
New Podcast! Why Frameworks Matter. Firebolt's Fundraise. Metrics @ Pinterest. [#255]

If you’re in the US, happy holiday weekend! I hope you’re getting a chance to decompress. Over the past week I’ve had the opportunity to take the first vacation with extended family that I’ve had in two years. Spending time outside and with loved ones is so important for me, and I’m excited to return to work on Tuesday refreshed and grounded in purpose and humanity.
Before diving in, a quick update that I’m excited to share: the Analytics Engineering Roundup now has a companion podcast! Titled, unsurprisingly, the Analytics Engineering Podcast. We’ll be publishing episodes every other week and generally will feature one of the authors of the posts from this newsletter to go deeper into their area of expertise.
The podcast is co-hosted by myself and Julia Schottenstein and the first episode is available here or on your podcatcher of choice. In it, we interview Robert Chang of Airbnb Minerva fame—we go deep on metrics stores and how Minerva is used at Airbnb.
My one ask of you is simple: shoot me feedback!! I really believe that a podcast needs to exist in this space, and I think that building one off of the Analytics Engineering Roundup could really work. But I am not a professional podcaster (nor is Julia)! We did hire a professional podcast producer, but Jeff doesn’t actually do the interviews 😀 It’s still up to us to guide a useful & insightful conversation, which (as it turns out) is a real skill.
So it’s your feedback over a large number of episodes that will end up crafting the show into whatever it will become. I was a pretty shitty newsletter author for the first ~50-100 issues and it just took a bunch of reps to get good. So thanks in advance for your support and patience with us :)
Can’t wait to find out what my voice sounds like in 2x speed!! 😬😅
- Tristan
Of the Community, By the Community, For the Community
If you’re in the analytics engineering world, it’s likely that this came across your desk already, but if not—my company, dbt Labs (just renamed from Fishtown Analytics), just raised $150m Series C. There’s lots to say about this, but I want to focus in on a particular angle here.
You can talk about dbt in a lot of ways…as a devops tool, as a competitor to legacy ETL tooling, etc. My favorite way to think about dbt is as a compiler for a new domain-specific programming language, dbt-SQL. We think about building new product functionality as implementing language features, and we care deeply about things that compilers would normally care about (i.e. parse time per resource).
When you build a new programming language, it’s hard to get people to start using it. Building an application in a given programming language is a massive dependency—you have to make a bet that this language has enough momentum behind it to enable you to hire engineers, get support from a community, and not have to fix every bug yourself. But once folks start building in a given language, things can snowball quickly. Typescript is a good example of this: it was first launched in 2012 and has since become the eighth most popular programming language in the world.
This is why I love this post so much. Lightdash, which I covered a few issues ago and is building a Looker competitor on top of dbt, wrote a whole post on why they made this choice. From the post:
By plugging into [the dbt] standard, Lightdash enables people to use their existing familiar tools and invest in the future. And if you throw Lightdash away, you are still left with an industry-standard set of data transformations.
Lightdash is explicitly making a bet on the strength and longevity of the dbt community. I expect to see more of this in the coming months and years as the snowball continues to gather speed. The neat thing about that is that, with a standard emerging in data transformation, we all get to move up the stack and think about the next set of problems! And there are plenty…
What I've learned about data recently
Gosh this post makes me so happy to read. I have, from the very early days, thought of dbt as “the Rails of data engineering.” I’ve never done a great job of explaining this intuition but this author nailed it:
Learning 3: there are frameworks now
For the first 10 years of messing with data, my "data pipeline" code was always a roll-your-own deal. Data would be accumulating in logs somewhere, it might be in CSV format, or Apache log format, or maybe newline-delimited JSON. It might be one file per day, or per hour, or per minute. The files might be any kind of size from a few megabytes to thousands of gigs. I would write some code in whatever language happened to be lying around to parse and extract this, maybe get some cron jobs going, load it into a database that was lying around handy, maybe slap some graphs on top. It worked! But it was its own special snowflake, and it seldom scaled.
We had the same problem in web development -- you could build a website an infinite number of ways, and that was the problem, because no two people would pick the same way, so they'd fight about it, or misunderstand how it worked, and everyone was constantly rewriting from scratch because they couldn't figure out the last thing.
This changed -- at least for me -- around 2006, when I heard about Ruby on Rails. Ruby is not my favorite language, but Rails was a revolution. Rails provided an opinion about the Right Way To Do It. It wasn't necessarily always really the best way to do it, but the surprising lesson of Rails is everybody doing it the same way is, in aggregate, more valuable than everybody trying to pick the very best way.
The revolution Rails and the blizzard of frameworks that followed it enacted was that you could hire somebody into your company who already knew how your website worked. That was a gigantic breakthrough! Instead of spending half your time fighting bugs in your architecture, the framework maintainers mostly took care of the architecture and you could fight bugs in your business logic instead. The result was a massive reduction in work for any individual developer and a huge acceleration in the pace of web development as a whole.
Rails was invented in 2004, but as I mentioned I came across it in 2006 and felt somewhat like I was late to the party. There was a Right Way To Do It now, and I'd spent 2 years doing it the "wrong" way! Damn! Better catch up! I never actually ended up building a site in Rails (I simply did not enjoy Ruby), but I picked up copycat frameworks in other languages and was off to the races.
Coming across the two frameworks for data engineering in 2020, Airflow and dbt, felt very much like finding Rails in 2006, except I'm even later to the party. Airflow and dbt were both first released in 2016.
Standards matter!!
Overcoming Rapid Growth Challenges for Datasets in Snowflake
(…) rapidly growing datasets are an issue almost every data team will eventually encounter (…)
💯 could not be more true. If you aren’t there yet, the answer is not whether, it is when this will resonate with you. The post introduces a simple framework to deal with high warehouse costs:
Can this ETL be decommissioned?
Can we break dependencies in the directed acyclic graph (DAG)?
Can this ETL be done incrementally?
Can we reduce the number of columns?
Can we stop data spillage by splitting queries into a smaller dataset?
Can we implement clustering?
Can we utilize Snowflake functions?
Read on for more detail on how each of these areas can be helpful and how to implement it.
Firebolt Ignites Growth with a $127M Series B Funding Round
The news is the headline—Firebolt, the new entrant into the cloud data warehouse game, is hot right now. They’ve made some very big hires and are starting to roll out their product to early customers. I’m excited to get my hands on it (hopefully soon). Here are a couple of selected quotes:
Over the past six months, Firebolt has doubled its employee headcount to 100 with plans to double again over the next 12 months.
Firebolt’s technology introduces a two order-of-magnitude leap in performance and hardware efficiency.
There’s a lot more in the post—worthwhile read to keep up on this fast-moving space.
Trusting Metrics at Pinterest
Another “how we do metrics” post from a data forward company. Airbnb’s writing on Minerva has certainly been more detailed to-date, but I found this section to be worthwhile:
To make sure that a metric is accurate, we’ve created a “certification” process.
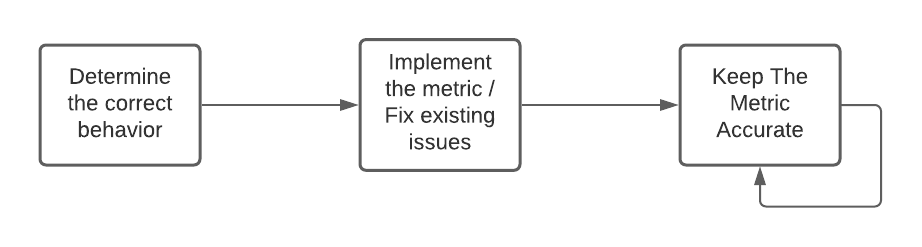
The interesting thing here, IMO, is step 3! Most cost of any software system is in production. Here’s the writeup on “keep the metric accurate”:
if you want the metric to continue to be accurate, you need to do a bit more. The UI tests and data checkers made in the last step are run recurrently to prove the metric is accurate. This means that failures in the UI tests can’t be released, and data checkers will lead to investigations. It’s key to keep in mind that uncovering why a metric moved in production is much more difficult and potentially costly than catching it before release.
Lastly, on a recurring basis (quarterly or annually, depending on the metric), we do health checks on the metric.
I particularly love the “health check” ritual! Very cool.
Roadmap: Data Infrastructure
Bessemer, one of the world’s top VCs, recently on record outlining their thesis in the data space. If you’re already living in this world their conclusions likely won’t be a big surprise to you, but it’s an excellent report on the state of the market and absolutely consumable by less-technical folks with whom you might want to share. Here’s my favorite bit:

The “Rise of FAANG Companies” section feels dead-on to me. It’s really in that era that I feel like the industry as a whole started getting a roadmap on what it looks like to do data really well at all levels, and (love them or hate them) this shift has been meaningfully driven by big tech. This is why I cover practices at these companies so much.