
Orchestration with Dagster. End-to-End Data Scientists. Snowflake's S-1. Experimentation @ Stitch Fix. [DSR #233]

❤️ Want to support this project? Forward this email to three friends!
🚀 Forwarded this from a friend? Sign up to the Data Science Roundup here.
This week's best data science articles
Dagster: The Data Orchestrator
In the status quo, traditional workflow engines such as Airflow work with a purely operational dependency graph: ensuring proper execution order, managing retries, consolidating logging, and so forth. These systems were a huge step forward over loosely coupled cron jobs and other solutions that did not formally define dependencies. A narrow focus on execution allowed those systems to be maximally general while demanding minimal change to the code that they orchestrated.
Dagster makes different tradeoffs, enabling a more structured programming model that exposes a richer, semantically aware graph.
I first introduced Dagster to this list about a year ago when it first launched. Since then, the project has come a long way. This post describes the thinking behind the project and how it’s different than using something like Airflow. But to be honest, I didn’t really get it until I saw a demo of dbt + Dagster being used together by a mutual customer—I was really impressed.
The two paragraphs above are the meat of the value for me: Dagster actually understands the computations that it is responsible for executing because it has a type system. In building dbt, we have found that understanding what type of computation is being expressed to be a critical design element in building a usable system, and this difference is at the heart of Dagster’s value.
Unpopular view: Data scientists should be more end-to-end.
While this is frowned upon (too generalist!), I've seen it lead to more context, faster iteration, greater innovation—more value, faster.
More details and Stitch Fix & Netflix's experience 👇
https://t.co/aOBjuBSsSz
The above-linked post is fantastic. Here’s the authors intro, strongly recommended if this resonates with you:
Recently, I came across a Reddit thread on the different roles in data science and machine learning, such as data scientist, decision scientist, product data scientist, data engineer, machine learning engineer, machine learning tooling engineer, AI architect, etc.
I found this worrying. It’s difficult to be effective when the data science process (problem framing, data engineering, ML, deployment/maintenance) is split across different people. It leads to coordination overhead, diffusion of responsibility, and lack of a big picture view.
IMHO, I believe data scientists can be more effective by being end-to-end. Here, I’ll discuss the benefits and counter-arguments, how to become end-to-end, and the experiences of Stitch Fix and Netflix.
Stitch Fix: Large Scale Experimentation
A core aspect of data science is that decisions are made based on data, not (a-priori) beliefs. We ship changes to products or algorithms because they outperform the status quo in experiments. This has made experimentation rather popular across data driven companies. The experiments most companies run today are based on classical statistical techniques, in particular null hypothesis statistical testing. There, the focus is on analyzing a single experiment that is sufficiently powered. However, these techniques ignore one crucial aspect that is prevalent in many contemporary settings: we have many experiments to run and this introduces an opportunity cost: every time we assign an observation to one experiment, we lose the opportunity to assign it to another.
We propose a new setting where we want to find “winning interventions” as quickly as possible in terms of samples used. This captures the trade-off between current and future experiments and gives new insights into when to stop experiments. In particular, we argue that experiments that do not look promising should be halted much more quickly than one would think, an effect we call the paradox of power. We also discuss additional benefits from our modeling approach: it’s easier to interpret for non-experts, peeking is valid, and we avoid the trap of insignificant statistical significance.
😲😲
This is an incredibly good post. If you do A/B testing, you should absolutely read all the way to the end. I wish I had this post about 7 years ago.
multithreaded.stitchfix.com • Share
Highly valued software startup Snowflake files for IPO
Snowflake Inc., an enterprise-software startup valued at more than $3 billion by private investors, is planning an initial public offering.
Snowflake has done a lot to improve the lives of data analysts like me. Good luck on day one of trading, folks!
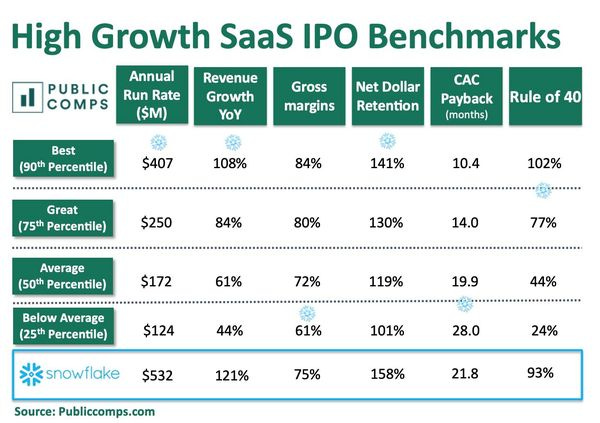
Good teardown of the S-1 here. The most interesting section of this post is the image below.
How FiveThirtyEight’s 2020 Presidential Forecast Works—And What’s Different Because Of COVID-19
I’m largely staying away from talking about data related to the 2020 US presidential election. This is such a fraught topic for almost everyone that I know that I just don’t feel like it needs to take over every aspect of my life.
I did, however, really enjoy reading this post from Nate Silver. I absolutely believe that FiveThirtyEight has had the best election forecasts for years (very much including 2016), and I really enjoyed learning how the team has been updating their model for the 2020 election. If you anticipate checking these forecasts on any kind of regular basis in the coming months, this article is highly recommended.
New Tools I'm Watching
I’m always monitoring the data tooling landscape, and I figured I’d start sharing some of the more interesting products I come across.
Noria: “Noria is a new streaming data-flow system designed to act as a fast storage backend for read-heavy web applications(…). It acts like a database, but precomputes and caches relational query results so that reads are blazingly fast.”
Soda: Another product in the quickly-developing data quality space. I don’t have a ton of insight into Soda specifically but this is a space that is moving quickly and is very interesting to me.
Thanks to our sponsors!
dbt: Your Entire Analytics Engineering Workflow
Analytics engineering is the data transformation work that happens between loading data into your warehouse and analyzing it. dbt allows anyone comfortable with SQL to own that workflow.
The internet's most useful data science articles. Curated with ❤️ by Tristan Handy.
If you don't want these updates anymore, please unsubscribe here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue
915 Spring Garden St., Suite 500, Philadelphia, PA 19123