
I built a (very small) long running agent

Last week, Tristan wrote about his experiment with agent swarms. I wanted to follow this up with an experiment into another emerging agent modality - long running agents.
Why?
We like to make sure our beloved readers of the Roundup are kept as up to date as possible about where the underlying technologies that power data teams are going. And, if you’ll forgive me for saying so, we do a pretty good job at it.
Regular readers of this newsletter learned about the rise of agents for useful data work in 2023. It took us until about last November to get to a world where the agents we described there became common in production, helped along the way by improvements in the underlying models, improvements in the harnesses running them and in new open standards like MCP and agents skills powering these agents.
It’s pretty incredible to see the world we saw a blurry picture of in 2023 become a reality, and today we’re casting that net out again.
So now that we’re in a world where agents can reliably perform tasks with data.
What do we do with that? There’s a number of patterns. Some are already common today:
Set up systems to perform one off tasks on some trigger. The best example of this is the increasingly common analytics agent slack channel, where a business user comes with a question, kicks off an analytics agent and receives an answer.
Augment and accelerate human work via paired development with an agent. This is what happens when you are building a dbt project alongside an agentic harness such as Claude Code or the dbt Developer Agent.
Then there’s some that we are seeing glimmers of, but aren’t as widespread just yet:
Multiagent systems that monitor complex workflows and take targeted action when warranted. Tristan wrote about this last week in his post I built a (very small) agent swarm.
Long running agents that are able to handle substantially more complex goals than current agents. An example of this would be “migrate my entire dbt project to Iceberg” or “refactor my dbt project from Star Schema to Data Vault”. Anyone that’s familiar with current agentic systems would rightly be very uncomfortable trying to do this. But is it possible, or on the near trajectory to being possible?
We are in the early innings of long running agents
I’ve been obsessed with long running agents ever since Cursor put out a blog post showing how they had built a web browser from scratch earlier this year. This post blew my mind because it totally, completely upended my upper bound for the level of complexity an agent could handle - this is not a single task, this is something that would take teams of dedicated software engineers weeks or months to complete. This was followed up shortly afterwards by Anthropic’s clean room implementation of a C compiler.
These are research projects and come with a ton of caveats. Firstly, these are both extremely verifiable tasks, so the agent could always track its success against an external oracle. And the end result of these reimplementations while impressive, aren’t something you’d actually use.
Still, these projects make it clear that for some subset of highly verifiable projects, agents can do much, much more than we think they can today.
A popular variant of the long running agent is the “Ralph Loop”, where you give an agent a goal and it keeps going until it has verified that it’s done it. This allows for an agent to continue iterating on a problem much longer than it previously would have.
Recently the major harnesses have been implementing this with the inclusion of the goal command (ex 1,ex 2).
So I figured it was time to bring long running agents to the data world and see what they can do.
And that’s how I ended up building Tinyberg.
The simplest variant of a long running agent
I settled on a project to build a clean room, read only implementation of an Iceberg table inspector.
The actual implementation was done in as simple a format as possible - I used the goal functionality in Claude code to ask it to build out an implementation of the Iceberg spec using no external references other than an oracle aka a verifier which would test the output of this system against the Iceberg implementation.
Here’s the exact workflow I ran:
Determine what to build and create a spec: I collaborated with GPT 5.5 on the initial project scope and idea and we cowrote a simple spec as our end goal.
Build Tinyberg: a deliberately small, read-only Apache Iceberg table inspection and scan-planning library.
The goal is to implement enough of the Iceberg table metadata model to understand a local Iceberg table directory without relying on DuckDB, Spark, PyIceberg, or any existing Iceberg reader in the implementation.
Tinyberg should be able to:
1. Load a local Iceberg table from disk
- Locate and parse the table metadata JSON file
- Understand the current table metadata version
- Expose basic table properties, schema information, partition specs, and snapshot metadata
2. Resolve snapshots
- Identify the current snapshot
- List all available snapshots
- Resolve a specific snapshot by ID
- Produce useful errors for missing or invalid snapshot references
...... (cont - this is about a third of the total spec)
- Include tests for metadata parsing, snapshot resolution, manifest reading, file planning, and pruning
- DuckDB, PyIceberg, or another mature engine may be used only in tests or fixture generation as an oracle, not in Tinyberg’s runtime implementation
Set up a long running agent to iterate on the spec until the goal is completed: There are many ways to do this of varying complexity, but I went with the simplest one - loading the spec into a directory, booting up Claude code with
goaland asking it toimplement the entire feature set as described in the spec.md
That’s it - then you let it rip.
After two hours of the agent humming away (modest by agent standards, but again we’re doing a minimalist proof of concept), I had a working example that implemented the six requirements from the spec (load a local iceberg table from disk, resolve snapshots, read Iceberg manifest metadata, produce scan plans, provide a CLI and include a test suite).
With some additional time, many tokens and probably not all that much effort on my end, we could probably build out a lot more functionality into Tinyberg. The main requirements would be updating the spec with additional functionality. But I’m going to leave Tinyberg where it is for now, because the interesting thing is how data teams can start to deploy long running agents.
Exactly how these long running agents get deployed depends on which jobs to be done within a data org are able to be validated, as these will be the first set of tasks where long running agents become plausible.
Highly verifiable tasks that may currently or soon be tractable with long running agents
Data platform migrations - I have a series of data assets on data platform X, I’d like to move them to data platform Y (or an open table format). I create a long running agent to manage the migration and validate that the data matches exactly
dbt best practices enforcement - Set up a long running agent to ensure your dbt project aligns to the best practices as defined in dbt project evaluator and ask the agent to iterate until the project is conformant
Library upgrades, for example upgrading a dbt project on an outdated version of dbt to the dbt Fusion engine
Spend or speed reductions in your data pipelines - iterating over your data pipelines to find optimizations
Data diff remediation - “Given a known mismatch between prod and staging, iterate until the diff is gone.”
These are incredibly exciting! These all sit right at the sweet spot of highly verifiable and valuable. What might not be the right goal for long running agents today?
Building your semantic layer from scratch - you could quite likely use this to get a semantic layer and there might even be a lot of valuable work in it. But fundamentally the thing that makes the Semantic Layer valuable is the organizational buy-in on your metrics, which is not something you can put in the verification loop from scratch.
Deciding on a data platform architecture - tooling and architecture decisions don’t really have any ground truth to verify against - they become the ground truth against which your later systems get validated .
In general, if there is an easily verifiable outcome, it’s a great candidate for long running agents today. Anything where you have a known source of truth to compare against or a metric to optimize. That’s probably where the most leverage is for experimenting with long running agents in data systems today.
But like with most things in the world of AI, we should expect rapid evolution here.
Where long running agents go from here
This article should hopefully pique the curiosity and maybe get readers running some initial experiments. The great thing about the goal command is it’s available out of the box in many coding agents today. But you should expect rapid evolution here, with substantial improvements to the way long running agents are run that improve results and make more ambitious projects tractable.
For a glimpse into that future, I recommend this post from Anthropic on Effective harnesses for long-running agents or the excellent talk on the evolution of long running agents.
Their essential thesis is that we are moving towards long running agents that, rather than being one simple goaled loop, contain multiple agents working together from a shared filesystem but within separate context windows.
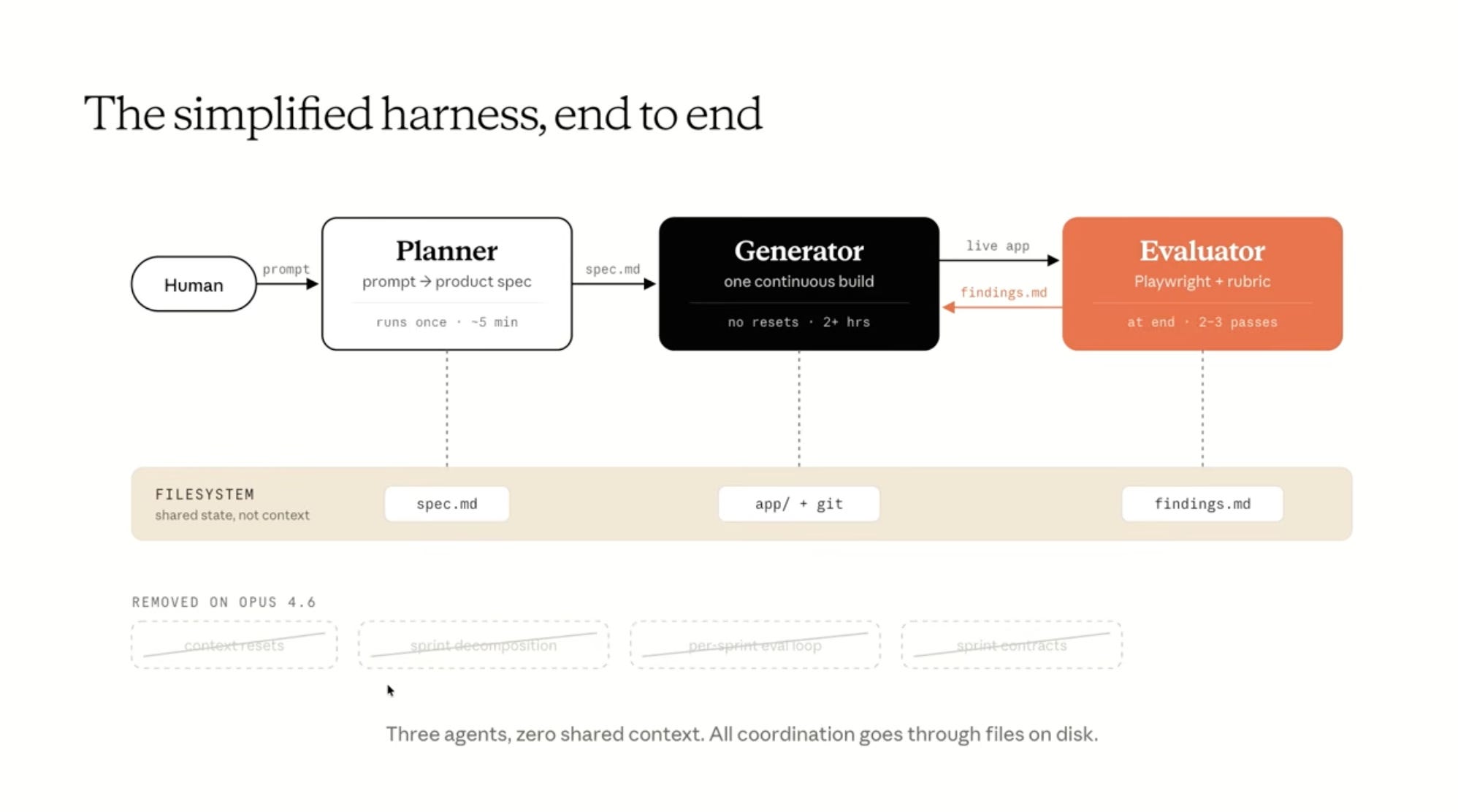
This architecture shows promise for long running agents that tackle more complex tasks, but does more than that. With the addition of the evaluator agent, you can dramatically improve performance on well specified outcomes, even if they aren’t fully verifiable, something that is more or less out of scope for long running agents without strong evaluators.
This is a tremendously exciting area and one where I think we’re going to see forward looking data teams putting things like this into practice in the near future, with broad adoption not too far behind that. As always, if you’re working on something like this in the dbt world - I’d love to speak to you (and if you’ve got something really cool - bring you out to demo it at dbt Summit later this year).