
Table change history + incremental models = ❤️. Working fast AND working right.
Plus: how to choose a product analytics tool, writing a dbt Macro 101, what's missing in data CI/CD and how to design your own warehouse security framework.

👋 O hai! Can you believe it’s already October? 🎃 That means, it’s less than three more weeks to Coalesce! 💜
I’ll be seeing you in NoLa, where we’re hosting a community Hackathon. If you’ve always wanted to write more macros, packages, contribute to core or documentation — come join us Monday! I’m excited to see you there!
Now, my last roundup was a little heavy on the original content, so this weekend I want to balance that but putting the most interest writing in the Community front and center instead :)
In this issue:
Write a custom dbt Macro, by Madison Mae
Choosing a Product Analytics Tool, by Sarah Krasnik
Lessons Learned when scaling dbt models quickly, by Wei Jian
Using BigQuery change data capture with dbt incremental models, by Jay Lewis
Building a centralized data warehouse security framework, pt 1, by MuleSoft’s Data Engineering team
Enjoy the issue!
-Anna
Write a custom dbt Macro
by Madison Mae
Explaining complex concepts very simply is probably the hardest part of technical writing. This is one of the reasons I enjoy Madison Mae’s blog so much lately — its especially great at breaking concepts down into their fundaments. This week’s edition: dbt Macros.
dbt Macros can be pretty intimidating because they are expressed in Jinja, and can feel like a big jump from SQL. When do you simply use Jinja and when do you turn that into a Macro? Madison Mae has you covered:
Don’t know whether you should write a macro or not for your use case? You want your macros to apply to multiple places within your dbt project. If it can’t be reused, it’s probably not necessary. dbt code is meant to be modular.
If it can’t be reused, it’s probably not necessary.
The only thing I have left to add to this post is that there’s plenty of macros out there that can be reused via the dbt Package Hub.
🏆 10/10 recommend this post for any of your new analytics engineer onboarding materials.
Choosing a Product Analytics Tool
by Sarah Krasnik
I was just chatting with someone this week about how to get setup with a modern data stack when you have a 1) lean data team and 2) lots of existing product telemetry sitting around, and found myself reaching for a comparison because it’s not a use-case I’ve personally implemented before.
It’s like Sarah read my mind :) What I most loved about this article is how it gives you a quick rundown of what tool might be best suited depending on what you’re trying to do, and saves you days of research and POCs. There’s also a discussion in the comments that goes into the nuances of each platform’s affordances, if you need more detail.
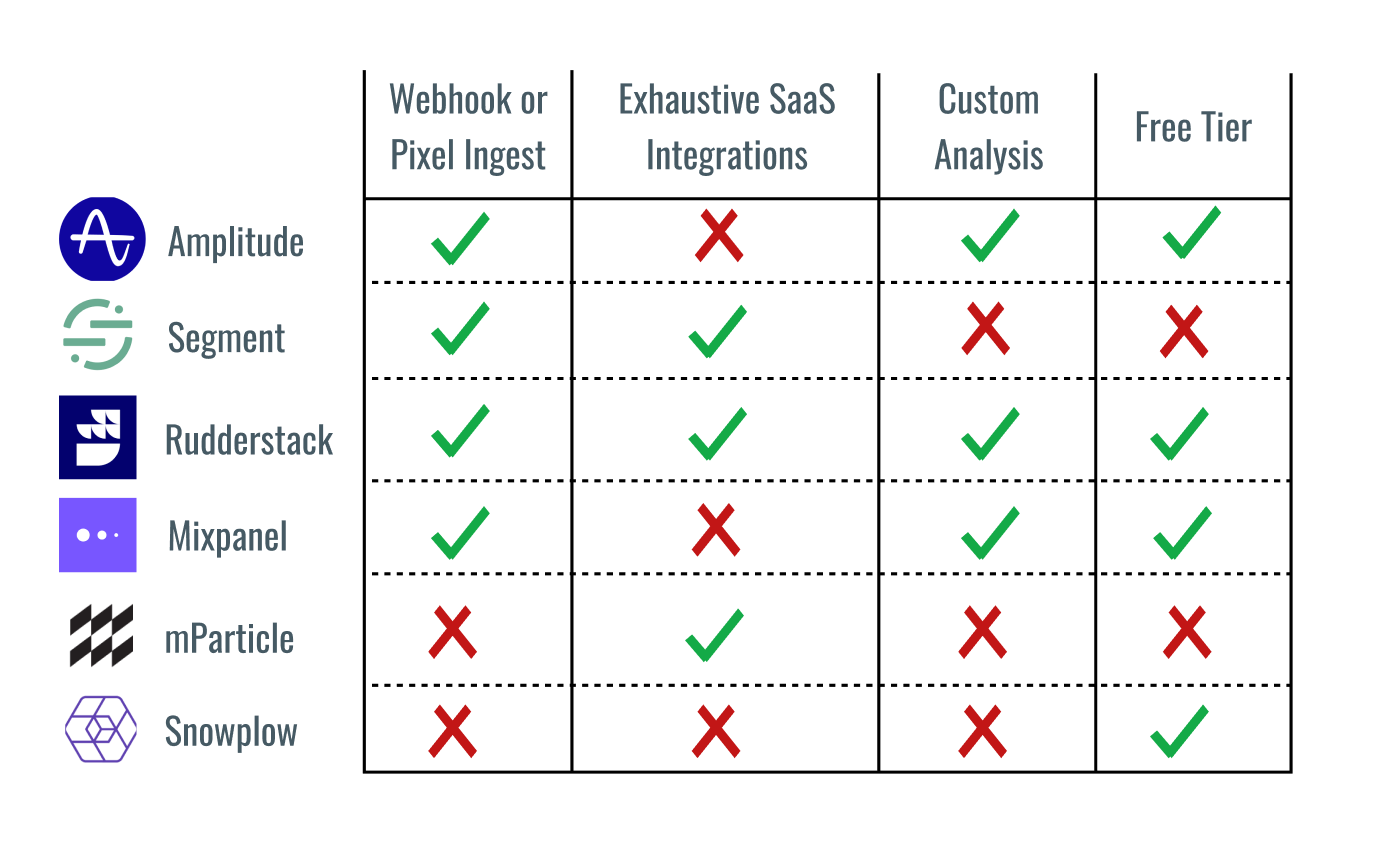
Thank you Sarah, this one is also going in my regular quiver of bookmarked articles!
Lessons Learned when scaling dbt models quickly
by Wei Jian
In my last roundup, I spend some time talking about the natural consequences of enabling more data humans to collaborate on a single code base — more complexity. This sparked a very interesting debate about to what extent we should spend more time building a data model right the first time, versus get something out the door that’s messier.
I think Wei Jian has done a fantastic job digging into this dichotomy, and pointing out that these are not, in fact, mutually exclusive ideas:
Pipeline scalability matters as its usage increases. We can spend a long time building the perfect data pipeline to support a business requirement, but if no one uses the data, or the business context changes, all our punctilious effort would go to waste. In that case, build and ship them quickly, and work on optimisation when more stakeholders are using the data, or drop it if no one does.
Additionally, I found the distinction Wei Jian draws between building something “properly” and building it “right” exceptionally insightful:
building it properly (as how I would define it) is building dbt models that follow best practices, consistent style guide, and readable SQL. Building it right requires more careful thought, because not only do we want a pipeline that transforms data we have now, it considers scalability and code reusability in the future; we want to make sure we cover all bases and build it once, so we don’t have to revisit it every time there are new changes.
Here’s why this distinction matters:
knowing that the business is unlikely to wait until your data is perfect means that data professionals have to make a tough trade off between moving fast and building for the future.
however, because of things like easily accessible data modeling best practices, version control, testing, dedicated development environments and various affordances like linting and diffing in CI/CD, moving fast no longer means working inefficiently. It’s now possible to write readable code quickly, get the data you need in the shape you need it with a lot less delay, and document it for the next person.
the sacrifice you make when you do this is you do less to optimize for the future — you skip over columns or aggregations you don’t directly need because others can build on top of your work. You also skip over unnecessary complexity like building an incremental model when you aren’t really sure how you’re going to use the data yet, because you’re trading off costs of running the query versus weeks of your development time (no brainer!)
that doesn’t mean you never optimize for the future — and Wei Jian has exactly the right criteria that helps you figure out when you should do this: how many folks are going to use this downstream? A couple? Your whole team? Multiple departments across the business? Your level of investment will vary!
If this still doesn’t sit quite right, think about how software engineering teams tradeoff velocity and robustness of what they’re trying to build. Most engineering teams don’t make an architecture diagram and then spend months implementing a totally feature end to end — they work iteratively, building out a minimally viable product that tests the idea, and as they prove out its utility with users, they expand functionality and focus on scale.
Wei Jian’s article has a ton of other good advice, like how to actually create an environment that allows you to move quickly on your data models but continue to build properly. Highly recommend reading the whole thing!
Using BigQuery change data capture with dbt incremental models
by Jay Lewis
Something else I’ve been thinking about since my last roundup is how to make incremental models perform better, while preserving some of that development velocity that Wei Jian talks about above.
Jay Lewis’ quick demo of BigQuery’s new change history feature in combination with dbt incremental models is a very cool step in this direction:
Avoiding table scans? ✅
Cost reduction? ✅
Faster query response time? ✅
Easy to update your existing incremental models? ✅
Any takers to do a similar tutorial for other warehouses? ;) Looks like Snowflake has a similar concept, as does Databricks — would be so cool to see this in a cross-db macro!
What are we missing in data CI/CD pipelines?
by Ivan
CI/CD in data workflows has come a long way! For starters, the concept exists and works ;) But just as tools in the classic software development lifecycle (SDLC) evolve to become more efficient, so too should data equivalents.
This article from Ivan is a really fun thought experiment on some of the next low hanging fruit in data specific CI/CD improvements:
using a hash to avoid re-running the same transformation if no code changes were made 🤯
if every git branch off your data model code base needs its own dedicated data build environment (and likely dedicated schema) to enable testing on live data while avoiding conflicts, how do you avoid copying all that data all the time across schemas? Snowflake has a zero copy clone we covered in the last roundup, but not every warehouse solution does. I think Ivan’s imagined solution of being more aware of the state of a DAG to cleverly avoid copying things your code doesn’t modify is spot. on.
making data integration testing better could be as simple as enabling the ability to roll back a change if certain tests fail in production — imagine all the hours saved backfilling date partitions with incomplete data!
Good stuff Ivan! Thanks for writing this up!
Building a centralized data warehouse security framework, pt 1
by MuleSoft’s Data Engineering team
And last, but not least, the first part in a series of articles by the data engineering team at MuleSoft on how they handle data access permissions.
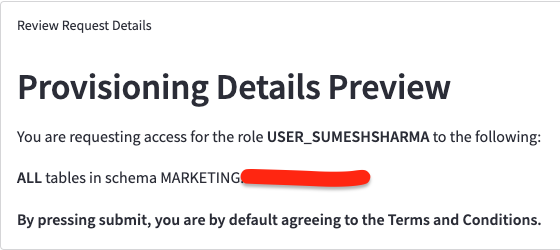
This is another yet-to-be-solved problem in the MDS so for now, teams are stuck rolling their own solutions. The description of the architecture the team used to solve requesting access to data and granting it in an automated and self-service fashion is accessible and reasonable to implement internally.
If you’ve been thinking about how to solve this problem yourself, definitely stick around for the rest of the series. And if anyone is building this into the MDS, I would LOVE to hear from you :)