
In Search of New Standards
The Modern Data Stack needs to coalesce around standards beyond SQL to solve the practitioner problems of today.
The modern data stack is a massive new paradigm for how data is processed. It was able to emerge so quickly because new entrants entered the existing ecosystem permissionlessly. Vendors saw an opportunity, capital flooded in, early adopters got excited, and a decade later data works totally differently. No one got permission from anyone.
Permissionless ecosystem construction always has to emerge around a standard. That standard doesn’t have to be a “technical” standard—the global supply chain emerged around the standard of the shipping container. In the case of the modern data stack, the standard that the entire ecosystem emerged around was SQL. SQL has been around forever and is widely supported in the data ecosystem, so early MDS vendors were able to bootstrap their products into being interoperable with existing technologies.
The fact that these early vendors were able to interoperate with existing technologies meant that they could grow really quickly inside of large, already-existing install bases. Redshift was easy to adopt because you were already pointing your BI tool at something, so now you can just point it at something that is faster. Etc.
All of this was great—it has been great for the growth of the ecosystem, for practitioners, for vendors… But SQL as a standard to interoperate only goes so far. All of these tools know how to exchange data with one another, but these tools know very little about that data. Is it fresh? Is it accurate? Who produced it? From what input data was it produced? What exactly does it mean? How much did it cost to produce? And more.
These questions are metadata—data about the data. And SQL-as-a-standard doesn’t help you answer them. SQL knows about rows and columns but not provenance or semantic meaning.
This means that the modern data stack does a pretty poor job at answering them, because
SQL is the only standard binding the modern data stack together today, and
these metadata questions fundamentally span the boundaries of any individual product.
This status quo causes real practitioner pain today. Whereas the problems of a decade ago were things like:
How do I performantly store and process a lot of data?
How do I create data systems that don’t require massive technical expertise to operate?
How do I move fast enough to give the business the data that it needs?
Today, problems on the ground are largely related to the complexity that has been created by the MDS. This is normal and to be expected! The state we’re in feels to me very reminiscent of the pre-Google web, where you had to keep a mental map of where all of the “good stuff” on the internet was hiding. Maybe the pattern here looks something like this:
Step 1: invent a technology that creates new raw technical capabilities (HTTP, HTML, TCP/IP, the browser) but creates a profusion of poorly organized new “stuff.”
Step 2: create a technology that helps you better index / organize / make sense of that “stuff” (web search).
The complexity problems we’re experiencing today are all the metadata questions that I mentioned before. One simple case of how this plays out that will likely be familiar to you. In a sufficiently complex organization, it is not good enough to find a table called customers in your warehouse—you need to know how it was produced, who built it, when it was updated, etc. in order to make use of it. And if that metadata either doesn’t exist or is locked up inside a tool that you don’t have access to then that dataset is completely useless to you.
The above is just a simple example—metadata for use in data discovery—but metadata is relevant in essentially every data job-to-be-done. Investigating data quality issues. Refactoring pipelines. Provisioning access to data assets. Creating metric consistency. On and on and on. Every single job-to-be-done needs a similar set of metadata and right now there are no standards to catalog and exchange this metadata that have been adopted by the vendor ecosystem.
This is where we’re at as an industry—we’re great at ingestion, storage, compute, and transformation, but we’re not doing a great job of managing the chaos that has been unleashed. We’re not giving users the metadata they need, in the place they need it, to make use of these capabilities to their fullest.
The funny thing is…metadata questions are not in and of themselves so complicated. It is certainly possible to create systems that answer these questions. And many companies have—companies like Airbnb and Uber and Google and Facebook are famous for their internal bespoke data systems that do a decent job at this.
Instead, the hard problem is: how do you get an entire ecosystem of vendors to build products that answer these questions? Vendor ecosystems require standards to coalesce around in order to answer questions like this because there is no top-down authority that can enforce consistency. Absent a widely-adopted standard, these problems will remain unsolved.
This is one of the reasons that some folks in our space have suggested that industry consolidation is coming for the MDS. If you can’t get a set of disparate products to integrate more tightly together to deliver the necessary UX, maybe it’s more achievable for a single company to create a tightly integrated, end-to-end solution!
This is certainly a path, and I’m sure it’s one that will be (is being) pursued by at least a couple of companies. But I’m not sure that it’s the one that I personally would like to see dominate our industry’s future. I do, however, think it’s a useful starting point for a thought experiment. To wit:
🤔 Over the next decade, the “metadata problem” will be solved. There is too much user demand for this to not happen. It will either be solved by product integrations in an open ecosystem (requiring standards) or via commercial consolidation. If we knew a priori that this were going to happen via standards in an open ecosystem, what’s the most likely way in which that would have come to pass?
I need to do more thinking and writing about this. The short version is that I think we—vendors and practitioners alike—have both an opportunity and responsibility to truly engage with this topic and advocate on behalf new metadata-focused standards. Standards typically come into existence via the collaboration of a set of parties with a shared mutual interest, and I think there are now enough folks with sufficient mutual interest to engage in this thought process.
Two years ago this likely wasn’t the case, but I think today it is. Honestly…I’m ready for it. Feels exciting.
From elsewhere on the internet…
Madison at Learn Analytics Engineering featured dbt Labs’ own Amy Chen in a new series called “Off the Beaten Path”. In it, Amy discusses their unique journey getting into data, struggles with imposter syndrome, and more. Regardless of your exact path, you’ll likely find a lot to identify with in the post.
One of my favorite things about data as a profession is that it is both well-compensated and quite accessible. As Amy’s journey highlights, it doesn’t actually take an advanced degree in a particular field or even a bootcamp! Sometimes you just need Mode’s SQL School and an environment that is excited to support your growth :D
Amy—thanks for all you do!
A recent Reddit thread—The current and future state of AI/ML is shockingly demoralizing with little hope of redemption—got a ton of quality engagement. I’m personally not as demoralized by the state of AI/ML, but at the same time I try to stay away from opining on areas that I’m not an expert in. The original post is interesting, but what makes this noteworthy is the comments below. Lots of folks actually stepped up to the plate to make what I believe to be very fair counterarguments. And the poster who used AI to summarize the post made me lol.
The overall question of “should we feel good or bad about the direction of AI/ML?” is an interesting one, and certainly fun to think and talk about. I do largely agree with the author, though, that our thoughts and feelings may only have marginal impact on the way history unfolds:
If you’re a company, how do you standby and let your competitors aggressively push their AutoML solutions into more and more markets without putting out your own? Moreover, if you’re a manager or thought leader in this field like Jeff Dean how do you justify to your own boss and your shareholders your team’s billions of dollars in AI investment while simultaneously balancing ethical concerns? You can’t – the only answer is bigger and bigger models, more and more applications, more and more data, and more and more automation, and then automating that even further. If you’re a country like the US, how do responsibly develop AI while your competitors like China single-mindedly push full steam ahead without an iota of ethical concern to replace you in numerous areas in global power dynamics? Once again, failing to compete would be pre-emptively admitting defeat.
I’m curious in your thoughts on what the analytics engineering community’s participation in this conversation should be. Generally, we do minimal AI/ML work. But my belief is that industry trends certainly would have the pipelines that we build feeding into more and more organizational AI/ML models and the practitioners becoming much closer together. Are you excited about that prospect?
Monte Carlo just surveyed 300 data professionals. Full report is here but here’s a fun tidbit:
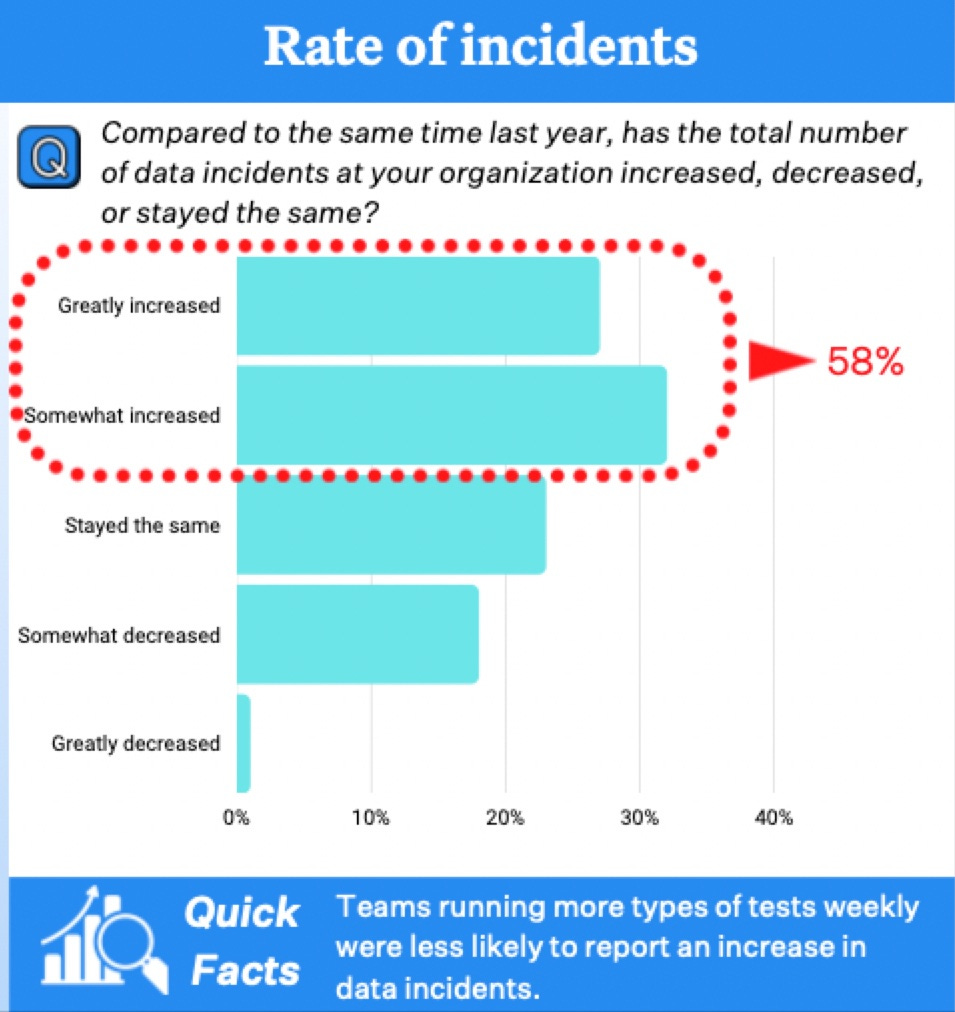
Benn wants to stop thinking about jobs. Me too, Benn…me too.
Pedram is back with part 2 in one of my favorite nuts-and-bolts series ever! In this post he discusses the dark art of user stitching…which may be my single favorite area of analytics engineering. It’s one of those magical instances where you can truly dig into the very deep complexity on a single topic and emerge with a single field—user id—that suddenly shows up on all of your web-related models, and it just works. No one else has to know how much work went into constructing it!
Also from Pedram: live tweeting from dbt staging day!
Gleb @ Datafold recently took up the baton from a recent roundup where I said:
Rather than building systems that detect and alert on breakages, build systems that don’t break.
…and he went deep on it. The post is still a master class on how to build resilient data systems. IMO this should be far easier than it is today to actually build, but the principles in this post are dead on.
While not “solving the metadata problem,” I think that a few basic standards can enable BI and other tools to leverage dbt as a full semantic layer. I put together a dbt project to show how this would work: https://github.com/flexanalytics/dbt-business-intelligence
In short, it leverages dbt as a semantic layer to define metrics, dimensions, aggregations, calculations, data relationships, business-friendly names and descriptions, synonyms, formatting and more. Then, BI tools can just plug in without needing to create a metadata/semantic model. “Semantic-free BI”:
https://towardsdatascience.com/semantic-free-is-the-future-of-business-intelligence-27aae1d11563
One big problem is that standards require buy-in from big name vendors to take off, but big name vendors don’t necessarily want to buy in because then you can more easily switch to another vendor. Another problem is that these standards are not “baked in” to dbt, and perhaps they shouldn’t be, but this forces more non-standard usage of dbt’s ‘meta’ tag. Also, the metadata needs to be more “active” with the ability for many roles to update catalogues in a friendly UI (not just YAML).
> Maybe the pattern here looks something like...
Sounds a lot like the "emergent layer" pattern! Where something scarce suddenly becomes abundant, solving one set of problems and moving us on to a new set of constraints. https://medium.com/swlh/emergent-layers-chapter-1-scarcity-abstraction-abundance-5705666e4f15