
Human interfaces
Why the way we design our organizations depends heavily on the limitations of our tools, and how human interfaces signal the shape of a missing technical solution.


The main piece in today’s Roundup is inspired by a conversation I had this week with Abhi Sivasailam.
👉 PLUG: Abhi has a podcast episode landing this week that goes into some of the ideas we discussed and that I’m riffing on below. You should absolutely watch out for the link on his Twitter feed.
Also, today Jason Ganz makes a special guest appearance as an author on this Roundup. Jason has put together some of his thoughts on a few of this week’s most impactful articles. I’m excited to include them with his permission below in Elsewhere on the internet…
Hope you enjoy the issue!
-Anna
Human interfaces
Today allow me to start at the end, with an assertion:
Most organizations compensate for gaps in technology with human interfaces. If you want to understand what is missing in data tooling today, you only need to look as far as how folks organize themselves within data organizations, how they collaborate with others across the business, and who those collaborators are.
It’s no accident that the current set of job titles in the data profession looks like this:

There are some really great insights and examples in this Twitter thread from folks riffing on the areas of overlap in job titles, so I highly recommend checking out the full conversation. But what I am personally most curious to hear about when we talk about how we use job titles is:
How is data used in your business today? (Is your company’s product powered by data? Is data used for internal insights? Both?)
What is the level of maturity of your core data model? (Do you have a set of gold standard tables available for use across the business yet? If yes, do you have testing and CI implemented to help you scale that?)
What are your constraints? (Are there existing organizational dynamics, bottlenecks or requirements that you need to plan around?)
Any advice we give on data organization design needs to be grounded first in this context because how we use job titles today in data really depends on what your answers are to these questions. This is why I have been so thoroughly enjoying David Jayatillake’s writing as he starts a new gig: the first few weeks in a new role in a new organization are when this context is most obvious to us. It’s a magical time before we settle into the status quo of “this is just how we do things here”, and I’ve been looking forward to gems like this one:
“One of the things I’ve found in data is that you’re very dependent on upstream frontend and backend engineering teams outputting data; if they don’t have the time or care to ensure it’s of high quality, complete, and documented then it’s impossible to ensure analytical use cases can be reliably served. I’ve proposed an initial data org that includes Data Engineering, Analytics Engineering and Analytics, heavily weighted towards Data Engineering at first.
As part of this Data Engineering team, I have proposed having iOS, Android, and Backend engineers. They would perform integration of data collection SDKs into app and backend platforms, building of CI/CD tests for data, review and adjustment of changes to app and backend that impacts data, and to eventually intake and deploy analytical and ML outputs into these platforms. This may not always be full-time work, which is why they would work in Data Engineering in a matrix way, allowing them to be involved with regular product-driven work too which will deliver further synergies and benefits.”
💥
I’m highlighting this section not only because this is something many a data leader has dreamt about being able to do to finally get their product instrumentation under control 😉. I’m also highlighting this because it tells me that despite many tooling solutions on the market today we’re still not solving some fundamental challenges and this is requiring us to use human interfaces instead.
The underlying challenge that David points to based on past experience is that of incentives — despite ease of use and the very best intentions, so long as telemetry is something that is an addon to the workflow of a product engineering team, it will remain difficult to ensure quality, consistency and completeness.
Today we attempt to solve this by bringing those teams closer together in our organizations. But what does a solution for this look like tomorrow?
Here is where my conversation with Abhi Sivasailam this week got really interesting. We started to imagine the specifics of a world Benn painted in broad brush strokes a few weeks ago: one in which a data OS was not just a shared primitive across only data workflows — but a fundamental component of how all applications will be built tomorrow. In other words, what if the entity layer wasn’t just something you defined on your own for your business. What if this was a standardized, shared set of objects that production applications could pass information to and data applications could build on top of?
Let’s get more specific with some examples.
What if Salesforce, Zendesk, your billing system (e.g. Zuora or Braintree) and your data visualization layer of choice all referenced and interacted with the same “Customer” object? What if it didn’t matter if your customer was paying you via a self-serve payment system monthly and then moved to annual invoicing and to being managed by a sales representative? What if your data tooling knew that this was the same customer? That would easily remove 80% of the painful integration work that is currently required from data ops folks to enable a working understanding of a business’ customer base today.
Another example more relevant to the problem David is describing above: what if your product logging system had the same concept of a “User” as your actual product? What if the event logs that were used to construct an understanding of a User journey through a product in your analytics were the very same data your production application read from to display information to your users?
I’m not talking about production table snapshots. I’m talking about event based data that is a first class citizen in a production application environment — the data your user sees in their application interface is then exactly the same as the data your analyst uses in their understanding of the business. If data used in your analytics is wrong — it’s then also wrong for your users. It then gets corrected as part of regular software maintenance, rather than a separate set of bug fixes tacked on to a sprint cycle of a team already overloaded with other issues.
The best part about the dreaming that Abhi and I have been doing here is that it doesn’t require magic, or a set of completely new things that we need to invent and then convince our friends in Software Engineering to adopt. We have the building blocks to do a lot of this today, and those same friends in Software Engineering have been talking about this idea for almost a decade already: it’s called log based architecture.
For everything you ever needed to know on the concept, I highly recommend starting with this classic piece from Jay Kreps that was later expanded into an O’Reilly book. I’ll give you the cliff notes here instead:
Log based architecture involves materialized event data by default. Instead of kafka queues that emit ephemeral events (i.e. you snooze, you lose your data), application data is first written to the log, the application then consumes it, and is able to do so at any point in its history:
“… a log decouples publishing from consuming in a way that a queue cannot. We are free from temporal constraints. No longer are consumers constrained to consume messages once, from around the same time the publisher sent the messages out. Consumers can go back in time and consume events from the past. New consumers can come online and read messages from back before the application was even developed! This is a massive improvement over queues.”
Next we need standardized serialization to be able to use this across different applications and contexts. This is already available via things like Google’s Protocol Buffers. Imagine using something like this to define your “User” or “Customer” objects and their relationships to one another:
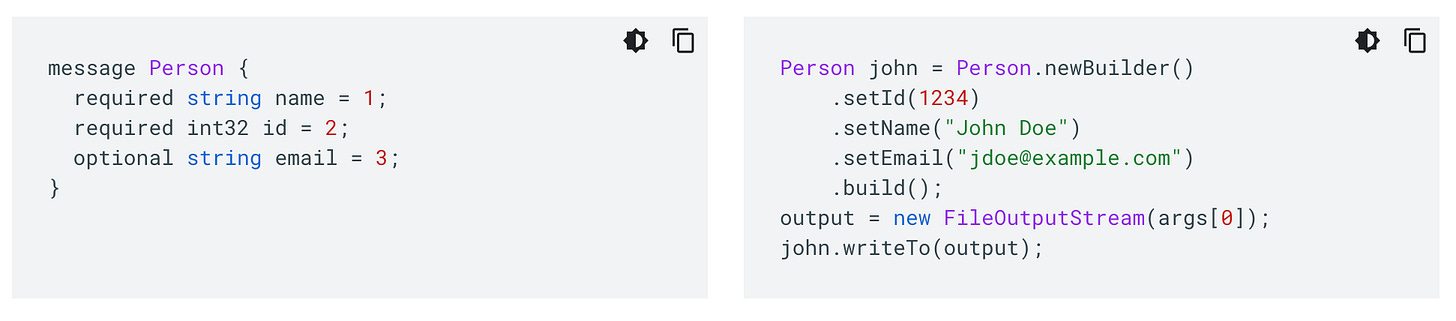
via: https://developers.google.com/protocol-buffers It then becomes relatively easy to turn this into structured data that can be consumed in an analytical context as well — your data model is already defined for you! No more Extract and Load? Yes please!
The third, and as yet missing step, is a framework for expressing these foundational data objects in standardized and predictable ways. What we need here is something like Ruby on Rails’ conventions over configuration and an actual framework for parsing the structured data (e.g. ActiveRecord but for a log based architecture). THIS is (or should be!) the entity layer. Abhi and I have both seen enough homogeneity across businesses to make these kinds of conventions and standards a distinct possibility, so I am optimistic that we can get here.

What is most appealing to me about these building blocks is that they are language agnostic — you could write Java, Python, Rust, TypeScript, you name it to both produce and consume the log based data. This is what enables us to start building all kinds of complex data applications on top of a data OS 💥
I’m curious if this resonates for you! What human interfaces do you find yourself leaning on when you design your data organizations? What gaps do they point to in your own systems, tooling or processes?
Elsewhere on the internet…
👋 O hi! Wad dis? New face!
This section comes to you today via the always thoughtful dungeon master Jason Ganz, who was gracious enough to share some of his ideas with me this week. I’m sharing them below unedited with his permission :)
By Ashley Sherwood
Oh gosh this is just one of the most moving and important articles I’ve read in a long time. Ashley Sherwood’s newsletters has quickly become a favorite at the Roundup with her huge amount of business savvy, even huger amount of compassion and the fact that she is just a tremendously talented writer. She also manages to deploy metaphors in such a powerful way. Her last post beautifully riffed on organizational growth and biology and her most recent teaches us about being human by teaching us about chemistry.
“When I worked as a chemist, I used balances (aka scales) that were so sensitive that they could detect the force of air currents, vibrations from footsteps, static electricity on the plastic measuring tray, and more.
To ensure that I was measuring the mass of the reagent and not other random forces in the room, I followed a specific procedure to discharge static electricity, tare the balance, close its protective shield, and wait for the reading to stabilize.
Once accommodated and insulated from outside turbulence, the balance could deliver the incredibly sensitive reading that I needed.
Likewise, sensitive humans work best when insulated from irrelevant outside turbulence.
This is not a weakness—it’s simply the other side of the coin. Accommodation is essential to reaping the unique benefits of sensitivity.”
Ashley goes on to show in great detail how sensitive people can provide unique value to an organization - if the organization cares enough to accommodate them.
“Consider this: Finance and Sales both pitch an idea for measuring sales volume for the month, and both groups think they’re on the same page. The more sensitive you are, the sooner you’ll detect the tiny differences between what Finance and Sales are actually saying.
Those tiny differences compound over time. If not detected early, they lead to wasted effort, disappointment, frustration.
Sensitive people have an uncanny knack for nipping misalignments in the bud.”
This piece should be required reading not just for managers, but for everyone who cares about treating all of the humans around them well. I want to quote just about the entire piece, sharing a few of the many highlights below.
“In the right place at a right time, a sensitive person can spend five minutes to avert a crisis that (theoretically) would take five months to untangle. But since it’s impossible to quantify what didn’t happen, sensitive people (and their managers) may under-value their impact.”
“There are three key strategies to reducing the negative effects of turbulence, in order of least to most drastic:
Insulate/buffer - noise-canceling headphones, mute notifications, route interrupts through a manager, trusted coworker curates information, etc
Reduce exposure - only receive interruptions at certain times, take more breaks, partial work-from-home, etc
Removal - reassign a problem client, employee changes role/team/company, etc”
“Sensitive people are deep processors and experience the stresses, trials, triumphs, and successes of their work and life in high fidelity. They tend to be excellent creative problem solvers, likely to come up with solutions that others wouldn’t have thought of.”
Introducing: Knowledge Library
By Barry McCardel
The folks at Hex have an interesting new release with the Knowledge Library - a new set of features aimed at providing context (dare I say metadata) around the analyses and data products created within Hex. This aims to get at one of the core projects of any data team - going from facts to knowledge. As Barry puts it in his feature release post:
“Knowledge is the sum of facts, accumulated through inquiry and experience. It’s the forest for the trees. The bigger picture. The whole dataset.
Creating this kind of shared understanding is the real mission of a data team, or anyone doing analytical work at all. You may set out to answer a specific question, but what you really want to do is contribute to an organization’s knowledge: the set of things known to be true about the world.”
Using this new feature, apps in Hex can be given tags to let users know what the status of an app is and how it can be configured. Tagging, by itself is helpful but not exactly a revolutionary breakthrough. Where it starts to get really interesting is when you can configure the user experience for the rest of the organization via the labels you’ve selected.
“Now the main attraction: the Library View. Here, users only see published apps with a Library Status like “Approved” or “Production”. This is now the default view for View-only users, who are less likely to care about (or shouldn’t see at all) projects that are in the draft or archive phase.”
One of the great things about this release is that it is able to provide a huge amount of flexibility and power to data teams without a tremendous shift in the technology that is already there and working in the product. This is something we talk about a lot internally - how can we build just enough flexibility and configuration via things like the meta tag to allow for tremendous amounts of new and interesting use cases while not losing sight of the core of what the product does.
Barry also released a great post on his philosophy behind building a product - Commitment Engineering. The idea is basically to create tight feedback loops and consistent give and take with early users, something which Hex has been consistently quite good at, although in this case it seems like the call may have been coming from inside the house.
{kind=link}
Good Data Citizenship Doesn’t Work
By Benn Stancil and Mark Grover
And lastly, lest you thing Benn was taking a week off data thought leadership - he and Mark outline some of the drawbacks from our current conceptions of “data democratization” and some ways we can make it more doable in the long run.
 | A guest post by
|