
Moving Up the Stack: Analytics Engineering in the Age of Agents
The time dbt automated my job away

How would you feel if you were looking at the website of a potential new employer and you read this?
“We believe that all team members should seek to replace themselves on an ongoing basis by building processes, technology, and documentation that obviate their existing work. We have an abundance mindset: there is always more, and more valuable, work to do. Moving up the stack presents growth opportunities for both the individual and the team.”
In today’s climate, defined by AI anxiety, it strikes a very specific chord. Maybe even ominous.
And you might be surprised to hear that has been one of the core values of dbt since 2016. We call it “moving up the stack”. I think it’s really easy to read the first half of the value, about attempting to obviate your existing work and miss that the second half is just as important - that doing so creates growth opportunities for the individual and the team.
The goal of moving up the stack is not ominous, it’s not to make humans irrelevant. It’s to empower them, to allow them to solve creative problems in new ways. It’s based on a fundamental belief that people are smart, the world is complicated and we all have so much more good work we could be doing, given the right support.
Moving up the stack is most relevant when a role is hitting a phase change, a threshold point during which the new version of the role is fundamentally different from before, usually precipitated by a new technology. We’re at such a point right now. But before we talk about that, I want to tell the story of the last time we moved up the stack as a profession.
Analytics Engineering Everywhere
Almost exactly five years ago, I wrote a blog called Analytics Engineering Everywhere. It was a post about how I was pretty confident that within 5 years, the principles behind dbt would be the worldwide standard for how data work is done. I’m generally nervous about making big sweeping predictions but:
I was very confident that this was correct
Five years felt impossibly far away, so if anything went wrong it would be future Jason’s problem to deal with
But mostly it was that I believed in dbt
I had such strong conviction because I’d seen firsthand the way that analytics engineering entirely reshaped my job and it was just obvious that this was a better way to do things.
And now five years later, I’d say that most of the article held up pretty darn well. The massive transition in data work that the early analytics engineers were seeing, pretty much happened. You can see it in the adoption numbers: dbt now has over three million daily downloads and will have been downloaded for the billionth time at some point this month.
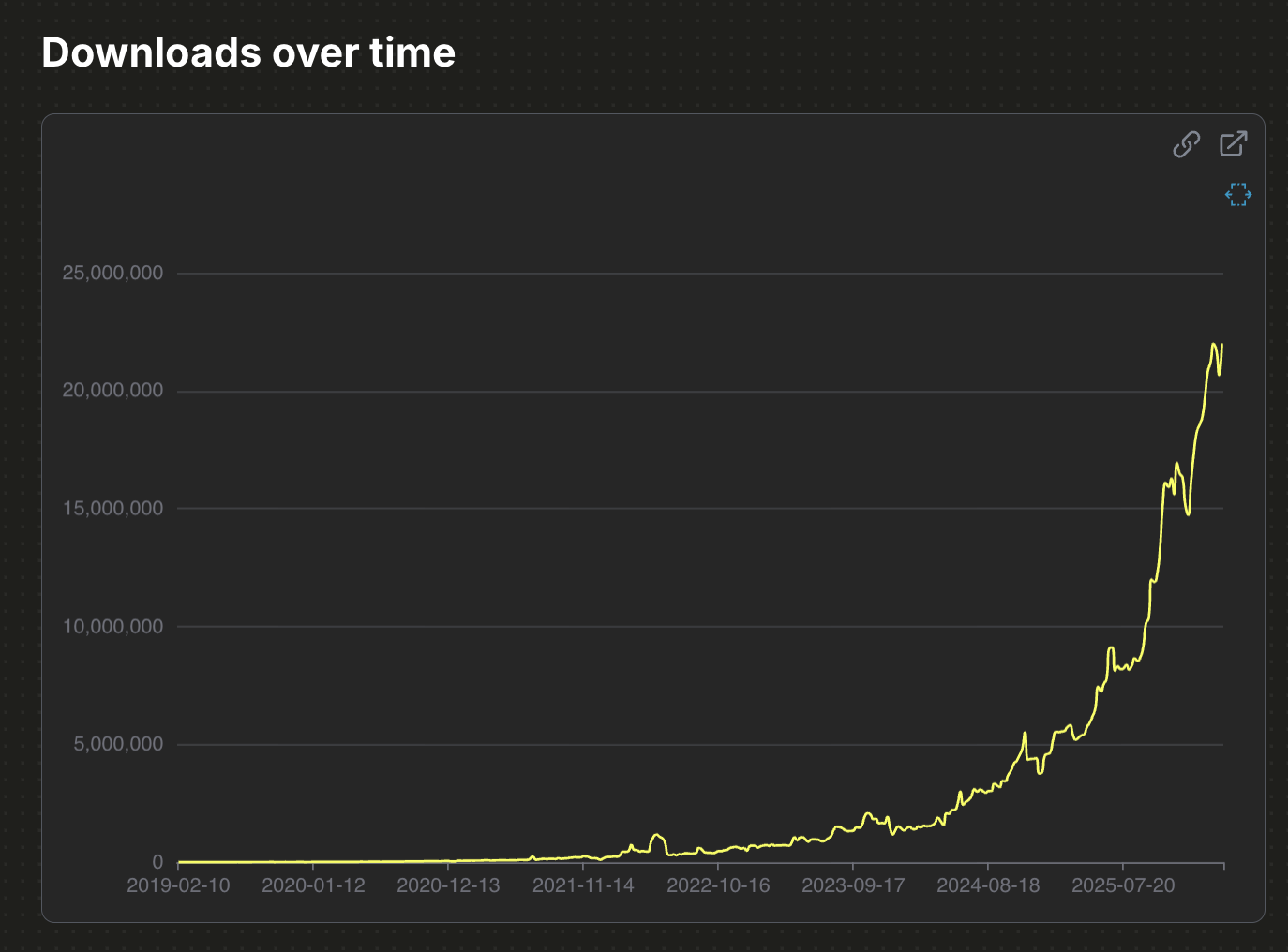
And you can see it in the community. Literally millions of humans have improved their impact, increased their salary and helped the world get better at using data.
So in one sense, I feel pretty good about my prediction for five years out. But—and this is a big but!—I missed an even more important point.
It turned out that there was an even bigger wave following directly behind as LLMs emerged to totally reframe how every knowledge worker is thinking about the future of their work.
Now is the time to make sure that data practitioners are best positioned to ride this wave and be set up for success in the agentic era, even as the tasks, skills and value drivers in data work fundamentally will change in the near future.
It’s time to move up the stack again.
Data work has already changed unrecognizably in the past decade
I know because I lived it once.
Pre-dbt, I was working at a tech startup as a data analyst. My job, more or less, was to handwrite a whole lot of SQL queries. We had a set number of weekly and monthly reports, and we mostly did those, with some occasional larger investigative or experimental projects. Just a few years out of school, it was a great way to get a deep, hands on understanding of how a business operates and how all the pieces fit together. It was nice, if a bit comfortable.
Until one day - it got very uncomfortable. Our CEO asked me to pull metrics for a board meeting. Not the usual handful of charts. Way, way more than we’d ever had to pull before - essentially every data point you could imagine. Our system simply wasn’t set up to operate at that scale. So I went home and spent two weeks writing SQL queries fourteen hours a day. Hundreds of queries, each one meticulously hand-built, each one requiring me to hold an enormous amount of context in my head simultaneously. It was the most intense, highest-drudgery period of my professional life. Honestly it was kind of fun in a masochistic way. And when it was over, I came back and said one thing: we can never, ever do that again by hand.
That search for a better way led us to dbt. I read the viewpoint and I was hooked. Within a couple months of adopting dbt, I had more or less automated my entire job up to that point.
Years of accumulated skills (knowing our databases inside out, knowing how to pull every report, knowing the quirks and workarounds) all of it, automated. That intense flurry of work for the board meeting turned out to be the last time in my career I would ever use that particular skillset.
But here’s the thing: I hadn’t become useless. I had become more valuable. I had moved up the stack. Because now instead of spending my days crafting artisanal SQL scripts, I was building and maintaining our dbt project. I was able to spend my time working on data driven experiments and process changes to improve the business, because I wasn’t spending all day writing queries.
And with the rise of agents, we’re once again being asked to move up the stack. I’m not claiming this is a perfect or even neat parallel; I, like many of us, have real fears about the labor market and indeed the basic social contract as we’ve known it so far continuing to hold under such dramatically changing winds. But the thing that I am very confident in is that the best way to navigate this, for individuals, and for our industry, is to focus on moving up the stack. Automating what we do now and finding bigger, bolder things to take on.
This is the right thing to do in that it’ll make us more effective in our roles, but I also believe that the best thing each of us can do to help smooth this transition is to determine how to effectively navigate the new technological landscape we find ourselves living in. Who knows, it might even be fun.
The new world is already here
This is not about some distant future state. AI usage is exploding. From time to time I pull this graph up and just stare at it. This is, to put it lightly, not a normal growth trajectory.
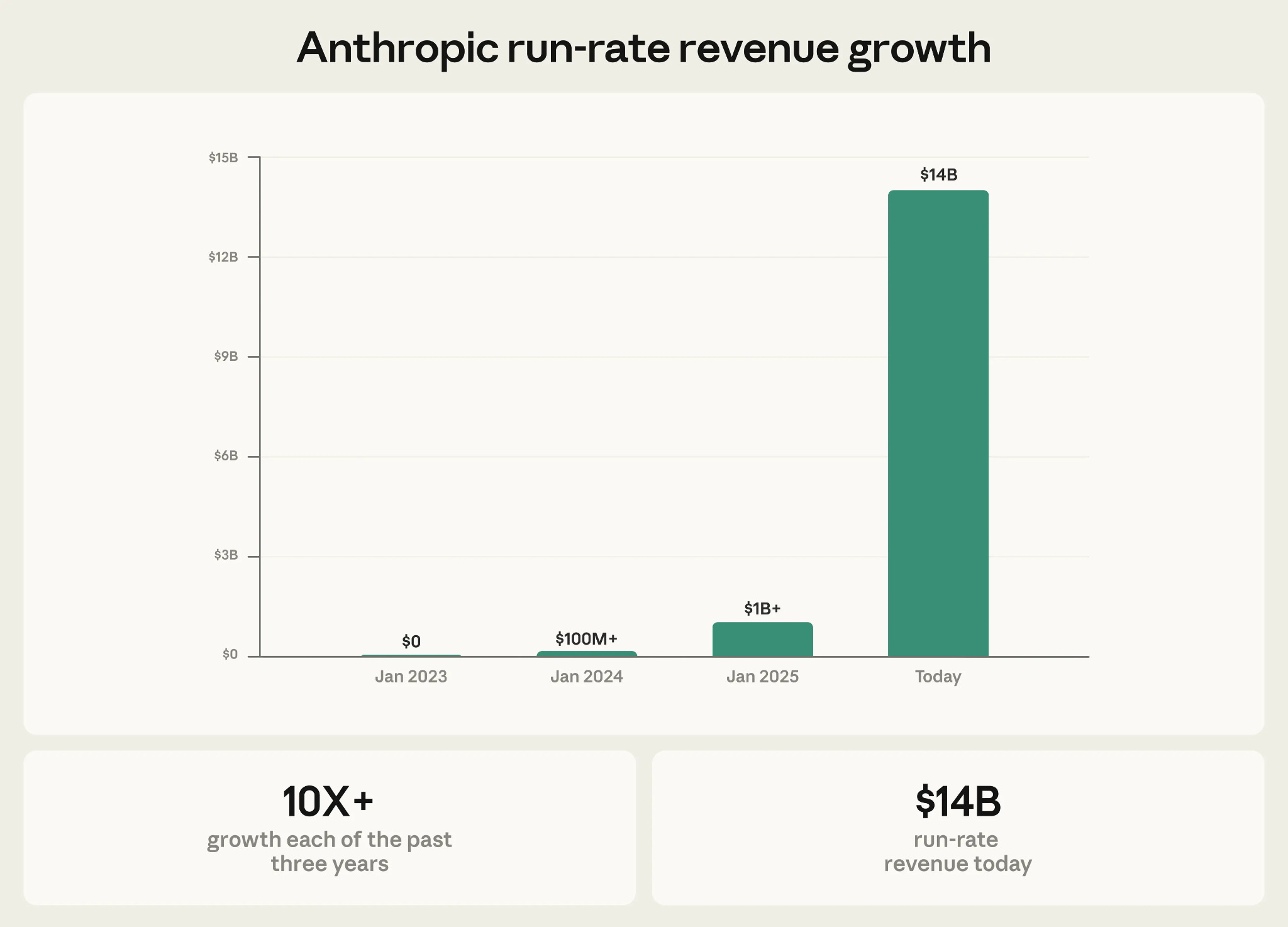
This is from February. It’s now much higher
A big part of the reason for Anthropic’s explosion in growth has been the meteoric rise of Claude Code for software engineering. Regular readers of this newsletter will recognize the ongoing theme here - tooling and best practices come first to software engineering and then to data.
To get this working for data requires the ability to interact with data systems at scale, which requires an additional layer of capabilities and tooling.
That being said, there’s already strong movement on agent adoption in the data world.
Hex has stated that more than 50% of their new cells are created by agents. Think about that for a second. The tool that analysts live in, the environment where the actual analytical work happens, is already half agent-driven. The dbt MCP server has been growing usage by 40% month-over-month and is starting to become a central piece of data infrastructure, with agents consuming dbt projects as context across a remarkable range of use cases. dbt Agent skills let you package up expertise. Forward looking companies like Ramp are deploying agentic analysts to exponentially increase the value of their data.
These systems work. They work well today and they’re getting better fast. There are real questions left to answer (does anyone have opinions about the role of a Semantic Layer in all of this?) but fundamentally you need to do a lot of mental gymnastics to not believe that these systems are going to fundamentally reshape data work.
Five years ago, it was obvious it was a matter of time until everyone was using dbt. Today, it’s obvious that it’s a matter of time until everyone has agents at the heart of their data work. But unlike last time, this transition will not take 5 years.
The question then - if we’re moving up the stack, what are we moving to?
But that’s not actually one question. It’s about 100. Questions like:
Why does knowledge even need curation in a world of agents?
What does an analytics engineer actually do in a world where AI writes SQL?
How do we maintain institutional knowledge about our data models if AI is generating them?
There’s a lot to say about each of these, as well as a lot to build. Now is the time to start deeply thinking about the future of data work and to start building the systems, processes and teams that can support it. I’ve talked to many of you already doing it and it’s incredible to see the things that this Community is building.
Check back soon for more dispatches from myself, Tristan and others as we chart the brave new world together.
Yes. Really interesting times. Based on recent claude code leak, it looks like AEs role will become more AI agents systems focused. Both development and maintenance.
Interesting read! If you were a passionate analytics engineer before the existence of coding agents with the boring work included, the future should be just as exciting. At least, I feel that way. But this time, the transition has one difference in my opinion, which I think makes it harder: it requires a mindset change across the entire company, not just the data team.
When dbt came along, you could largely adapt your own workspace in isolation, and the external environment in the company did not need to move with you to a large extent. Moving up the stack with agents is different. If the goal is to democratize data across the organization, make everyone a data person, and free the analytics engineer for high value work, then the whole company has to rethink how it operates internally. For example, a business update shared by the head of marketing in an all hands, previously held in an analyst's head, now needs to be captured in a format an agent can consume. This organizational knowledge management problem is everyone's job in the company. Similarly, it will not be enough to deploy a data agent to Slack, but make sure that every stakeholder has a base understanding of how to ask a question to the agent. These problems are not actually related to any context engineering problems that we have mostly been talking about in the data community.
So change management will be the biggest barrier to capturing the value of the agenric era for data, and a visionary data team will not move an organization alone. And this stays true until we have zero employee companies, which I hope is still a while away.. :)