
What data agent benchmarks do and don't tell us
And more from AI Council

I spent the last week at AI Council (formerly Data Council).
Last year’s conference was for me, a very strange experience as it represented the seemingly irreconcilable grafting together of two very different types of systems - data infrastructure, where we painstakingly assemble workflows, best practices and highly specified technical specifications, with LLMs, AI and agents, a rapidly changing, highly uncertain and highly strange technology.
This year’s AI Council proved that the inherent tension isn’t going anywhere, but at the same time we’re starting to understand how we can, and can’t merge these two systems. Where they’re the same, where they’re different and where they rhyme.
Everyone is an AI Infra Company now
One of the most obvious takeaways is that just about every company at AI Council (very much including dbt Labs, represented by yours truly) sees themselves as an AI infrastructure company now. From the tiniest startups to the breakout stars to the established players, everyone is building toward becoming an infrastructure layer. This took a couple of different shapes, from context provider (we fetch / index / search over the data context that makes your agents more performant) to workflow orchestrator (we kick off / manage / schedule the agents that perform useful actions) to compute (we provide the inference for your agents or the data operations they perform) it’s pretty clear that there’s a set of emerging lanes here that are similar but different from the lanes in the CDW era and everyone is looking to see where they fit.
I spent an evening talking to a founder who is building a database for storing physical logs from robotics fleets. He walked me through ingestion rates, the cardinality of his query workload, the strangeness of dealing with timestamped sensor streams that arrive from a moving piece of hardware. At no point in the conversation did we need to figure out which side of the AI-versus-data line his company sat on. Nobody at the conference seemed to need that line.
The signal of the shift is everywhere if you look for it. There are now databases being designed for LLM-shaped workloads from scratch, rather than being retrofitted from older analytical stores. LanceDB is the example I keep coming back to when I describe this to people, an AI-native multimodal lakehouse with a fresh Series A in the bank and a storage format designed for blob reads and embeddings rather than columnar BI (listen to Tristan’s conversation with LanceDB CEO from last year here).
The data and analytics track, which a year ago was the part of the building that felt most stubbornly insulated from the AI noise, was this year the part where the shift had landed most fully.
How good are these things anyway?
A particular special interest of mine is benchmarking how good agents are at doing data work - both answering natural language questions on top of your data as well as building out your dbt projects and data pipelines.
Benn and I gave a talk on the state of benchmarking agents and also why current efforts at benchmarking (even ours) fall flat when compared to actual performance of your agents.
I started with a run through of significant moments in benchmarking from the last several years.
Juan Sequeda et al’s 2023 paper which showed that LLMs can answer questions on top of data and that ontologies outperform text-to-SQL
Our initial replication which showed that the dbt Semantic Layer increases reliability for LLM-generated queries
Our 2026 rerun that showed near perfect performance on the Semantic Layer and substantial improvement in text-to-SQL
Our release and writeup of ADE-bench which goes beyond the answering of data questions and for the first time benchmarks the ability for coding agents to actually build your data pipelines
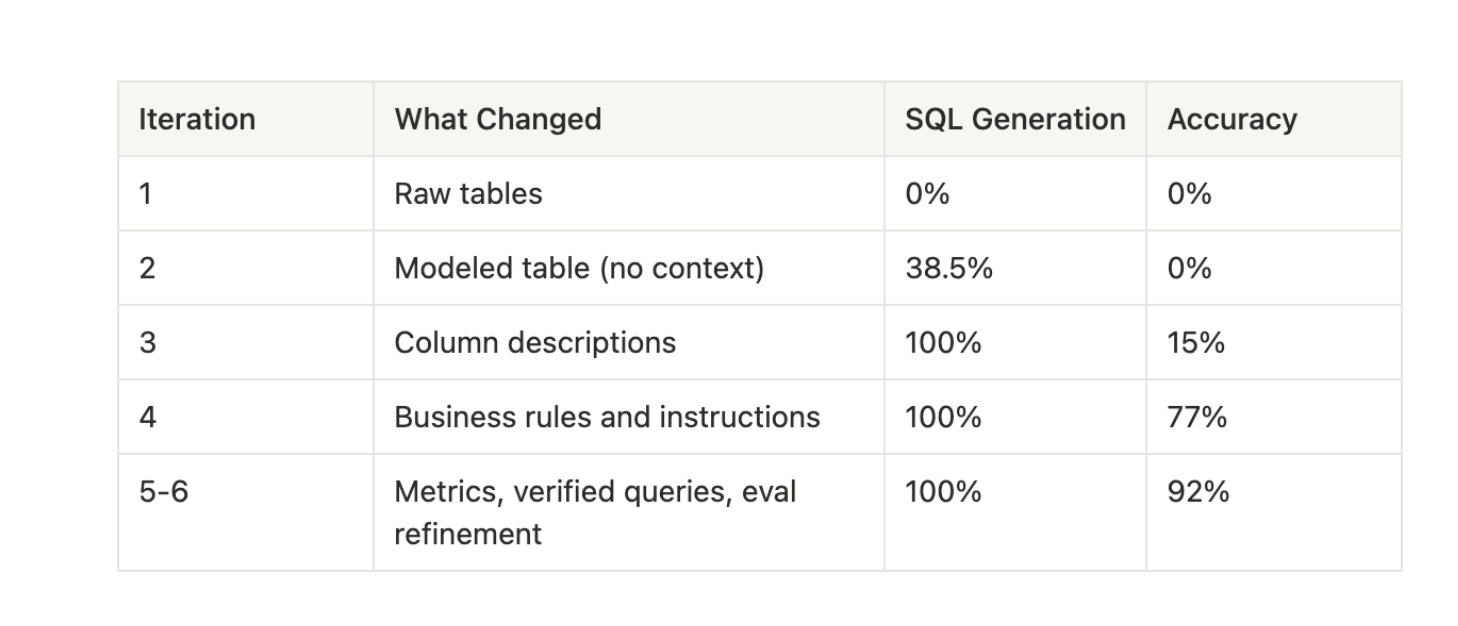
That brings us to today. What we know is that on well-specified tasks where the information to answer them is there, models are good and getting better. And thanks to Opeyemi Fabiyi’s excellent recent experiment we actually know what specific activities give the biggest uplift in how well agents can operate on top of your dbt project.
But if I’m being honest, it still feels like there’s more we don’t know than we do know about how good these systems are in practice today. There are important ways that we are both underestimating and overestimating their practical utility. And I’m going to get there - but I want to talk about the other analytical benchmarking talk from the conference because it also helps fill in an important piece of the puzzle.
Izzy Miller also built a benchmark and it’s brilliant (although not accessible to the public just yet). His thesis is that to actually measure how good agents are at doing analytical work, you can’t just ask them a question, you have to see how they perform in a real-life environment. Even ADE-bench, which measures messy real-life data problems, is not an iterated game - it’s a series of disconnected tasks. Izzy built something different - a full, 90-day simulation of a business complete with tasks that build off of each other.
This gets at one of the two most important ways real-life deployed agents operate differently than how we’re benchmarking them today - statefulness. In most benchmarks, learning from your mistakes, making a mental note and then solving the problem differently the next time is considered cheating. But in the real world, where we’re actually trying to solve real problems we call that … being good at your job. By having a benchmark that is a simulation that runs over time, you are able to see if an agent can learn from its mistakes, fix underlying issues and get better over time. This is much closer to how data agents are going to be operating in the real world.
There’s one more thing though that is challenging to benchmark for your data agents, and it gets back to everyone’s favorite word - context.
When I run a query in Cowork today, it has access to:
Everything that’s in my dbt project
GitHub
Slack
Notion
And more (task management like Jira, email, customer support tickets etc)
Remember - Tristan tells us that soon, agents are going to be consuming dramatically more data than humans. But they aren’t going to just be in isolated environments, they are going to do it connected to all of your other systems.
They’re going to check your dbt project, query your database, look at the commit history on GitHub, read the Slack thread where the last similar request happened.
My guess is we’re dramatically underestimating how good these systems can be by testing them in sandboxed environments, when in reality we’re getting much closer to building an integrated ecosystem in every organization. Obviously there are governance and security issues to figure out here, but the benefits of having OBPOC (one big pile of context) are too big to ignore.
Optimizing Agent Workflows
If last year’s conference was about the will-they/won’t-they of analytics and AI, this year’s is making it clear that the answer is a resounding yes. The agentic revolution is well underway and teams everywhere are racing to adopt these systems. They are going to keep getting better, the infrastructure, the harnesses and the models.
One of the big things I’m going to be watching over the remainder of the year is a shift towards token efficiency - the topic of a fantastic panel moderated by Bryan. For most organizations, we’re still distinctly in the experimentation phase of AI and I’m actually more positive on token leaderboards than most, in that winning the cultural shift towards actually using models for more things is one of the most important things you can do right now.
But these things have a physics and spend is already at atmospheric levels. Even if you don’t expect spend to go down (I don’t), in a world where we remain compute constrained for the next several years at least, there is going to be demand for more agentic work than can be done by the biggest, most expensive models. And that’s where optimization comes in.
This is a very common pattern in dbt - you start your project as views with your marts materialized as tables, and then shift towards incremental models to reduce the work your database is doing. Critically - you get the same data you would otherwise, but smart optimizations get you there much cheaper.
I expect this to start to become a major theme for data teams later this year - not just delivering high quality agents, but delivering them in a way that maximizes impact while minimizing data warehouse and token utilization.
So where are we now?
Data agents are good and getting better. We know that improvements like organizational context and memories improve their output, but we don’t have any great mechanisms for tracking them. And meanwhile, we’re building the systems that will create massive numbers of workflows at our business in the future and we should be thinking not just about building the best agents, but building them efficiently.