
Ep 29: Making Sense of the Last 2 years in Data (w/ Jennifer Li + Matt Bornstein of a16z)
What even *is* a data platform? Is it time yet for analysts to build ML models?

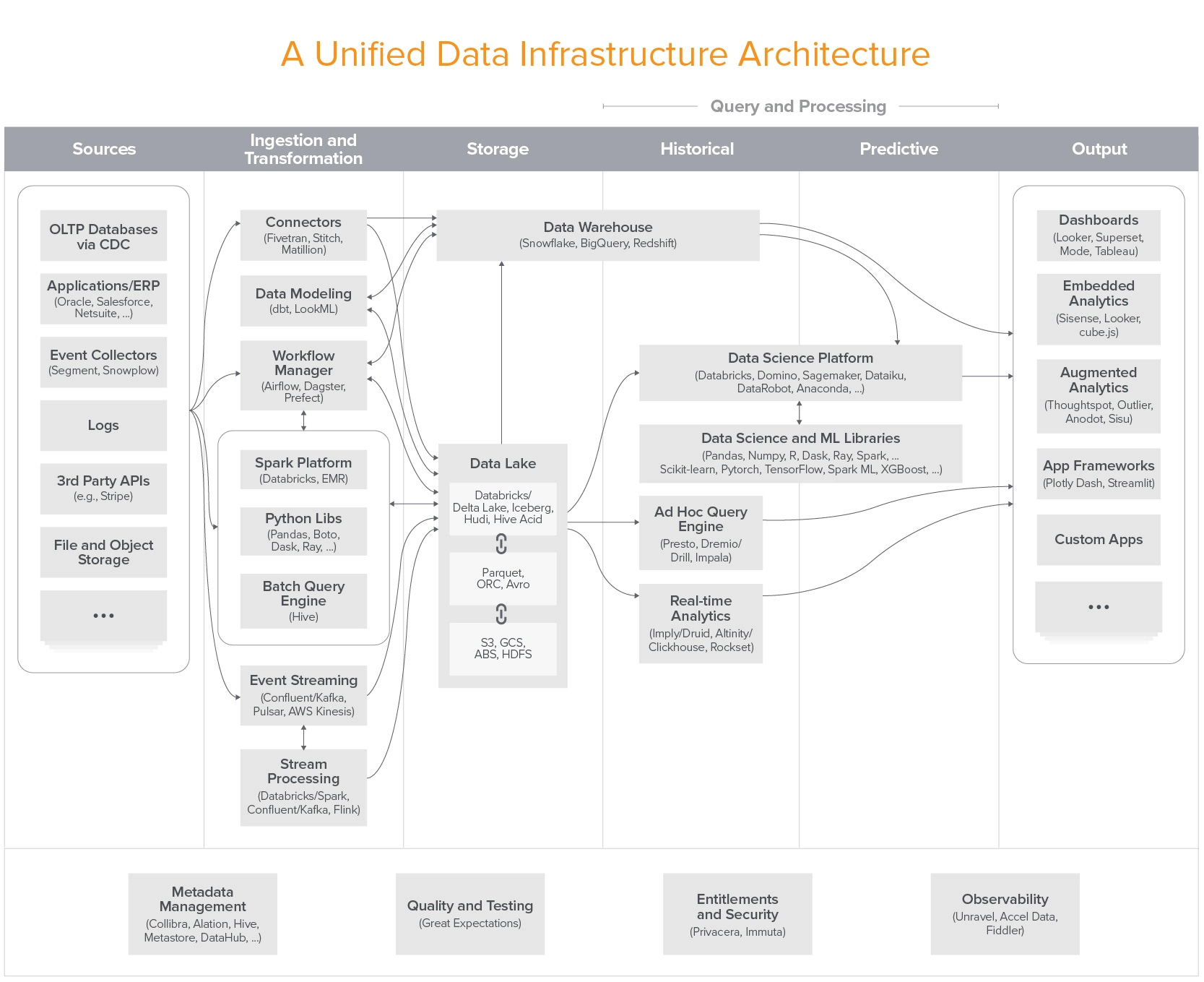
Matt Bornstein and Jennifer Li (and their co-author Martin Casado) of a16z have compiled arguably the most nuanced diagram of the data ecosystem ever made.
They recently refreshed their classic 2020 post, "Emerging Architectures for Modern Data Infrastructure", and in this conversation, Tristan attempts to pin down: what does all of this innovation in tooling mean for data people + the work we're capable of doing? When will the glorious future come to our laptops?
Listen & subscribe from:
Show Notes
Key points from Jennifer and Matt in this episode:
What do you mean by “unified data structure”?
Matt:
Yeah. So I have a really strong point of view on this. The fundamental principle here is that data is a measurement of the real world, right? If you think of Drew's keynote from last year, you go back to the very early uses of numbers. It's all about trying to understand the world around us. it's lengths and widths and distances and weights and all this kind of stuff.
If you believe that premise. Then that means anything we do with our data is highly complicated, across many different use cases, all sorts of weird edge cases that you're never going to think of in advance and so forth. Then this comes up a lot in the machine learning world that we do a lot of thinking about.
One implication of that in the analytics world though is you actually likely need different systems to do different things with your data. And I think that's what we're seeing take place now. The data warehouse historically has been an incredibly powerful tool and system of record, and arguably still is the leading technology to do both storage and querying. But you're seeing a huge proliferation of other things, like Spark and Databricks, like these distributed query engines like Presto, real-time analytics, Druid or ClickHouse. Stream processing a making a comeback or making a go of it for the first time, depending on your perspective.
And in order for all of this to work for especially large companies, but sophisticated data teams, in general, to take advantage of all these different systems and process all their data in the ways it's really demanded if you'd think you can actually model and understand the real world, the separation of storage and compute helps you do that because you don't need to make your storage layer more complex in order to take advantage of all these new ways of doing things. You're right that it's quite different from the way snowflake does it, Snowflake separates storage and computes at a technical level because there are lots of benefits to doing that around cost and scaling and so forth. But they do not separate it at a sort of a business level or at a product level, which is fine but it's solving a different problem.
Jennifer:
Yeah, I think taking a technology view med subpoint is absolutely right. It's on a technical and we see the separation in architecture shift of separating the storage and compute. But I think if you were to take a practitioner's view, this is really a reflection of how people are thinking about processing their data. It used to be very much tied to where the data resides and you have these limitations, and constraints of where you can process it because the data is residing either on-prem or in the customer's data warehouse, that's not centralized or easy to access.
Now, given data is sparse around your internal database, warehouse sometimes you bring in third party data, sometimes it's meshing was customer clients data like the knees or the usage of data is very different. Practitioners tend to think of, take a view of what are the use cases I'm trying to drive and not tied to where the data resides and think about the processing and querying to fit in their need, whether it's machine learning, whether it's analytics, whether it's building applications. And that in turn lead to what on the most right off the box where it analytics and output column is way more comprehensive than years ago. It's more about dashboarding and building graphics and charts.
Can you just give us a sense of which ML areas are moving the fastest?
Matt:
It's a really interesting question. I would argue that the analytics ecosystem is much more mature than the machine learning ecosystem right now, which is one reason you see so much going on in, in machine learning. The workflows are really not nailed down yet in machine learning. I think there's sort of an existential debate going on about whether machine learning is a product or a process. If that makes sense.
Like if you take the product view, then you think, "Oh there's some way we can package up machine learning technologies into some sort of SaaS app and sell the capabilities to people in sort of a pre-packaged way". If you take the process to you, you would basically say machine learning is coding of sort of a different sort. So there's no way to really draw a box around it. Like most companies will probably need machine learning teams in that view and really do the work themselves in a kind of pretty unique way to their business requirements and their business logic.
So there's this really interesting sort of thing going on and until that's resolved in some sense, I think you're going to see just like everything that may make sense, people are trying and putting all these tools out there. You can buy five tools if you want to do things in the really sophisticated way in the ML world, or you can buy one tool if you think the sort of low code version is good enough, or in the really extreme version, you can go to Salesforce and say like, "Hey, you do lead scoring for me. I don't, I don't, I want zero tools to do it. I just want it to be built into my CRM".
All that is sort of going on and if you're a maximalist to borrow the sort of web three term is you probably think everything's going to happen. Like all of these things are going to become durable and really important parts of the machine learning world. If you believe machine learning is an important thing, which I personally do, and it gets back to this idea that data is sort of an attempt to measure the real world. And this is a way that we can help we can try to understand it.
Low code in particular is very interesting. There are a number of interesting companies in these new companies, and startups in the space like continual AI are interesting. There's one called Akio, mindsdb, which is sort of a database integration play-in. What they're all trying to do is sort of nail the workflow that makes machine learning more accessible to more people.
And you may not be able to use these tools to do really kind of hardcore in the product, but a culture of online real-time machine learning. So you wouldn't use a low code ML tool yet at least to do something like that, which is pretty misspoken and has pretty intense requirements. But for an ordinary analyst, who's just trying to do lead scoring, there are a lot of really great tools now that you can use SQL primarily can use some Python or even just call some REST APIs and get like a pretty accurate model that does a lot of what you would need, using fairly standard - what are called sort of boosted trees or other kinds of traditional machine learning models are really good enough for the vast majority of these kinds of analytic use cases.
Jennifer:
Where we see the most movement is actually bifurcated around various sophisticated use cases that process a large amount of data. These spoke to companies like Uber, Airbnb, and Netflix, which are writing kind of recommendations algorithms, as well as more real-time applications, that's a set of tools being adopted to enable that large scale data processing and model training. And the other side is actually where we see a ton of excitement and movements is the pieces that tie very closely to the analytics world, whether it's query engine, whether it's metrics layer, whether it's workflow orchestrator.
Smoothing out the workflow between data teams that process analytical batch data and merge it with some real 10 models or even also one-off models to predict price or revenue. So those two workflows are where we see a lot of excitement where. The little bit of a beta value at which I call it sort of this no man's land where you're trying to do complex tooling for like not very well equipped a team to like fully invest invested into like beauty, immersion learning functionalities for the applications that they are trying to do.
Do you have any sense of what are the like really bleeding edge categories of ML that only the Ubers, Airbnbs, etc., are using?
Matt:
So I have a really favorite one in this thing that I'd love to talk about. Andre Carpathy gave this amazing talk a few years ago on the different types of stop signs in the world. And it sounds like the most boring thing you could possibly imagine, right? Like you've never liked how many miles have you driven. You've never even thought about what your stop sign might look like, but literally, he ran through it. Must've been a hundred examples of, there are two-way stops. There are four ways to stop. There are stop signs attached to school buses, stop signs attached to bars that come down over the road, like this, to stop you from getting hit by a train. And there are things that should be yields or merges that are also, literally there are way more than you think.
And what's so interesting about this is they built this system at Tesla that automatically generates weird examples of data for them. So they've got however many Tesla cars they have out on the road. They all have cameras attached to them. And Tesla is able to not only consume those video feeds but identify things that are interesting in those video feeds for machine learning purposes. So that they can better train their self-driving feature.
And that's a really hard problem, right? If you have, literally billions of hours of video to try to, parse through and figure out just where's my model working? Where is it failing? And where's just the plain weird stuff that we never could have anticipated before we put all these self-driving systems out there. And what they built was a system that sort of automatically identifies. So if you're interested in stop signs, it goes out and finds a million different types of stop signs for you, puts it into a flow where engineers can see what that data looks like integrate it into their training process and ultimately retrain the models to make them better.
So you get this sort of loop, a feedback loop where you develop the machine learning model. You get it out and deployed. You have a data collection mechanism, that's figuring out how it's working, how it's not working and then using the outputs of that to make the models better, and then, continually improve. This is the holy grail that people have always wanted in machine learning, this kind of continual learning model. Tesla has it and they've been talking publicly about it. And now everybody else wants it. So you're seeing a bunch of new startups essentially trying to replicate that in some form.
The key question is how does it plug into the rest of the workflow? And again, like if most companies don't understand their own ML workflow yet, how easy is it to plug into it? it, But it's something I'm very excited about because it can deliver on this idea that machine learning is actually getting better and better over time, and plus it's just cool, right? If you're a connoisseur of weird stop signs, it's just fun stuff.
Jennifer:
Yeah, my answer to that is or what is cutting edge? I believe every time when we started talking about a term like reinforcement learning, like deep learning, it actually started getting mainstream, like four or five years later.
Like probably a lot of the conversations started four or five years ago, but the real applications and the real use cases only started emerging now. So one of my favorite examples in this processing box or layer. It's very magical you had a few of the lines of Python and the whole processing it's parallel lies in the performance improvements it's really a night and day difference.
And, again, something that really is needed for policy and a large amount of data for reinforcement learning. And that's where the best use cases are today. But you can definitely see a future where this speeding is generalized for a lot more when ML workflows or other large-scale data workflows.
What do you mean when you say data platform? And are you taking a stance like is this happening?
Jennifer:
I think that the point or at least the question we want people to think about what's data platform is what do you mean to bring the analytics world to the data applications together? And that's what this picture of the data platform it was trying to paint is you will have this very mature ecosystem now for Alica data workloads. And there are a lot of requirements and demand for building data applications.
And what is the future look like? That's really bringing these two, two use cases together. And whether it's unbundled or bundled probably in the near term we'll still see more tools coming up to enable that future. There are a lot of conversations around what it means for OLAP databases and transactional databases to work together more seamlessly so that the developer experience it's much better than having, a data team build tables in one way and have brought them, bring the data in from 10 different data store, like that whole workflow, what it means to the end-user.
So that's the core ethos of how we're thinking about data platforms is trying to have a future of what it could mean, or it could be when the emergence of data apps is being built. There are a couple of ways of either tying the transactional data to an analytical data store or the other way around by exposing APIs to access these tables.
Matt:
Bundling versus unbundling is I think a tough thing to talk about and, people much smarter than us have shared a lot of interesting opinions about it. I think, for instance, Ben Stancil has some of the most interesting takes and everybody should read what he says. But what's interesting is like the technologies and the products that you see in the data stack right now are most likely a reflection of the actual need for what people need to do with their data.
If you just look at tech categories historically where you get this huge perfusion of vendors and products is where the need is really the greatest cyber security is a great example. If you think the data stack is ugly, you should see a cyber security market map, and for every tiny little problem that anybody's ever had, there are five companies that address that tiny problem in particular. And security buyers are constantly trying to consolidate their vendors together because they're sick of buying from so many people at the same time and they would like the world to look different. But the reality is those tiny problems are not actually tiny, right? Somebody at some point in history has had a massive security issue because of each one of these little problems that, they had a pole in there, upstream a software supplier or something, a vulnerability or upstream software supplier or something like that.
So whether we as practitioners or as investors or as, founders want everything to consolidate together or not bundled together or not may have a huge impact on whether it actually does, which is counterintuitive. Cause you would think like the customer is always right.
And whoever's implementing these systems should really have the final say, but if it may not be up to them, if the problem to be solved is such that you just actually need all these tools and you may see vendors consolidate, you may see one company buy another, and that happens all the time. And that helps from finance and sort of a business standpoint because you have to deal with fewer vendors, and billing's easier. They may talk to each other a little bit better.
But that's unlikely to fundamentally change the products that we're using, right? Like it would be unusual if one big data company bought another big data company that the actual product experience would change. More likely you would continue to use both those products because they proved to be important and have big user bases and businesses behind them.
Articles mentioned in this episode:
More from Matt and Jennifer:
You can find them on Twitter at @BornsteinMatt and @JenniferHli.