Recovering from the Party
Coalesce 2024 was our biggest, announc-iest show yet. Here are my notes from the afterglow.

Coalesce 2024 was the fifth Coalesce. Every year gets a little tighter, a little bigger. And as we build our innovation engine and mature the underlying platform, the product announcements get ever-more-significant.
We’re only a couple of days out from the event so I don’t have stats to share here. But if you’ve been to a few Coalesces, I will say that I think Benn does a really fantastic job of summarizing the journey that the event has taken over the last five years. I don’t want to endorse every single thing in his post, but his core point—the transition from purely-community-vibes to yes-AND-also-with-ROI—is spot on. Travel budgets in 2022 were bountiful; if we still wanted people to show up in 2023 and 2024 we needed to demonstrate real ROI from the event.
Fortunately, ROI doesn’t need to crowd out the quirky, the playful, the unique. We can build relationships, safeguard the dbt Community’s special place in the ecosystem, and still get shit done.
Speaking of special, the photo below is almost too much for me. We had a spot in the Discovery Hall where we asked users how dbt has changed their careers and their lives. The responses were 😭😭😭
I realize that you cannot actually read the notes that folks left in this picture, but if you took the time to stop and write, please know that this is the stuff that keeps me and everyone at dbt Labs showing up at work every day. Thank you. So much 💜

Ok, on to the announcements.
What Shipped at Coalesce 2024?
This year was by far our biggest year for product announcements. If you want the entire laundry list, find it here—there’s way too much for me to hit in this newsletter.
There were four big product themes: trust, collaboration, cross-platform, and AI. We expanded on our vision for the Data Control Plane:
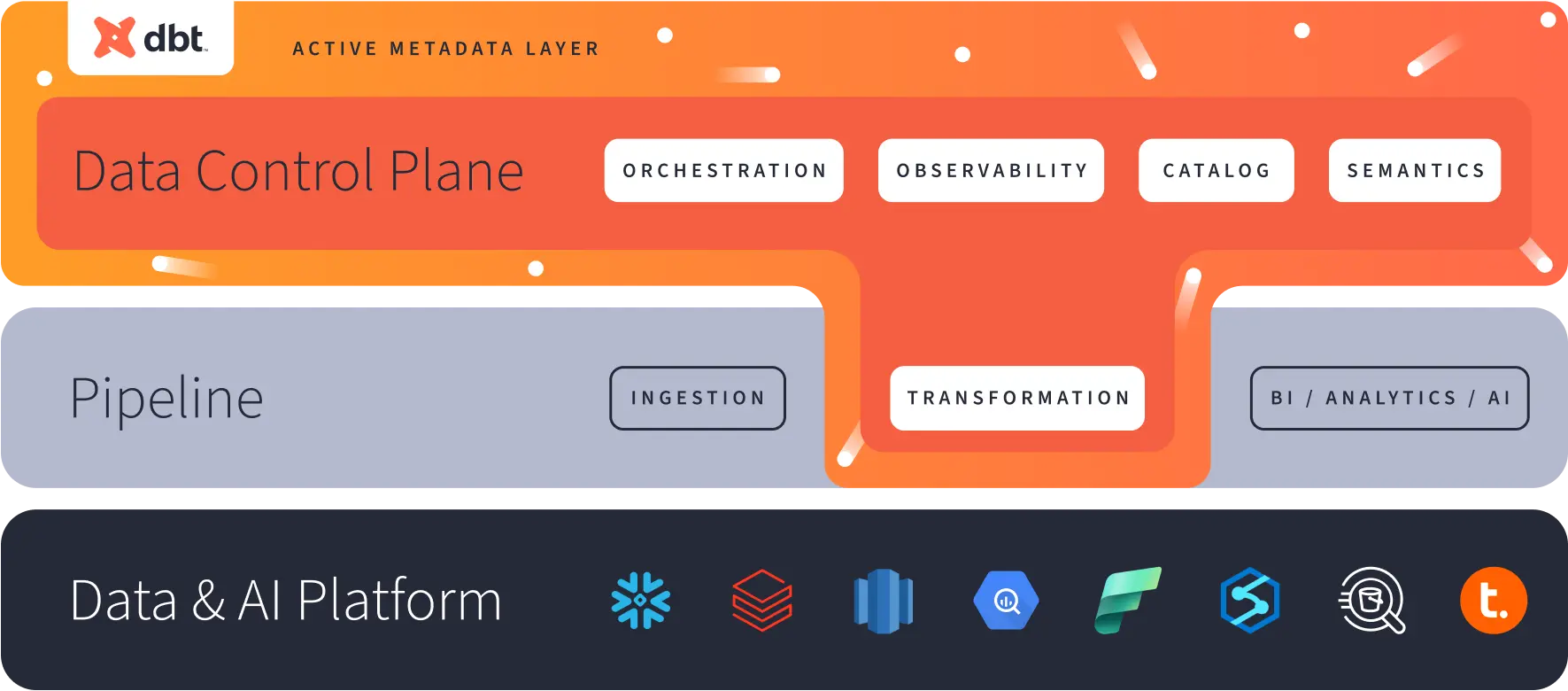
And we wrapped all of this up into the singular theme of the entire conference: One dbt.
But I’ll need to say more about One another day because…there is just a lot to say about it. For today I want to focus on the product announcements.
Here’s the summary slide of the product keynote, hitting the various product announcements by theme:

Not to pick favorite children, but here are the things I think are the most critical.
Visual editor
We welcomed new users into a visual editing experience that allows them to write dbt code using a drag and drop interface. This interface both reads and writes native dbt code, and therefore brings a brand new set of personas—less technical data practitioners—into the mature, governed, ADLC in a first-class way.
This announcement got the biggest response of any announcement at the show. Almost everyone I spoke to throughout the week said “I have people at my company that I want to give that to.”
I have never understood the “data prep” space as a standalone category. It seems like a space that has been stuck in time roughly a decade ago. Over the past year, many of our biggest customers have been asking us to help them solve their “data prep problem” (their words!). It shows up for them in two specific ways. First, license costs are high and only going up. Second, governance characteristics of these systems are incredibly low as they don’t conform to ADLC best practices AND they often need to pull data (including SPI) locally in order to operate on it. Having dozens or thousands of these licenses floating around inside your company is a real risk and we developed the dbt Cloud visual editing experience in direct response to customers asking for help mitigating this risk.
This will be a multi-year investment for us; expect to continue to see innovations from us in this space.
Cross-platform dbt Mesh
dbt Mesh was the biggest announcement of Coalesce 23, and this year we gave it a major upgrade. Downstream nodes in a mesh can now be built on upstream nodes from a different data platform. Redshift can `ref()` Athena (etc). All of the implementation details are abstracted away; just use a two-argument ref statement and it all just works.
As we shared on stage, over half of our enterprise customers have dbt running on at least two data platforms.
I fundamentally do not believe we are going to see one, or even two, winners in the data platform space. This is not Windows in the ‘90s, or even iOS and Android in 2012: the data platform ecosystem is not a monopoly or a duopoly; at best it is an oligopoly with 6-10 real players. But in reality I think it is better to just think about it as a competitive market.
This is good for users—no one needs the Oracle-vs-Microsoft dynamic that existed in 2003 at the start of my career. But it also creates complexity and bifurcation. Because today, different teams that use different data platforms inside the same company typically do not know about or have any access to the data assets that live inside the other platform. This leads to duplication, inefficiency, and inaccuracy.
Under the hood, dbt’s new cross-platform ref capabilities are powered by its support for Iceberg. Iceberg without dbt can be a real pain to use, but I am a huge believer in its ability to move the market in practitioner-favorable ways. I’m delighted by our ability to abstract away the complexity behind a perfectly dbtonic interface.
dbt’s cross-platform capabilities, and its support for open table formats, is still in its early days. I fully expect this to a major area of innovation for us in the coming years as the entire ecosystem is reshaped around this new set of standards.
Two smaller, but lovely, features
The above are what I believe to be the two biggest announcements coming from our biggest innovation themes. But I have two other product announcements that I just love so much that I just have to sneak them in. They are both real, important additions to dbt:
Microbatching allows incremental model authors to load, and backfill, large models in date-based batches. It has been obvious that we would need to support this since all the way back in 2017 when Max B scolded me about dbt’s lack of support for this. All I can say is: we pushed ‘traditional’ incremental models a long way! It was time though. You should definitely implement this ASAP for your very largest tables.
Advanced CI enables users far greater safety when merging a PR. The core of this feature is data diffing—being able to examine the differences of datasets produced in a development schema and the production schema. Zero differences, lots of safety in hitting ‘merge’.
===
Just wanted to share one final thing before hitting ‘send’ this week. I recognize this is a million miles away from sharing Coalesce updates, but still, it’s important.
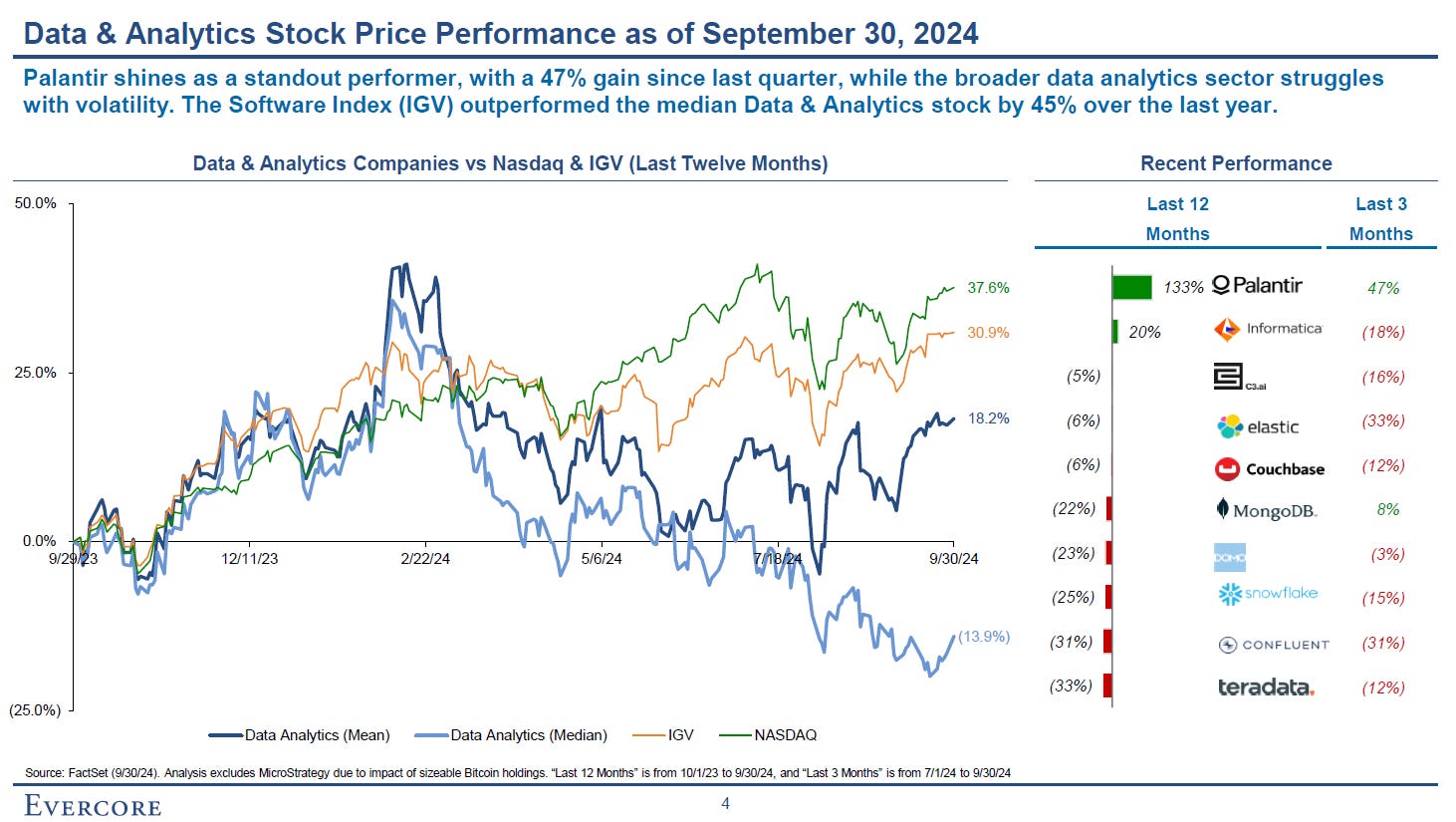
I just now ran across this bit of public market research from our friends at Evercore. I read through this slide and emitted an audible ‘oof’ at one point. The takeaway: it has been a challenging year to be a public company in the analytics space.
I’m not a stock market analyst—I’m here for the products, not to model out enterprise value—so I don’t have anything particularly intelligent to say about this at the moment. I could imagine a whole 60-minute-long podcast episode digging into this dynamic though. Any interesting guest suggestions to talk about this, please send them my way.