
dbt is learning to ❤️ software engineers
Also in this issue: learning to navigate oceans, building for quality from the beginning, and why the biggest fallacy of metrics are also their biggest strength


In the most recent podcast episode, Jordan Tigani of MotherDuck and DuckDB flips the vision for "data apps" on its head. Tristan, Julia and Jordan dive into the origin story of BigQuery, why Jordan thinks we should do away with the concept of working in files, and how truly performant “data apps” will require bringing data to an end user’s machine (rather than requiring them to query a warehouse directly).
By complete coincidence, this roundup will also feature a reaction to Daniel Palma’s Temporal Analysts of Wikipedia … with a nod to Unistore and DuckDB, courtesy of one of our rockstar solutions architects, Sung Won Chung.
Also featured in this issue:
challenge_type in (‘rabbit’, ‘mustang’, ‘ocean’) by Ashley Sherwood
the optimetricist by Stephen Bailey
building quality from inside out by Petr Janda
Enjoy the issue!
- Anna
dbt is learning to ❤️ software engineers
Guest post by Sung Won Chung
I came across:

and stumbled upon:

and got an adrenaline rush from this DuckDB powered SQL experience here:
This was the singularity event I needed to realize:
dbt makes data better for and with: Data Engineers, Analytics Engineers, Machine Learning Engineers and Software Engineers
No dramatic pause, no skepticism, no naive optimism. I feel confident to say that whole sentence in one breath starting today.
I’m not here to proclaim a new go-to-market strategy for dbt. I’m just so glad that data and software people will have more meaningful interactions together. It’s still early days, but the fact that all the above tools exist today gives me so much hope. People care about making data experiences better, and they’re actually achieving absurd goals.
So why don’t we have this yet? And what’s preventing this from being the new normal? Let’s start with the problems we’re seeing today.
Problems
1. OLAP is slow and unreliable in the eyes of software engineers as a backend.
And I totally understand why!
In candid conversations with software engineers, performance is not talked about in minutes or seconds. Milliseconds is normal. Heck, some products brag about making every interaction in their product run in <100ms.
Also, transactional databases have data integrity and ACID compliance out of the box. Data warehouses don’t, and no one wants to write manual SQL tests for basic data validation.
2. Data people aren’t used to speedy performance.
And I totally understand why!
I’ve worked in data my whole career, and I can’t imagine 28 SQL queries running in milliseconds against a data warehouse — mostly I worry if they will run at all.
Refreshing my BI dashboard in 30 seconds or less feels blazingly fast to me. 🔥
3. Data teams are still learning software engineering best practices.
And I totally understand why!
For many data teams onboarding to dbt for the first time, it’s also their first time working with git. And this is a really great thing! There’s so many more teams out there that are on the cusp of transforming how they work.
But that also means we’re probably some ways away from data humans building production grade applications:
The above problems don’t discourage me though, and I hope they won’t discourage you. I see a lot of potential solutions in motion that are helping solve for these challenges already, even today.
What’s driving current momentum?
Software engineers already want to work with data in places like BigQuery, Snowflake, and Databricks through tools like cube.js. It essentially uses middleware to cache common query results against data warehouses and achieve millisecond speed in applications:
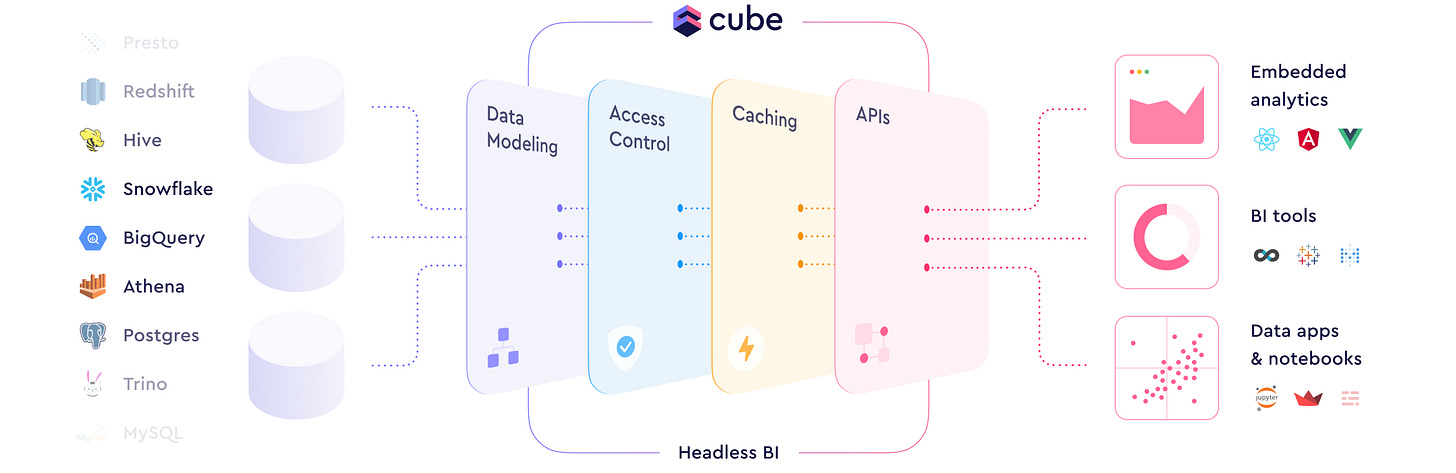
source: cube.dev Data platforms like Snowflake are seeing the deep hunger for faster SQL operations, which is why Snowflake has just dropped Unistore: a hybrid OLTP/OLAP database at their recent Summit in Vegas.
The industry is continuing to reimagine old patterns and workflows. A great example is the DuckDB in-process OLAP DBMS. The DuckDB team is trying to solve Problem #1 above: keeping OLAP simple, but making it faster and more reliable.
This is kind of a huge deal for analytics query workloads. Here’s a demo of dbt running those same 28 queries in milliseconds on top of a local DuckDB deployment: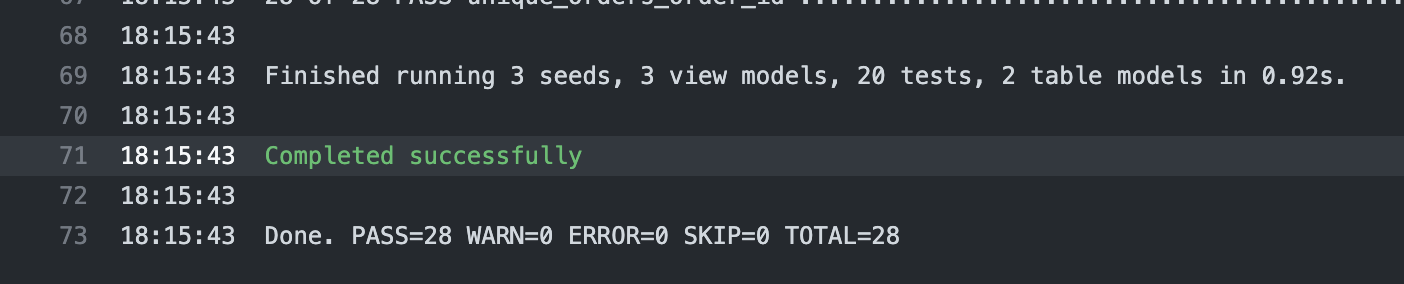
28 SQL operations from a dbt buildrun on top of DuckDB in 0.92s


What are the remaining gaps?
Winning the culture war that data analytics can be an ergonomic and delightful experience for software engineers.
Normalizing the expectation that OLAP SQL can and should work in milliseconds for both data and software humans
Having data and software humans actually start doing work together, and not just talking about it ;)
What’s Next?
Share this with your friendly neighborhood software engineer:
Does this future excite them?
Do they care?
Is this an unrequited love?
Elsewhere on the internet…
Compiled by Anna Filippova
challenge_type in (‘rabbit’, ‘mustang’, ‘ocean’)
By Ashley Sherwood
I will likely finding myself coming back to this post again and again over the course of the next several months. The metaphor of a raging ocean is so appropriate for what we are all likely experiencing right now. Ashley’s advice: don’t try to tame the ocean, learn to navigate it instead.
A tamer first asks: “What am I dealing with?”
A navigator first asks: “Where do we want to go?”
What I interpret this to mean:
some problems are so complex that all the options to solve the problem are unknowable.
other problems are complex because progress is incredibly hard to measure objectively. Very often these problems involve human emotion.
in both cases, it is much more helpful to orient around where we want to go and iterate, rather than getting stuck trying to develop absolute certainty of the problem space
Navigators prioritize direction over certainty and think in terms of knowing enough, not knowing it all.
I will be thinking about this a lot the next time I am setting goals and direction, especially OKRs. Is the problem we’re solving a mustang or an ocean?
Let’s take something seemingly knowable such as customer churn. The mustang approach to solving a problem in this area looks like identifying all the drivers of churn by looking at correlated actions someone takes before they churn, and then working to improve those specific experiences. This feels very satisfying in the moment because you get a set of boxes to check, but you can easily lose sight of the bigger picture of what you’re building. An ocean approach takes a few steps back and asks — where are we going? What experience are we trying to deliver, and where are we falling short? And then testing and iterating on those improvements.
Ashley’s post made me look at a lot of decisions quite differently. Thank you for this useful lens 🙏
By Stephen Bailey
Stephen’s post this week occupies the same space in my brain as Ashley’s in so far as they both encouraged me to think about dimensionality reduction in decision making. Huh?
Stephen is reminding us this week to be weary of looking at metrics for metrics sake, and that metrics represent a very simplified version of a complex reality. It’s possible to abuse metrics by focusing on the observation more than on the thing we’re actually trying to approximate. Sometimes we don’t even remember to ask what the thing is we’re trying to measure — we get so caught up in the process. But it is also equally possible to use metrics to dramatically reduce the violence of an ocean-level problem, and use metrics as a brilliant and simple alignment mechanism as long as we remember that it isn’t a perfect representation of the problem and to adjust our measurement and understanding of the environment as we go.
Back to OKRs. This is why fewer OKRs are better, simpler OKRs are better and why we have to build in the capacity to adjust both our approach and how we expect to measure success along the way to our objectives as we learn more about navigating the ocean.
My one gripe:

Pretty sure this number should be 42 ;)
Building quality from inside out
By Petr Janda
Accidental complexity is a sum of all the shortcuts we have taken. More than a sum—complexity attracts more complexity and compounds in a non-linear way. Every shortcut you take is an invitation to more shortcuts elsewhere.
Petr’s post is a great way to roundup (ha!) this issue because he introduces several concrete ways of managing dimensionality, that is complexity, in analytics code inspired directly by software engineering practices.
Paraphrasing Petr and extrapolating a little to data modeling:
less is more. It’s a lot easier to maintain a less complex system, and it’s far better to have few things modeled well than to have many things build on a shaky foundation.
building with blueprints. You don’t build a house room by room. You go through an architectural design process and then build from the foundation up following those blueprints. Similarly, you shouldn’t build data models without an overarching organizational principle behind them. Your data model is a representation through analytics code of the most important aspects of your business. Rather than trying to build a data model one department at a time , identify your most important objects and entities and model those. Then identify the most important activities you care about related to those objects and entities. Once you have this high quality foundation, you’ll be surprised how much you can build on top easily, and how easy it is to maintain.
 | A guest post by
|
Oof, I was so close and yet the entire meaning of life away
Great roundup! dbt definitely does help data and software people will have more meaningful interactions. 🎉
Over at Prefect, we're making it easier for data humans and software humans to work together by providing scheduling, observability, retries, and more with Python. Our OSS package and cloud platform build trust and play nicely with dbt and other members of the modern data stack. 🙂