We are currently accepting proposals for qualified speakers to join us at Coalesce 2024 in Las Vegas! There is SO MUCH changing in data today, and Coalesce is the single biggest stage for you to highlight the amazing ways that you and your data team are innovating in this fast-changing landscape.
I’ve been thinking a lot about AI of late. This is a change—I have mostly resisted this for the past ~16 months. Sure, I’ve mused about it in this space from time to time, and I’ve discussed it internally with employees of dbt Labs in many contexts.
But AI represents a fairly modest (though growing!) percentage of our product roadmap, and it just isn’t my very biggest near-term priority for the world of data analytics on structured data—the world that you and I live in. I think that will change in the coming years (and there are some fun seeds getting planted!), but today I think that’s mostly where we are.
But first I want to build a foundation and share some thinking on several different topics. I’ll start with customers’ priorities for their data capabilities, hit a bunch of AI developments, and circle back around to connect the threads and how dbt will play into this world.
TL;DR: the integration of structured data and AI will be driven by metadata. And dbt’s biggest role to play in the AI revolution will be as the source of truth for that metadata.
Let’s dive in.
First: Customer Data Priorities
I just spent a full day with some of our biggest customers last week. Here are some things I heard from that conversation that totally check out with me:
Their biggest priorities are focused around code quality, data platform spend, end-to-end integrated user experiences and reduction of vendor sprawl, scalability (i.e. how to add more humans to the process of creating and disseminating knowledge), observability, and data trust. These 100% map to my own beliefs about current practitioner priorities throughout the industry.
If AI can help with the above priorities that’s great. Currently, it doesn’t seem like there is much of an intersection between these priorities and AI, however, so our customer panel was mostly not involved in current AI projects at their orgs.
However, there was universal agreement that these folks would *love* to find AI-powered solutions to their problems, in part because that would give them access to special budgets focused on AI experimentation and deployment.
All of this checks out and is healthy. Organizations really do want to push themselves to find nails for this brand new hammer. When done to extremes, this behavior is damaging, but it is important within large companies to push innovation top-down. If you don’t, you will by default get stasis.
But the current challenges these folks are facing don’t feel addressable with current AI tooling. The question is: is that a persistent state—i.e. is AI just not that relevant to analytics problems? Is it just too early yet? Or are there some upstream unlocks that need to happen first?
Second: How Complete is the World Model?
Lex Fridman had a great podcast episode last week with Yann LeCun, the Chief Scientist at Facebook’s AI Research group (FAIR). Yann is probably in the top 5 humans in the world in his knowledge of current AI capabilities and ability to predict future trends; the entire 2+ hour interview is incredible.
Ben Thompson at Stratechery recently wrote about Sora, OpenAI’s video-generation capabilities that have been integrated into the ChatGPT experience.
Both LeCun and Thompson point out the same thing: the underlying world model created by the transformer architecture is simply not sophisticated enough, not good enough at reasoning through causal chains, to perform certain tasks. Here’s one seemingly trivial example of that:
The current model has weaknesses. It may struggle with accurately simulating the physics of a complex scene, and may not understand specific instances of cause and effect. For example, a person might take a bite out of a cookie, but afterward, the cookie may not have a bite mark.
AI can do a lot of things that you can’t do already, but my 4-year-old knows that when you take a bite out of a cookie, the resulting cookie should…have a bite out of it.
LeCun points out that what’s going on here is that the transformer architecture, despite the amazing progress it’s created in the past ~6 years, is not really appropriate for this type of world-model-building. And that the reason that we have such fantastic results on top of generative language models instead of on top of models that need to interact directly with the real world (or simulations thereof) is that language is an already-compressed information stream, whereas real-world environments contain dramatically more data in a totally uncompressed state. Models dealing with the open world need to do far more work to compress the vast amounts of input data, create a world model from it, all before attempting to interact in a meaningful way. And we’ve mostly failed at this larger problem so far.
Maybe passing the bar (today’s achievement) is something like winning at chess—a task that represents what we have always considered to be a Very Hard Intellectual Thing. In fact, however, it turns out to be far simpler than the things we do without even thinking about them (like reasoning about the state of half-eaten cookies).
In this view, transformers and current-generation LLMs have moved very quickly and demonstrated tremendous capability, but aren’t going to be naturally extended to solving other classes of problems. Meaningful net new innovations in model design are required.
Now, we can’t say this for certain. One of the ways the industry has come to communicate uncertainty about the path to artificial general intelligence (AGI) is to say “We’re between 0 and X fundamental breakthroughs to get to AGI” where X is lower for optimists and higher for pessimists. (My X is probably 4.) And so maybe the best way to think about the path to AI + analytics is to communicate what we would need to see to get there.
My answer to that is: reasoning about causality. The core job of a data practitioner is to look through tons of data to answer questions about causality. Not to say “this is true” but rather, “this data suggests that this could be true.” An AI that could do this consistently and effectively would be a massive change to the practice of analytics.
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers’ computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements.
And from the same Lex podcast I mentioned earlier:
Lex Fridman(00:28:38) (…) can JEPA take us to that towards that advanced machine intelligence?
Yann LeCun(00:29:02) Well, so it’s a first step. Okay, so first of all, what’s the difference with generative architectures like LLMs? So LLMs or vision systems that are trained by reconstruction generate the inputs. They generate the original input that is non-corrupted, non-transformed, so you have to predict all the pixels, and there is a huge amount of resources spent in the system to actually predict all those pixels, all the details. In a JEPA, you’re not trying to predict all the pixels, you’re only trying to predict an abstract representation of the inputs. And that’s much easier in many ways. So what the JEPA system, when it’s being trained, is trying to do is extract as much information as possible from the input, but yet only extract information that is relatively easily predictable. So there’s a lot of things in the world that we cannot predict. For example, if you have a self-driving car driving down the street or road, there may be trees around the road and it could be a windy day. So the leaves on the tree are kind moving in kind semi-chaotic, random ways that you can’t predict and you don’t care, you don’t want to predict. So what you want is your encoder to basically eliminate all those details. It’ll tell you there’s moving leaves, but it’s not going to give the details of exactly what’s going on. And so when you do the prediction in representation space, you’re not going to have to predict every single pixel of every leaf. And that not only is a lot simpler, but also, it allows the system to essentially learn an abstract representation of the world where what can be modeled and predicted is preserved and the rest is viewed as noise and eliminated by the encoder.
(00:30:59) So it lifts the level of abstraction of the representation. If you think about this, this is something we do absolutely all the time. Whenever we describe a phenomenon, we describe it at a particular level of abstraction. We don’t always describe every natural phenomenon in terms of quantum field theory. That would be impossible. So we have multiple levels of abstraction to describe what happens in the world, starting from quantum field theory, to atomic theory and molecules and chemistry, materials and all the way up to concrete objects in the real world and things like that. So we can’t just only model everything at the lowest level. And that’s what the idea of JEPA is really about, learn abstract representation in a self-supervised manner, and you can do it hierarchically as well. So that, I think, is an essential component of an intelligent system. And in language, we can get away without doing this because language is already to some level abstract and already has eliminated a lot of information that is not predictable.
These are two different model architectures that are both pulling on the same thread: building more sophisticated conceptual representations and reasoning at that level. I certainly don’t want to assert any particular expertise in evaluating novel model architectures, but this is the first time in a while that I’m seeing this topic get any real attention, and it makes me optimistic that we’re going to see some non-linearity in model capability in the coming couple of years.
Since GPT 3.5 Turbo came out a couple of years ago, we’ve all gotten at least somewhat familiar with LLM capabilities, their reasoning style, what you can and cannot productively ask of them. While the transformer model when scaled can do a hell of a lot, I still think we’re not done experimenting. I am very very interested in trading off some level of linguistic sophistication of the current generation for models that can reason about complex causal chains that the real world requires.
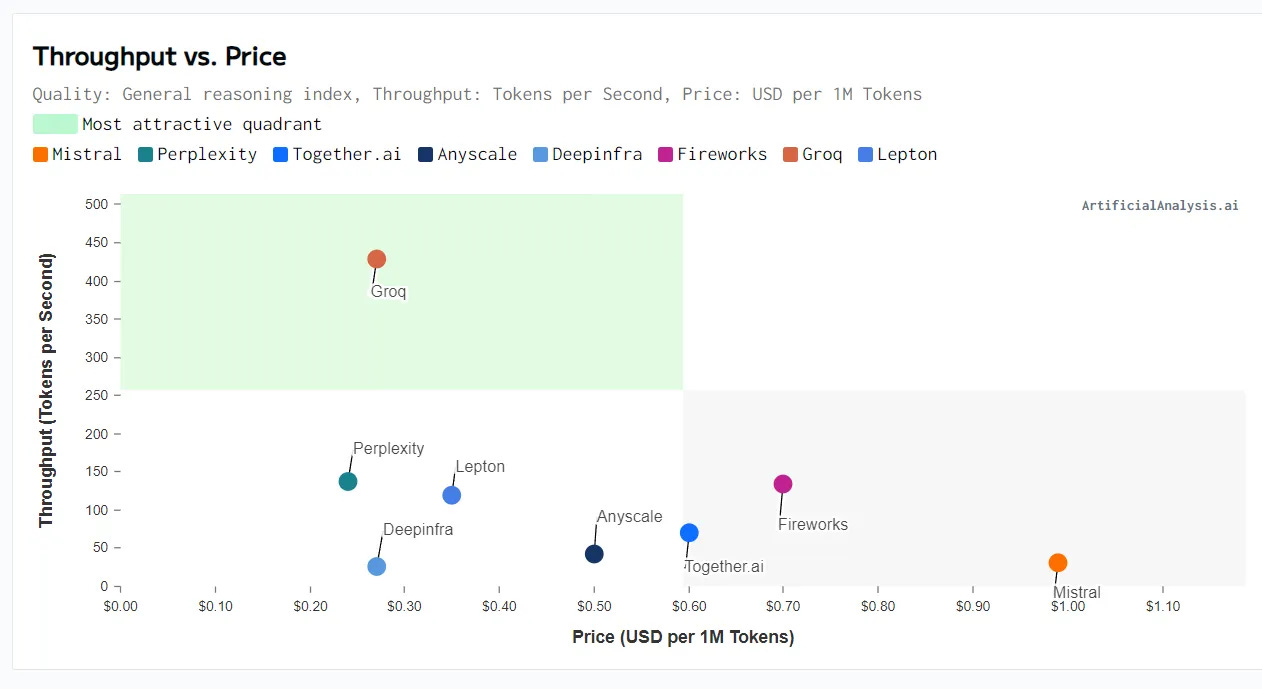
Groq, an AI hardware startup, has been making the rounds recently because of their extremely impressive demos showcasing the leading open-source model, Mistral Mixtral 8x7b on their inference API. They are achieving up to 4x the throughput of other inference services while also charging less than 1/3 that of Mistral themselves.
Try it yourself—it’s really freaking fast. Latency and cost both matter a lot as we start to design more complex, and multi-shot, LLM workloads. The fact that we’re seeing compute architectures optimized for LLM inference all the way from the hardware level up is very encouraging. It’s a very open question as to whether or not Groq’s specific approach (which is an interesting one but beyond the scope of this post) is correct or not, but the fact that we are running this experiment and getting these types of results is very good. It means that the idea space has plenty of untapped opportunity.
Why would we assume that the same hardware architecture necessarily is optimal for both training and inference? These are two dramatically different workloads.
Fifth: AI Design Patterns
Design patterns are established architectural patterns in software engineering. Understand the most common design patterns and how to implement them and you have an incredibly useful thinking tool as a builder of software systems. The canonical book on design patterns, written in 1994, is one of the most widely-taught books on software engineering.
The LLM-as-CPU architecture proposed by Andrej Karpathy (see below) begs the question then, what are the design patterns for software developed for the LLM computer?
Many folks think in one-shot prompting, because that’s how ChatGPT has trained us all to think. Write a really great prompt and then get a genius LLM-powered answer. But that’s not how most LLM-powered processing will work as we build systems of greater complexity.
The first design pattern is the AI query router. A user inputs a query, that query is sent to a router, which is a classifier that categorizes the input.
A recognized query routes to small language model, which tends to be more accurate, more responsive, & less expensive to operate.
If the query is not recognized, a large language model handles it. LLMs much more expensive to operate, but successfully returns answers to a larger variety of queries.
In this way, an AI product can balance cost, performance, & user experience.
One of the design patterns that this article doesn’t discuss but that I think is very central is the planner-executor-integrator pattern. Imagine this sequence:
Ask an LLM to write an outline for a blog post on a certain topic.
Recursively ask the LLM to write content for each bullet of the above outline.
Finally, ask the LLM to integrate all of the above-generated content together, edit it to be in a consistent tone and have good transitions, and write an introduction and conclusion that have personality.
This is a simple example and some version of this is certainly possible with one-shot prompting, but this approach scales far better to harder tasks and produces consistently better-quality outputs. Imagine this approach for asking an LLM to generate code that accomplishes certain functional requirements, and imagine that each of the “bullet points” (subtasks) has their own unit tests and documentation built out and has been individually iteratively debugged.
Overall, I think that AI design patterns are one of the biggest differences between people who understand how to build AI systems and people who just like to talk about AI. Want to build real systems? Start here.
Finally, the Payoff: A Roadmap for AI in Data
Ok, if you’re still with me, let me summarize the above and then draw some conclusions.
We’re starting to play with models that are better at developing high-level concepts and reasoning from these concepts. This is what data practitioners do: pull signal from noise and draw conclusions from it.
Inference costs and latency are going down and the industry is taking big swings to continue this trend.
We are developing better ideas of how to construct AI-powered systems.
Cool. But the problem I identified at the beginning of the post was fundamentally that AI systems are not currently solving the problems that sophisticated data teams actually have today…! Will these advances actually change this underlying fact?
I think it will, if you pair it with a single trend from the data space: the advance of the metadata platform.
Frank Slootman is famous for saying “you can’t have an AI strategy without a data strategy.” I think you cannot have an AI strategy—for analytics—without a metadata strategy.
Certainly, you need underlying data, and you need that data to be consistently accessible to AI systems (likely via semantic interfaces). But more than that, you need an end-to-end metadata layer that can be fed into your AI systems in order to get reliable, trustworthy, nuanced answers. What does that metadata layer need to include?
Your organization’s entire end-to-end DAG
The social graph that overlays the DAG
Human-written documentation
Indicators of trust, including direct human feedback
Usage patterns (i.e. query logs)
System status (i.e. orchestration logs)
Semantic concepts (metrics, entities), the ability to map them to queries, and the ability to map them to each other
Underlying code and git history
…and this is just the obvious stuff. For a second, just imagine this idealized metadata platform. It knows everything there is to know about how data flows through your organization and what it means.
Now pair that with the advances in AI: higher-level conceptual reasoning, performance, and system design.
I think this gets us to a very different place. Today we’re building features like “help me generate documentation for this model.” Tomorrow we will be building features like “help me debug this conversion rate drop.” And that is a VERY different world to be in. Today, AI boosts productivity (which is great!). Tomorrow, AI will generate novel insights that will hit both top and bottom lines of the business.
When is “tomorrow”? I have no idea, and honestly, I don’t care that much. It feels incredibly clear to me that this is the world we’re moving towards, and whether it takes 1 or 5 or 10 years to fully get there the payoff is so big that we just have to be building towards it. There will be plenty of interim value created along the way.
dbt’s role in this journey is to be the source of truth for metadata. To help practitioners build their data systems in a way that generates reliable structured metadata, and then build the universal index of and API for that metadata. We want to incorporate more and more of the above metadata inputs into dbt’s metadata platform that already powers Explorer and to consistently develop more and more AI-powered experiences on top of that treasure trove of context.
I am very bullish about what this will unlock for data practitioners.
Regarding the AI design pattern, we recently proposed Leeroo Orchestrator, which is lightweight LLM that knows when and how to leverage underlying LLM experts to perform a task with the best outcome. Here are some of the outcomes:
State-of-the-art open-source: When leveraging open-source models, the Leeroo Orchestrator establishes itself as the top-performing open-source model on the MMLU benchmark, attaining 76% accuracy — with the same budget as Mixtral (70.6%).
Leeroo open-source vs. GPT3.5: Leeroo Orchestrator open-source achieves GPT3.5 accuracy on the MMLU at almost a fourth of the cost.
Achieving and beyond GPT4 with a fraction of cost: Combining open-source models with GPT4, the Orchestrator nearly matches GPT4’s accuracy at half the cost. Moreover, it even surpasses GPT4’s accuracy with 25% less cost.
Accessible: Leeroo can be served on accessible consumer hardware since it leverages underlying models of small sizes, 7b-34b (e.g., A10 and A100), and can be deployed on any cloud provider or on-prem.
“imagine this idealized metadata platform. It knows everything there is to know about how data flows through your organization and what it means.
Now pair that with the advances in AI: higher-level conceptual reasoning, performance, and system design.”
I wonder how many organizations will be able to make snowflake (or similar) their data store for everything. OR will AI enable a more data lakehouse approach where the AI tools connect to data where it already lives?



Regarding the AI design pattern, we recently proposed Leeroo Orchestrator, which is lightweight LLM that knows when and how to leverage underlying LLM experts to perform a task with the best outcome. Here are some of the outcomes:
State-of-the-art open-source: When leveraging open-source models, the Leeroo Orchestrator establishes itself as the top-performing open-source model on the MMLU benchmark, attaining 76% accuracy — with the same budget as Mixtral (70.6%).
Leeroo open-source vs. GPT3.5: Leeroo Orchestrator open-source achieves GPT3.5 accuracy on the MMLU at almost a fourth of the cost.
Achieving and beyond GPT4 with a fraction of cost: Combining open-source models with GPT4, the Orchestrator nearly matches GPT4’s accuracy at half the cost. Moreover, it even surpasses GPT4’s accuracy with 25% less cost.
Accessible: Leeroo can be served on accessible consumer hardware since it leverages underlying models of small sizes, 7b-34b (e.g., A10 and A100), and can be deployed on any cloud provider or on-prem.
More info in: https://www.leeroo.com/
“imagine this idealized metadata platform. It knows everything there is to know about how data flows through your organization and what it means.
Now pair that with the advances in AI: higher-level conceptual reasoning, performance, and system design.”
I wonder how many organizations will be able to make snowflake (or similar) their data store for everything. OR will AI enable a more data lakehouse approach where the AI tools connect to data where it already lives?