
Macroeconomics and the data industry
A measured look at what the economy means for data practitioners.

New podcast episode! Julia and I spoke with Kevin Hu of Metaplane. Whether you’re mapping the emerging data observability landscape or just love a good physics metaphor, give it a listen.
Enjoy the issue!
- Tristan
If you’re a subscriber to this newsletter, presumably you enjoy reading overly-long posts about a topic—data—that most people find rather, let’s say, dry. Today I’m going to up the ante. Let’s see if you’ll follow me on an adventure to an even more dry topic: macroeconomics!
I know, I’m pushing my luck. Just stick with me for a minute and I promise it’ll go somewhere. Let’s start somewhere that we can hopefully all agree on: macroeconomics are driving the modern data landscape.
Innovation in tools and innovation in practitioner workflows happen in symbiosis with one another.
Communities spring up around this innovation to support and share it.
Much of this innovation is (currently) supported by VC dollars.
VC dollars have flowed into the space not just because it is a compelling market opportunity, but because the macroeconomics have been very attractive.
If you don’t spend a lot of time in the headspace of #4, that is a good thing—I try to spend as little time there as possible without committing dereliction of duty. But it does matter. Without going all Bernanke on you, let me just briefly summarize as:
Global pandemic leads to economic stimulus (both fiscal and monetary).
Interest rates go to zero and sometimes below on an inflation-adjusted (“real”) basis.
Capital desperately searches for growth somewhere.
Because VC as an asset class is one of the places that is still delivering growth, dollars get dumped into VC en masse.
VCs need to figure out how to deploy those dollars. Maybe some additional startups get funded; mostly, the same ones get funded but at increasingly high valuations.
This great summary from Pitchbook shows this story quantitatively—it’s a fantastic example of storytelling in data.
To be clear, it is not at all lost on me that dbt Labs is a part of this story. Absent these macroeconomic conditions, we’d certainly still be doing well as a business but our last two years would’ve certainly manifested themselves differently.
These conditions are neither exclusively bad nor exclusively good for practitioners or the industry as a whole. On the good side, you get lots of capital to build new useful stuff, from tooling to supporting workflows to the seeds of communities. On the bad side you get:
froth (the rate of change and level of hype are such that it’s hard to track what is real and what will vanish in two years),
brain drain (the migration of talented practitioners towards starting or working at tooling companies), and
culture change (startup / VC culture becomes much more interwoven into the community as a whole).
It’s important to acknowledge both the good and the bad, but I don’t think there’s some underlying moral dimension here—we shouldn’t be “happy” or “upset” about this on the whole, it’s just a part of the Carlota Perez cycle:
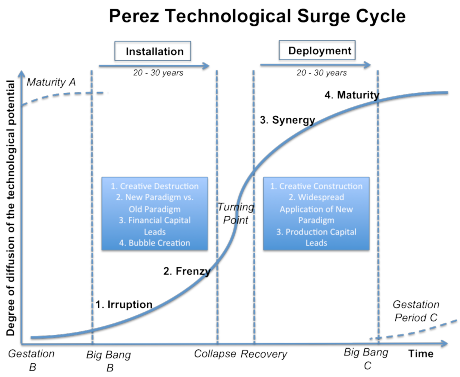
It’s possible (IMO likely) that the last two years have been the “frenzy” stage, with valuations exceeding 100x forward revenue. And now, with economic conditions changing—inflation, increasing interest rates, public software multiples contracting—we’ll likely see a pull-back. VC as an asset class will become, while still attractive, less compelling on a relative basis. Valuations will likely see some reversion to the historical mean. This will take time, as fundraising and investing cycles are long, but it will happen. There will be some companies who don’t make it through this transition and it will impact the entire industry, even for companies who are fundamentally healthy.
And that’s purely a story about capital supply—there’s a whole separate story about the demand for data products. Given that the Fed will slow the economy by increasing rates (to combat rising inflation), will it push the economy into an outright recession? Maybe—smarter people than me certainly think so. And if that happens, will data budgets get downsized across the industry? This is hard to say, but it’s certainly reasonable to believe that some will.
Talk to me about why should I care again?
There’s nothing worse than startup people talking about macro. Get five founders in a room and they’re either going to talk about acquisitions or interest rates—this is one reason I’m grateful to live outside of a major startup hub (my friends don’t really understand what I do). So let’s get to the goddamn point already.
The macro environment will impact your life as a practitioner. And not just because you’ll get lower quality VC-funded swag at the next Data Council. It’ll change a lot more than that.
Cloud spend.
Are you good at measuring and attributing your spend across the modern data stack? No? Very few of us are. Our data team is truly fantastic and we’re not good at this—there’s always been higher priority work to do!
Well, now’s the time. Know where your spend is going across the entire stack and figure out what’s useful and what’s not useful. Kill those scheduled dashboard refreshes and dbt models and Fivetran replications that you’re not using. Make sure you have lineage in place that allows you to know what is used and what isn’t. Install Gitlab’s Snowflake Spend dbt package.
Our entire industry has been euphorically spending more and more on all layers of the stack. I still believe we have a decade or more of massive growth in front of us, but it’s an appropriate time to also inject a bit more maturity in how we track and evaluate costs.
I am actually very excited about this—it’s a part of growing up as a profession! We will actually understand ourselves and our workloads better by applying this type of scrutiny.
Data team headcount costs.
Have you ever been employed at a company where it didn’t really seem like your boss knew or cared that much about what you did and you wondered “Why exactly are you paying me if you don’t seem to care about my work?” I’ve been there. That’s a low-scrutiny environment, and it’s not good for you or your career. That happens because in low-scrutiny times it’s easier to just ignore problems than it is to correct them. No one likes to upset the apple cart if they can avoid it.
I’m going to say something that some of you may not want to hear: I think that there is too little scrutiny of the value of data teams today. Six years ago I had to fight like hell to convince some startups that they should hire any full-time data people at all; today I run into data people who feel like they don’t totally understand how their work maps to the priorities of the business, whose time is not prioritized well. I talk to folks who have started to think of their outputs as ticket completion or model creation, not as business problems solved. Others spend major chunks of their time blocked and waiting on upstream dependencies.
These are talented data professionals who care about their work. But they’re working inside of organizations who don’t consider this inefficiency to be a big problem.
You should want your company to care tremendously about the value you create. You want your stakeholders to care about your work, and you want them to fight like hell to keep your salary in the budget. You want people to be stressed when your project is late because it is that important. All of that pressure is what gets you exposure and promotions. Careers are made out of producing value for the business. And that requires tough choices and hard conversations.
We’ve historically had very hand-wave-y conversations about the ROI of data teams. Certainly, we aren’t about to start attributing dollars of profit to individual feats of analytical heroics—that shouldn’t be the goal. But the honest truth is that no organization can do this perfectly.
Instead, every functional area of the business has certain accepted metrics and benchmarks that they use to evaluate efficiency / ROI. These are often framed as a percent of revenue (for cost centers) or a percent of new sales / bookings (for revenue-generating functions). Some are framed on a per-employee basis (for example, IT).
Each of these metrics can generally be produced using data from your finance and accounting organization, and companies typically do benchmarking exercises to compare themselves to a set of peers that have similar-ish business models in similar-ish industries. This is how you know if you’re “spending too much” on something.
Tell me if you’ve ever been a part of a process like this for your data team. Most of us haven’t. Data team budgets typically get rolled up inside of overall G&A spend and aren’t allocated particularly rigorously. That’s simply a sign that our field isn’t sitting at the grownup table quite yet. We should want this level of maturity, because it’s conversations like this and scrutiny like this that actually allow us to make ever-larger claims on the resources of our organizations. If we want $$$ budgets, we gotta make quantitative arguments for them.
For now, I don’t want to try to make a coherent argument as to exactly how this could or should be done, but I do think we should (and will be forced to!) start doing more here.
Don’t overcorrect!
I’m not down on data (far from it) and I’m not suggesting that we should “pull back” or “put on the brakes” or any such thing. But in the last several years of (justified!) euphoria, we may not have paid as much attention to the cost side of the equation as to our massive increase in capability.
As macroeconomic conditions start to shift, it is a great time to apply just a bit more scrutiny. It’ll be very good for all of us in the long run.
From elsewhere on the internet…
Stephen Bailey did it again. Seven posts into his new Substack and I’ve laughed, I’ve cried (or at least teared up), and I’ve learned so much. In this most recent post Stephen posts a fictional story about an internal news publication, painting a picture of what knowledge transmission could look like inside of your company. It almost definitely does not look like this today.
That’s ok—ours doesn’t either, and I think it’s actually quite rare for companies to be good at this. I have a lot more to say on this topic but will have to save it for a more detailed topic in a future issue, but I think it’s possible that there is a whole set of activities within a company that could be done but today are not. I think these things sound something like: storytelling, culture formation, “internal journalism”. We are starting to feel the lack of these things at dbt Labs and it’s something I’m increasingly focused on in the coming months. I’ll share more as we move forwards, but for now, I agree with what I think Stephen’s perspective is that this is a very data-team-adjacent job to be done.
Benn thinks we have gotten more boring and that’s a good thing. It’s a fun article and I agree with a lot of it. I also think it may not be fair to criticize early hype for something that eventually becomes very practical—hype is useful to change the conversation! I certainly am glad to be a part of the boring phase of the industry’s journey though :P
Everyone is buying, or becoming, a reverse ETL tool? dbt Labs is supposed to buy an ingestion tool?
Joe: neither of those things is happening! Hah. Although I’m not betting against a wave of consolidation.
Fantastic thread from Abhi on how he has designed the data org and its relationship with business stakeholders. Potentially the single best thing I’ve ever read on this, it’s far better than the generic “embedded vs. centralized” debate, with real guidance on how to navigate the hard problems.
I just learned about Patch this week. Here’s the description from their site:
Patch's unified API for cached queries, events, and mutations bridges the gap between the data warehouse and applications, shrinking development time, reducing overhead, and limiting costs.
Call me curious. This is the type of capability that will need to exist if we are to truly see applications built on top of data warehouses.
David J discusses what we need to see a data framework that is fully-featured in the way that Django or Rails are for web dev. This is a metaphor I use in my brain pretty frequently and I think is instructive at imagining the future of the space. The best place to go to imagine the future of data is still the current world of software.