
R.I.P. Data Engineering? The entity layer
... and other data stories: where to wire up A/B tests, your first management experience, why Scrum is like the Kardashians, and yes, that NYTimes viz.

Happy New Year 2022! May the only negative things in your life this year be your PCR and rapid antigen tests 🥂
We’ve been off for a couple of weeks, but data thought leadership never sleeps. There’s a lot of ground to cover after the break, so let’s jump right into it shall we? ;)
-Anna
The Future History of Data Engineering
by Matt Arderne
Matt, consider my thought leadership nerve tripped … but in the least satisfying way possible. I’ve read this carefully several times now, and can’t find a good opening to throw a punch 🥊
Instead, let me channel that energy towards aggressive nodding:
Nearly every company needs a data person […] But the premise is that that [first data] person no longer needs to be a Data Engineer.
✅ If you’re a business getting started utilizing data in decision making, moving data around and making it accessible is no longer the first problem you need to solve before business insights can be generated. Most common business software you are using today have a corresponding prepackaged EL solution that will get you most of the way there. And if you are building your first count of monthly active users, most of the way is more than good enough.
If not a Data Engineer, then who? I have special warm fuzzies that Matt thinks it should be a 💜 purple person 💜 — a data generalist “obsessed with business impact”. Stef Olafsdottir happens to agree. Today, we’d probably call this an Analytics Engineer — someone who has survived landed impact with a business function as an Analyst and learned enough in the process to make this impact repeatable through their data models.
What I enjoyed most about Matt’s post is that it is relevant not just to today, but also tomorrow. And tomorrow, this purple generalist might very well be today’s Analyst:
Eventually, analytics engineering could face the same turn of the tide. When the tooling gets so good that the team is composed entirely of analysts and product people, and no contriving engineers.
What does it mean for the tooling to get “so good”? Here Matt doesn’t elaborate, so allow me to ad lib for a hot second:
The bulk of the work that goes into modeling data in the transformation layer today is turning your EL-ed data lake soup into a representation of correct, consistent and trustworthy business entities and metrics used to track your business’ process. Most of the business software that companies are using today is similar (within a segment of company size and shared industry, of course). Most of the questions that company leaders have of their businesses are similar as well — if I’m a product company, what does my user journey look like? Where do my users get stuck? If I am a subscription service, what is my recurring revenue assuming no one churns? What is my churn rate? What are the primary drivers of churn?
It’s not inconceivable that we eventually reach a place where common business entities come pre-modeled alongside common business metrics — a kind of Company 360 in a box. We’re already moving in this direction.
🪦 So is Data Engineering dead, and Analytics Engineering on its way to being dead too in some not too distant future?
No, not at all and I don’t think this is what Matt is saying. Challenging Data Engineering problems will continue to exist at scale in contexts where information needs are highly specialized, such as in large enterprises and in companies that lean on data heavily in their products (although in the latter, you might find Data Engineering hiding under the guise of Machine Learning Engineering). Matt makes a good case here so I invite you to read the original for the details.
Similarly, Analytics Engineering will continue to be relevant for a long time. As the number of different industries that adopt the modern data stack increase, so too will the modeling problems that come with them — new entities, new success metrics. Until they too become common enough to encourage shared solutions to be built that allow everyone in the industry to move up the stack.
I’m excited about this revolution. And I’m even more excited about figuring out the how, which is the subject of today’s second featured post.
The Entity Layer: data's trillion dollar question mark
by Benn Stancil
This is not your average obligatory Benn Stancil mention. While Matt got me to take out my boxing gloves earlier, Benn got me to use them ;)
Before we get to the punches, let’s start with what this “entity” layer is and how it’s different from the “metrics” layer we’ve been talking about.
[An entity is] an object, with meaning tacked on. Entities are semantic objects first, and tables second. And just as metrics layers encourage teams to canonize one version of a metric, an entity layer could pressure teams to do the same with other semantic concepts.
Metrics: Daily/Monthly Active Users, Net Dollar Retention, Monthly/Annual Recurring Revenue, Churn Rate, Conversion Rate, etc.
Entities: “User” (the human using your product), “Customer” (the legal entity you are doing business with), “Account” (the representation of your user and/or customer in your product) are the most common semantic concepts a business shares.
If the metrics layer is a shared representation of (for example) ARR that the entire business can query, slice and dice in a centralized way, then the entity layer is a shared representation of (again, for example) information about your Customer that the entire business can leverage. Examples of where an entity layer is incredibly handy: who is the billing contact for this customer? If you are used to working with your product data, you might come across an administrative and unattended mailbox in account settings. You may not know that in Salesforce, there is likely a human listed that has all the context of the deal that was signed with your business. Much more useful!
Seems simple enough, then. Ship it.
Except there are also entities that are unique to a business. As an example, dbt Labs has the concept of a “Project”. In terms of what a Project is in the product: a directory that tells dbt everything about what it needs to do. But in terms of what a Project means to understanding the business, a Project is a representation of a unit of collaboration between users. In other words, a Project has a one-to-many relationship with users. A user has a (possibly!) one-to-many relationship with an account, except for accounts that are limited to one user. And an account can have a one-to-many relationship with a customer, if you’re doing business with a large enterprise that prefers to keep administration of your service decentralized across several teams.
🤯
Let’s go even further.
Entities will likely have specific relationships with only certain metrics. For example, ARR is always meaningful in the context of a Customer if you are a subscription business, but not always meaningful in the context of a User, if some of your product users are on a free tier. Do you leave out the ARR field entirely from your User representation? But what if you want to know how many humans from some of your biggest customers attended an event you just hosted? Do you set it to 0 for folks who aren’t paying you? What about folks who have churned? Suspended their payments temporarily? Should it be Null?
🤯 🤯
One more and I promise I’ll stop.
Aggregations over metrics may be handled differently, depending on the relationship between business entities. If you have self-serve customers (customers who are paying you directly via some payment system, and don’t have a sales relationship), you might be aggregating ARR at an Account level since that’s the entity your billing is tied to. But if you also have an Enterprise product with customers who are managed by a Sales team, you’d want to aggregate ARR at a Customer level since that’s how the customer prefers to be billed.
But what if your Customer has a one-to-many relationship with Accounts in your product? You could mirror ARR across Customer and Account entities, but if you’re not careful, you can end up overcounting ARR when you do aggregations. Do you then divide the ARR equally among the many accounts a Customer has?
🤯 🤯 🤯
This is not a post about the intricacies of modeling company financial metrics, but hopefully I am getting across the point that with entities and metrics, the devil is in the details. Or in this case, the relationships.
What is important here is those types of scenarios are not edge cases of a large business, but challenges nearly any company will have if they offer an easy to get started subscription based service that wants to scale to work with larger companies. In other words, any SaaS business.
Does this mean metrics and entity layers are dead in the water?
Not at all. But I think this does mean a few things:
The entity layer is not a replacement / improvement over a metrics layer (to be clear, I don’t think that Benn is saying that it is, but it might be tempting to read his post that way). Both entities and metrics are important and we need a layer that can link entities to each other and to relevant metrics in a way that affords accurate representations of hierarchies in business concepts.
We need to solve the problem of the relationships between metrics and entities, and entities and other entities in a way that preserves their centralized definitions and use. This is the hardest part.
If you imagine that the relationships between entities, other entities and metrics will be unique for each business, and that there will always be a subsection of metrics and entities that are unique to a business, then most of the work for a future data team will be defining those relationships and special entities in code. And most of the problems they will have, will be about either 1) the high incremental cost of defining and maintaining those special entities (relative to the rest of the system), or 2) maintaining data consistency across different relationships.
Sound familiar yet?
Abhi tripped this circuit in my brain with this tweet:
What we’re talking about here sure looks a lot like microservices, and all of the problems that come with this architectural paradigm. Without going too far down the rabbit hole of why microservices aren’t for everyone, let’s talk about some of the most applicable lessons.
Entity and/or metric data being out of sync. EL is for better or worse, still a batch process, and a linear (rather than asynchronous) one. Most EL jobs run in a matter of hours, but the more complex the number of inputs, the longer it takes to get to build a final representation of your metric or entity because you have to wait for those inputs — otherwise different properties of the metric or entity might be out of sync.
Now let’s imagine that we have Customer, User, Account and Project entities nicely defined with a handful of overlapping properties across two or more of these entities. Depending on your data sources, your Customer entity might be faster to model than your Account entity (even by a few minutes). Do you wait for every aspect of the joint lineage of all of your entities to be done before you “bless” a version of them for query consumption? Your insight latency is then as slow as your slowest ELT process. Or, does this architecture necessitate a really really fast data warehouse?
How do folks using microservice architectures in software engineering solve this problem, you might ask? There’s a lot of cool solutions, mainly in the streaming data space. However, in a software system, you’re aiming for eventual consistency rather than point in time consistency. But when you’re working with data to enable insights, point in time consistency is paramount. Do these solutions translate to the needs of business insight?How do you make modifying the entity or metrics layer simple? One of the biggest pitfalls of a microservices architecture is a lack of shared context across teams that maintain different business units — the architecture explicitly and intentionally doesn’t require it to function. If your Revenue Ops team is largely responsible for your Customer entity, but your Product Analytics team is largely responsible for your Accounts entity, how do you make sure both know enough about the other to avoid problems like inaccurate ARR when the Account to Customer relationship can vary from one-to-one to one-to-many?
This is less of a “lesson” and more of a question. If what we are talking about is similar to what is, fundamentally, microservices architecture, is this the data mesh? 😬

All of the above being said, problematizing a concept is the easy part (I’m a data professional, that’s kind of what we do). Building solutions to some of these problems is going to be the hard work. Maybe that’s why Benn called it the Trillion Dollar problem? 😉
And despite that, I don’t believe any of the above are problems that are unsolvable, and I’m excited about thinking more, together, about taking a crack at them.
What challenges do you see? How have you seen others solve some of these challenges? Reply to this email or to this post on substack, or hit me up on Twitter!
Elsewhere on the Internet…
Why it matters where you randomize users in an A/B test
by Adam Stone
If you’re thoughtleadership-ed out, like I am now, here’s a nice technical piece from Adam Stone to cleanse your palate. Adam writes very simply and coherently about a pretty brain busting topic, and I am here for it!
If you’ve ever run or plan to run A/B tests, you might have wondered if it’s worth the significant extra effort to randomize only some of the users exposed to your A/B test.
Adam has all the answers.

Don't make data scientists do scrum
by Sophia Yang
Scrum has been super popular for many years. I’m amazed by its success in marketing. It’s like the Kardashians of the software development management framework world.
If this quote doesn’t invite you to read Sophia’s piece, then perhaps this expertly chosen cat pic will:

In all seriousness, I appreciate that Sophia both problematizes an approach and offers up a take on how to do it better (unlike what I’m doing in this Roundup with the entity layer 😉).
Building an end-to-end open source modern data platform
by Mahdi Karabiben
So many pieces of the modern data stack have roots in open source, you might be wondering if it is possible to build an open source MDS platform end to end today. Mahdi says, yes, and their post comes complete with a GitHub repo demonstrating how to wire everything up 👏
by Alex K Gold
If you are considering people management, wondering how to get better at people management, or mentoring someone on how to get better at people management, you want to read Alex K Gold’s honest and vulnerable account of their first management experience.
A few things that resonated with me:
daily emotional reaching management had required of me
I like to joke with my team that a big part of my job is therapy, except it’s not really a joke. Managing humans, as Alex poignantly points out, very often involves flavors of therapy (human or organizational). Alex has some very good advice here, that I will second: before you become a people manager, spend some time in therapy yourself. Put your mask on, before helping others. ❤️
As I started, I really didn’t have a clear idea of what management was
This is true for so many humans, still. We are often promoting folks into management without solid support systems, training courses or ideas beyond personal experience of what management is or should be. This post helps a lot with expectation setting. I’m bookmarking this as required reading from now on.
But it turned out management didn’t work like that. It turned out management was a craft.And like any craft, some theory was helpful, but the hard part was putting that theory into practice.
Seat time is so important! Some lessons you still have to learn by doing them. Reminds me of this really great post from last year from Erika Pullum on Management seat time.
Shortly after this incident got resolved, I adopted the maxim always provide more context. I found that every minute I put into providing context around why something was happening was paid back in spades later on. My team was made up of really motivated, really smart people, so once they had the necessary context, it was easy for them to spot mistakes or find improvements that made sense.
I’ve never sat down to think about this, but this has always separated the better managers for me when I was an IC and something I try hard to do as a people manager today. Context is everything.
Central to my mental model of management is that it isn’t actually a role. Manager is a title applied to a constellation of roles that I found to be mostly distinct.
And multi-tasking between those roles is hard. If you like a day organized around one task, management rarely feels like that. But if you enjoy multi-tasking, you will find yourself making a ton of impact quickly. And you do this, through leverage:
Aside from the feel-goody-ness of management, I’ve found management most exciting as a form of leverage. I could only ever type so many lines of code in a day, fit so many models, deploy so many apps. Management was a way to scale myself.
Yes. Yes. Yes!
Read the rest. Trust me.
The New York Times Viz that divided Twitter
by Nicole Lillian Mark
And finally, the visual from New York Times of US case counts that broke data Twitter. Nicole Lillian Mark pulls together most of the greatest responses, reactions and even re-imaginations of the image, including this one:
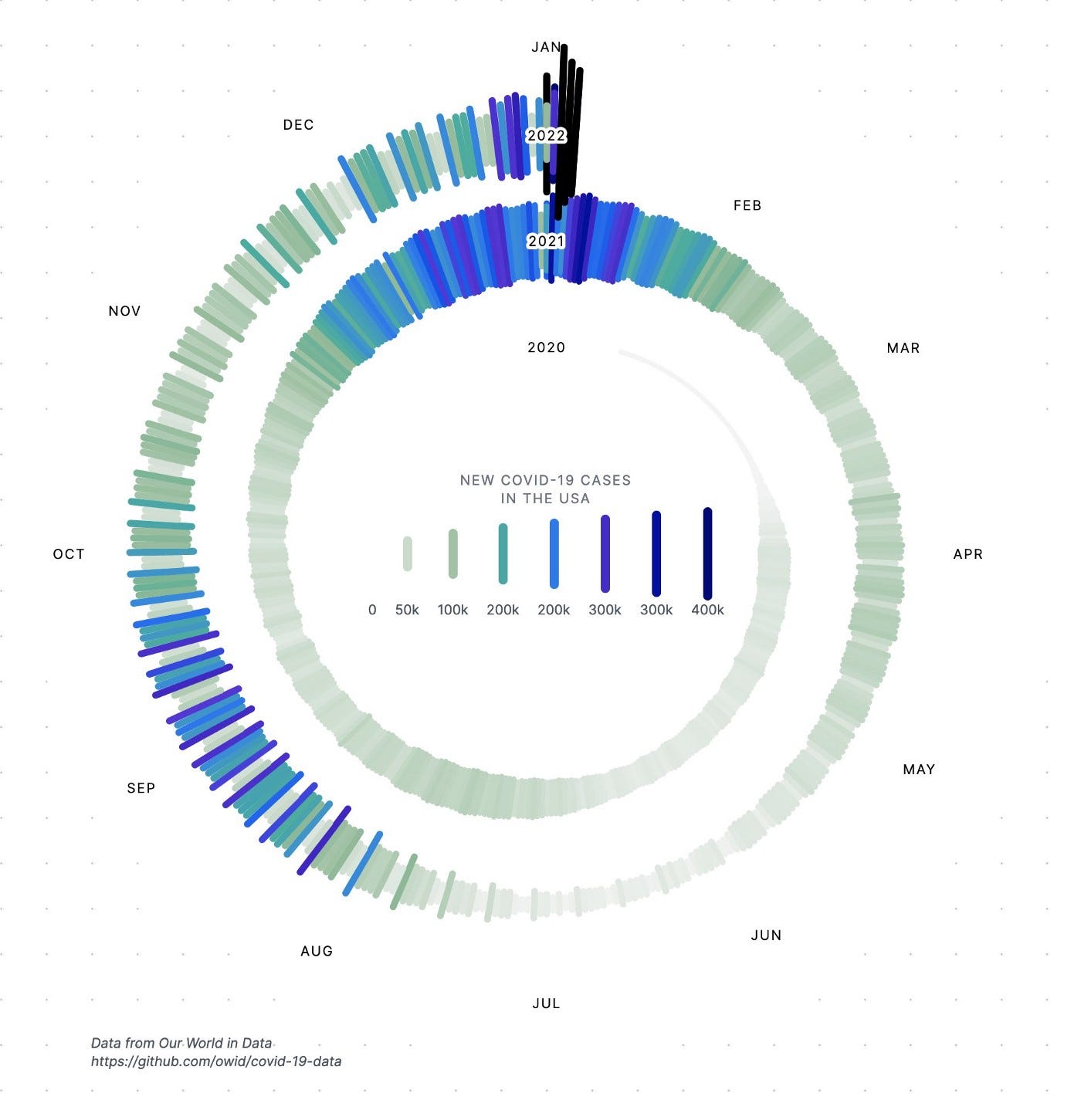
A great read if you wanted to catch up on what all the Twitter fuss was about.
That’s it for this week. Until next time! 👋
Thanks for sharing my post about the NYT graph!