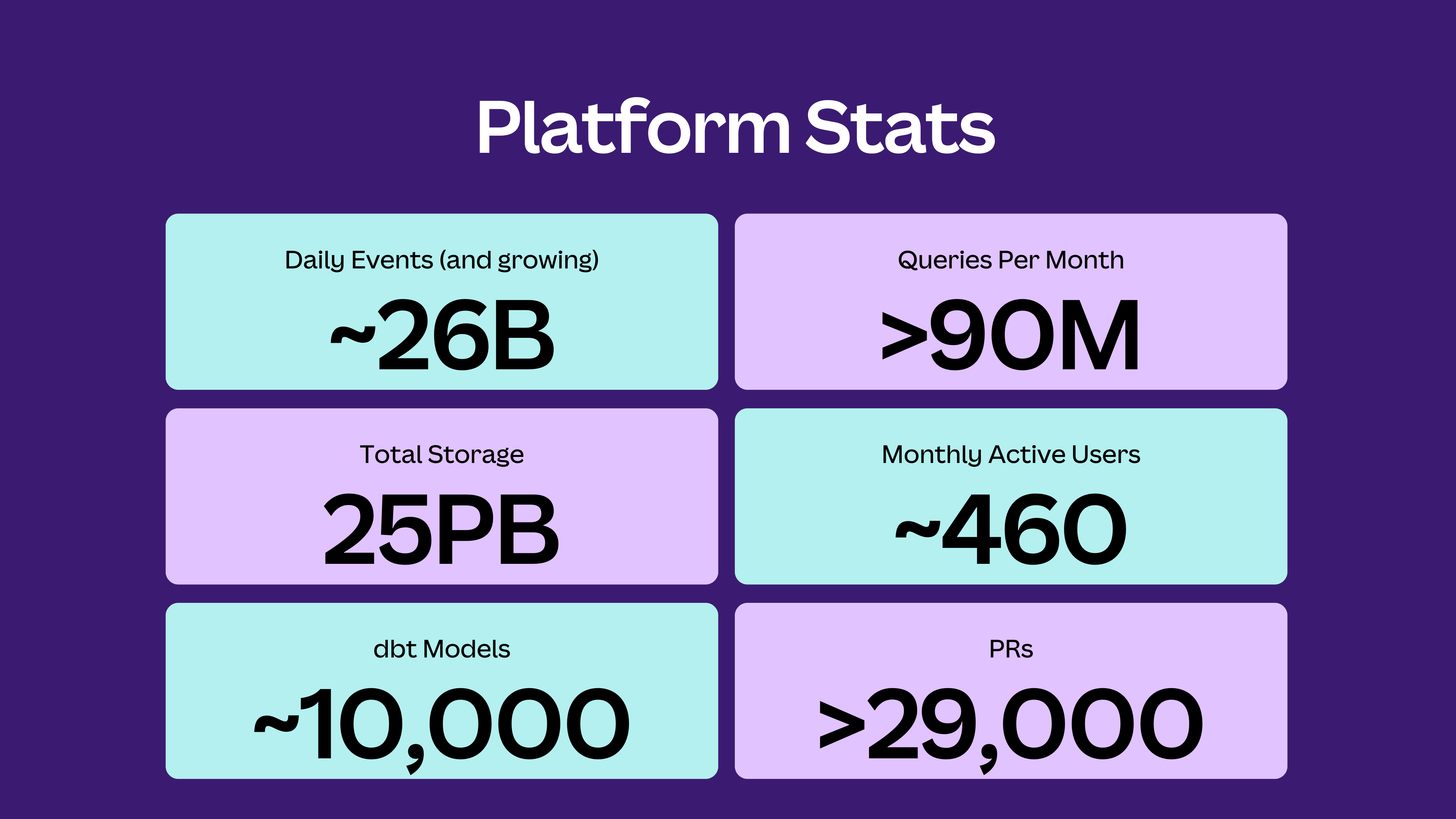
It’s not just dbt Projects of this size though - across the board we’re hearing that data teams are looking to be able to make sure that they are tracking their spending and performing efficient operations. Watch this space.
Need a break before checking out the rest of the articles. Click the secret mystery button below for a fun surprise (ok fine it’s the State of Analytics Engineering Survey again).
Test smarter not harder: add the right tests to your dbt project by Faith McKenna and Jerrie Kumalah Kenney
Faith and Jerrie from the dbt Labs team have seen a lot of dbt implementations in their customer-facing work at dbt Labs and they’ve put out a great new post highlighting what they are seeing in the field.
The particularly interesting question is “what should you test and when” There are failure modes associated with not having enough tests on your data but also with overtesting your project.
We’ve definitely seen [dbt projects with] so many tests that errors and alerts just become noise. We’ve also seen the opposite end of the spectrum—only primary keys being tested. From our field experiences, we believe there’s room for a middle path.
A great insight here is that you need different testing strategies for different potential data problems - they break it down into three buckets - data hygiene, business anomalies and stats anomalies
Artificial Intelligence, Scientific Discovery, and Product Innovation by Aidan Toner-Rodgers
I can’t help myself - one AI paper.
A key skills for data practitioners is looking at what’s actually happening and comparing it to your mental model . To that extent, I want to share this extremely good (dare I say groundbreaking) paper on using AI for innovation and idea generation. At this point it’s becoming a bit of a cliche to say that LLMs will help automate routine or rote tasks but that will have less impact on areas that require real insight. Is that true?
This paper writes about an actual, randomized controlled trialed with measurable outputs where AI tooling was introduced into the materials discovery r&d process in a large firm. The findings were dramatic, nonobvious and if they generalize present an important view into the future of knowledge work.
AI tooling increased innovation - A 39% increase in patent filings and a 17% increase in downstream product innovations
The gains were not evenly distributed - Output from the top researchers nearly doubled while some researchers saw no gains
Job satisfaction dropped - As part of the work that people really value doing was driven by the machine
One interesting tidbit rattling in my head around this one is the ways that top researchers were able to be most impactful here - they do so by having a strong intuitive sense of which research areas were tied to actual value and which were dead ends.
”I show that scientists’ differential skill in judging AI-generated candidate compounds explains the tool’s heterogeneous impact. I collect data on the materials researchers test and the outcomes of these experiments. Top scientists leverage their expertise to identify promising AI suggestions, enabling them to investigate the most viable candidates first. In contrast, others waste significant resources investigating false positives.”
We’ve talked in the past about ‘data intuition’ being a key skill for data professionals, being close to the business and the data and using that to help guide organizational stakeholders towards actually valuable data work and away from wild goose chases. I’d be willing to bet that there is a similar mechanism going on for top researchers in this paper - I don’t think we’re close to a formal theory of what data intuition looks like, but my guess is it’s going to be even more important in a world where AI tooling has more fully saturated the data ecosystem.
Update: The paper I mentioned here has been withdrawn
https://x.com/calebwatney/status/1923381097938702436