
State of AI 2019. Parsing 25 TB in AWK & R(?!) Python @ Netflix. TPUs. [DSR #192]

❤️ Want to support this project? Forward this email to three friends!
🚀 Forwarded this from a friend? Sign up to the Data Science Roundup here.
This week's best data science articles
In this report, we set out to capture a snapshot of the exponential progress in AI with a focus on developments in the past 12 months. Consider this report as a compilation of the most interesting things we’ve seen that seeks to trigger an informed conversation about the state of AI and its implication for the future.
I linked to the 2018 version as well; this report continues to be excellent. There’s way more in there than I can add any value to in a short summary—if you want to catch up on a year’s worth of developments and trends, spend some time with these slides.
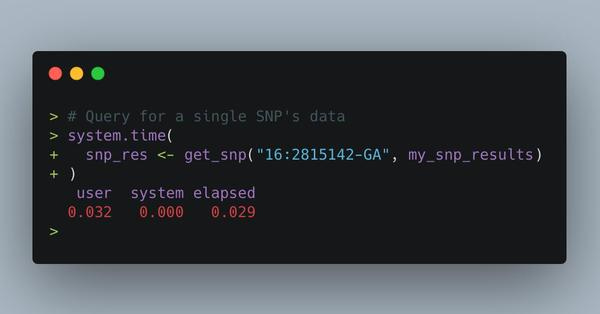
Recently I got put in change of wrangling 25+ TB of raw genotyping data for my lab. When I started, using spark took 8 min & cost $20 to query a SNP. After using AWK + #rstats to process, it now takes less than a 10th of a second and costs $0.00001. My personal #BigData win. https://t.co/ANOXVGrmkk
The post Nick references in the tweet above both describes an impressive project and is impressive in its own right. He uses a bunch of tools pipelined together to achieve that result, none of which would I ever think to recommend, but his final result was 🔥🔥🔥
His summary references the novelty of the pipeline he built, with all of the pros and cons that implies:
The final solution is bespoke and almost assuredly not the optimal one. For risk of sounding unbearably cheesy this was about the journey. I want others to realize that these solutions don’t pop fully formed into peoples head’s but they are a product of trial and error.
Nick indicated in a Twitter thread that AWS was a hard requirement, but were that not true I think BQ could have saved some hassle here. I find that this ability to select for the best tool across cloud providers is more often a pain point today than it was 2-4 years ago. Cloud tools have differentiated (Athena vs Bigquery is almost silly) while organizations have more cloud lock-in. Data engineers end up confined to a subset of tools and have to get creative.
livefreeordichotomize.com • Share
A list of data analysts, scientists, and engineers willing to offer guidance to aspiring and junior data professionals.
Wow. Phenomenal. I’m glad this exists.
Wowwww! Gitlab’s culture of defaulting to open creates such fantastic positive externalities. Here’s the recommended resources that all Gitlab data team members curate; these are really excellent lists, everything from Slack communities to newsletters to blogs (and more). Definitely scan through the lists and bookmark for when you’re looking for inspiration.
We wanted to share a sampling of how Python is used at Netflix. We use Python through the full content lifecycle, from deciding which content to fund all the way to operating the CDN that serves the final video to 148 million members.
Great overview of what Python is used for at Netflix. The short version: a lot. Lots of software engineers are still “meh” on broad usage of Python because “it’s slow”. While there is a certain context in which this is absolutely a true statement, Python in large-scale systems is often used as a wrapper on top of libraries written in other languages (e.g. numpy, pyspark). This dynamic is why Python is becoming so popular as the “wrapper of all things”. That said, it sounds like Netflix has invested in some high-performance applications written in pure Python:
Metaflow pushes the limits of Python: We leverage well parallelized and optimized Python code to fetch data at 10Gbps, handle hundreds of millions of data points in memory, and orchestrate computation over tens of thousands of CPU cores.
Fascinating overview of Python usage at a company that has made a massive investment in both internal applications as well as in the larger ecosystem.

Cloud TPU Pods break AI Training Records
Google Cloud sets three new records in the industry-standard ML benchmark contest, MLPerf, with each of the winning runs using less than two minutes of compute time.
Not entirely surprising that GPU/TPU workloads continue to become easier to orchestrate and faster in cloud environments, but worth tracking nonetheless. Building on-prem GPU hardware will go the same way that all other hardware has gone over the last decade or so.
What Separates Good from Great Data Scientists?
(…) training machine learning models is only a small part of what it takes to be successful in data science.
This is a common theme in this newsletter, and the author’s recommendations won’t be brand new to long-time readers, but the perspective is still one that most incoming practitioners have not yet absorbed. So important.
towardsdatascience.com • Share
Thanks to our sponsors!
Fishtown Analytics: Analytics Consulting for Startups
At Fishtown Analytics, we work with venture-funded startups to build analytics teams. Whether you’re looking to get analytics off the ground after your Series A or need support scaling, let’s chat.
www.fishtownanalytics.com • Share
Stitch: Simple, Powerful ETL Built for Developers
Developers shouldn’t have to write ETL scripts. Consolidate your data in minutes. No API maintenance, scripting, cron jobs, or JSON wrangling required.
The internet's most useful data science articles. Curated with ❤️ by Tristan Handy.
If you don't want these updates anymore, please unsubscribe here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue
915 Spring Garden St., Suite 500, Philadelphia, PA 19123