
The State of Data Science Survey. Stream Processing. New Research from OpenAI. [DSR #110]

Several articles this week that touch on stream processing in some way. There’s increasing attention on this topic and I expect that to continue. If you have interesting reads on this topic, please send them my way.
Enjoy!
- Tristan
❤️ Want to support us? Forward this email to three friends!
🚀 Forwarded this from a friend? Sign up to the Data Science Roundup here.
The State of ML and Data Science 2017
A big picture view of the state of data science and machine learning that shares who is working with data, what’s happening at the cutting edge of machine learning across industries, and how new data scientists can best break into the field.
The piece is based on a 16,000-response survey (the authors share the complete data set). Headline takeaways:
While Python may be the most commonly used tool overall, more Statisticians report using R.
On average, data scientists are around 30 years old, but this value varies between countries. For instance, the average respondent from India was about 9 years younger than the average respondent from Australia.
The highest percentage of our respondents obtained a Master’s degree, but those in the highest salary ranges ($150K+) are slightly more likely to have a doctoral degree.
I loved playing around with the interactive charts—there’s good stuff in there.
Big Data Processing at Spotify
This is an awesome history of data processing at Spotify, from batch jobs written in Python and Luigi to streaming jobs written in Google Cloud Dataflow and their own tool called Scio. They’ve done lots of thinking about stream processing and have some great commentary on it.
The Spotify team is executing at the frontier of what is currently achievable; this story isn’t just about them, it’s also a story of the evolution of an industry.
I have no opinion on this specific package, but this is the first time that I’ve come across a way to combine standard viz mechanisms with streaming data. I love the concept of tailing a pandas dataframe. See below.
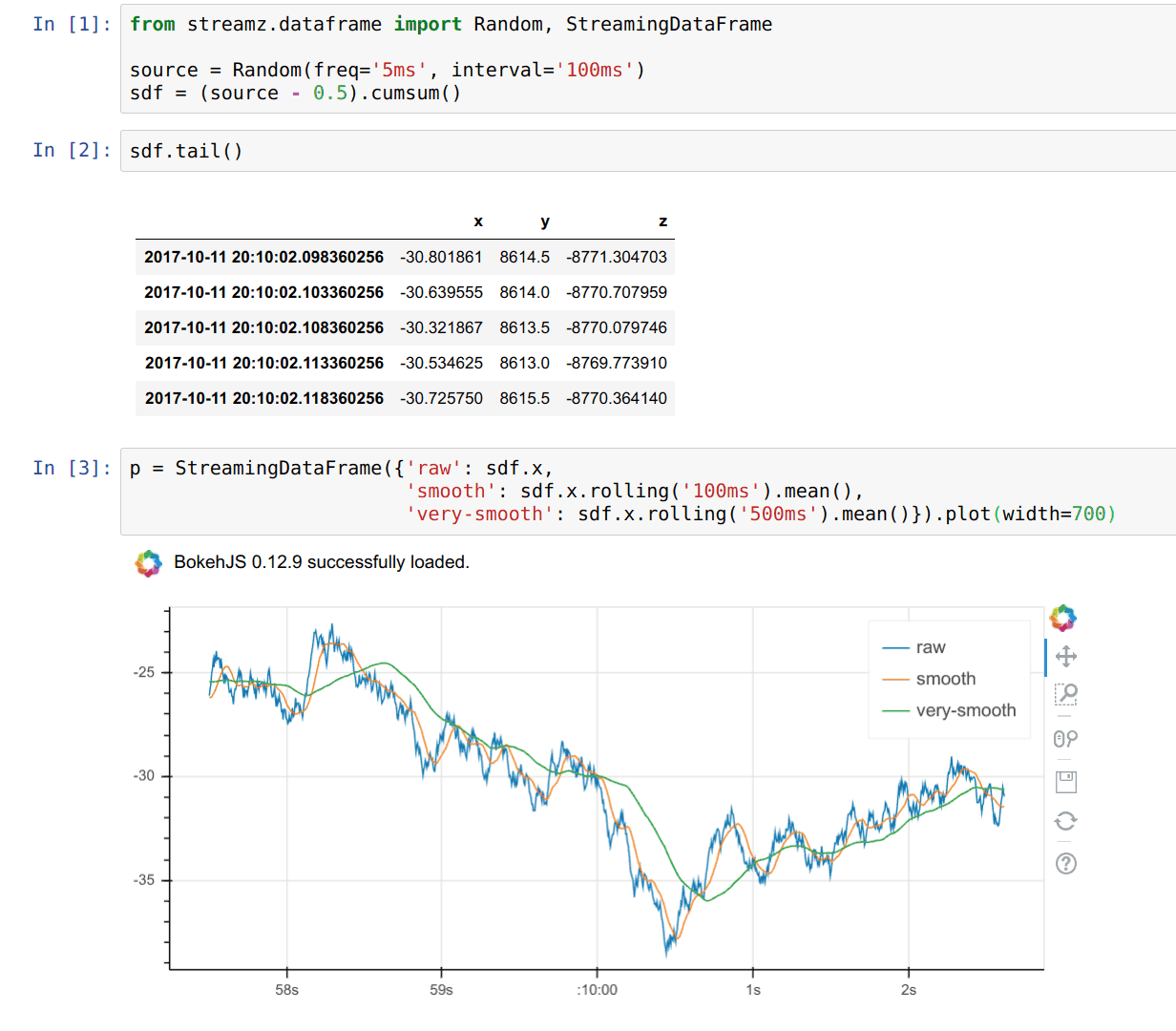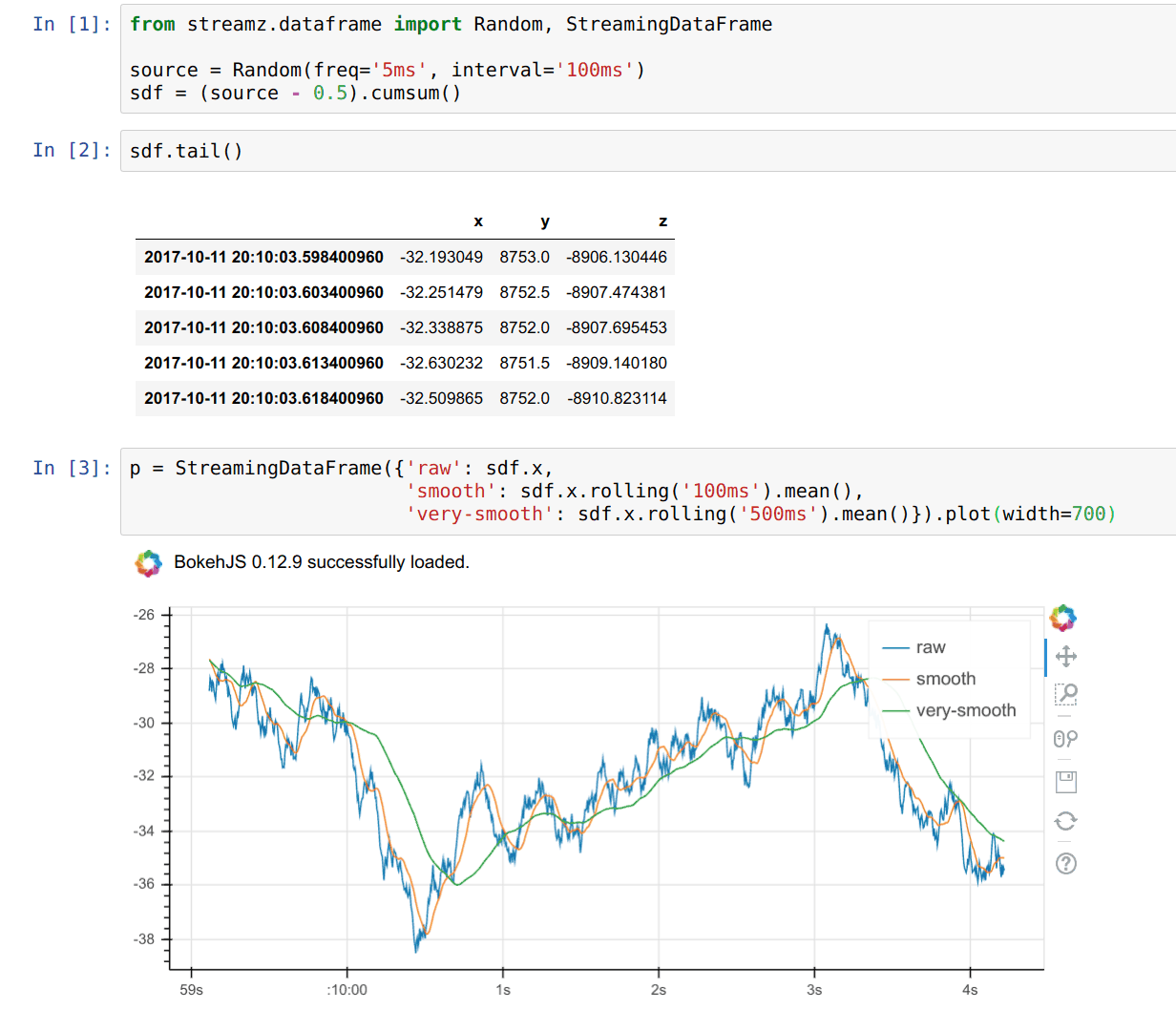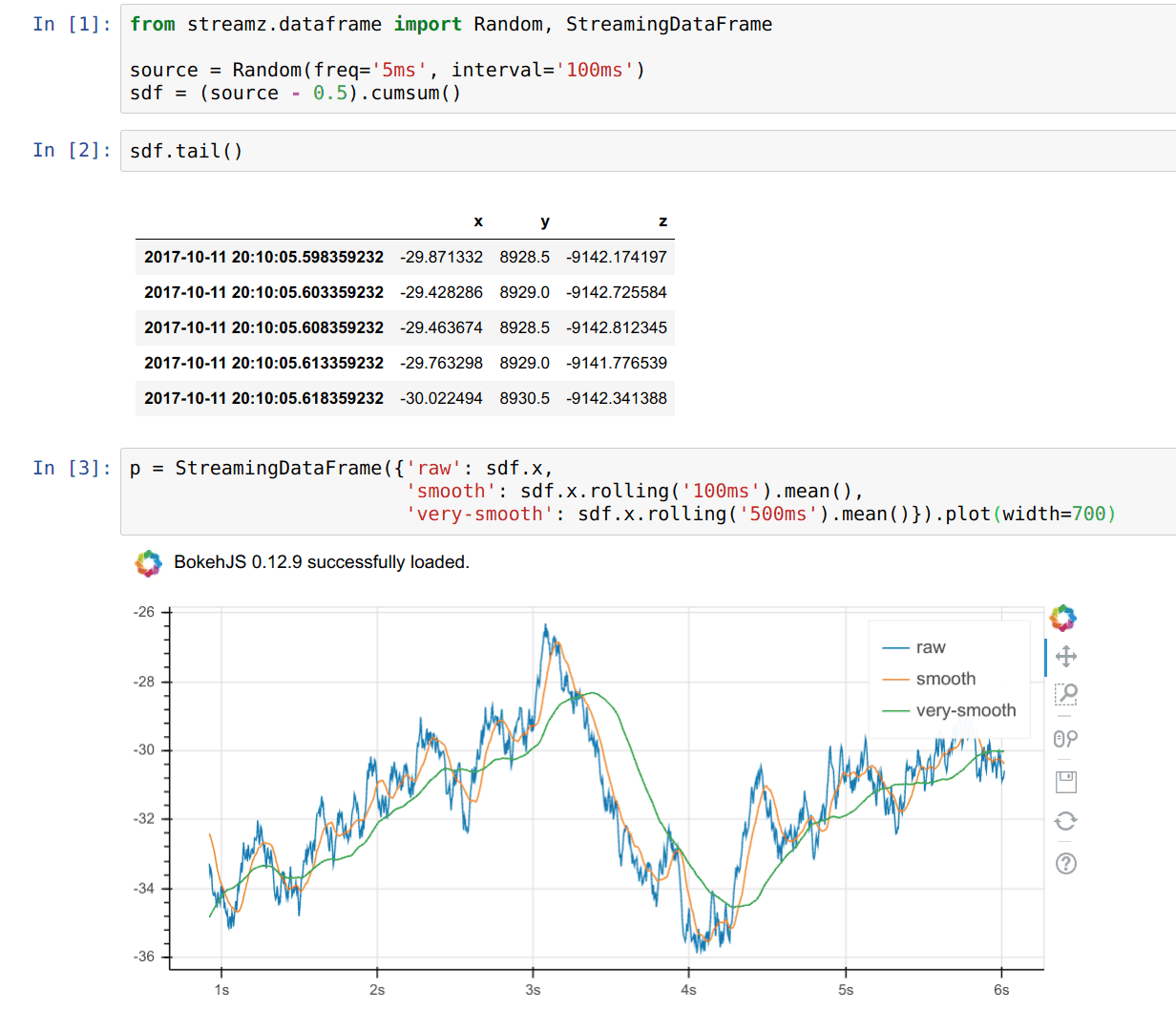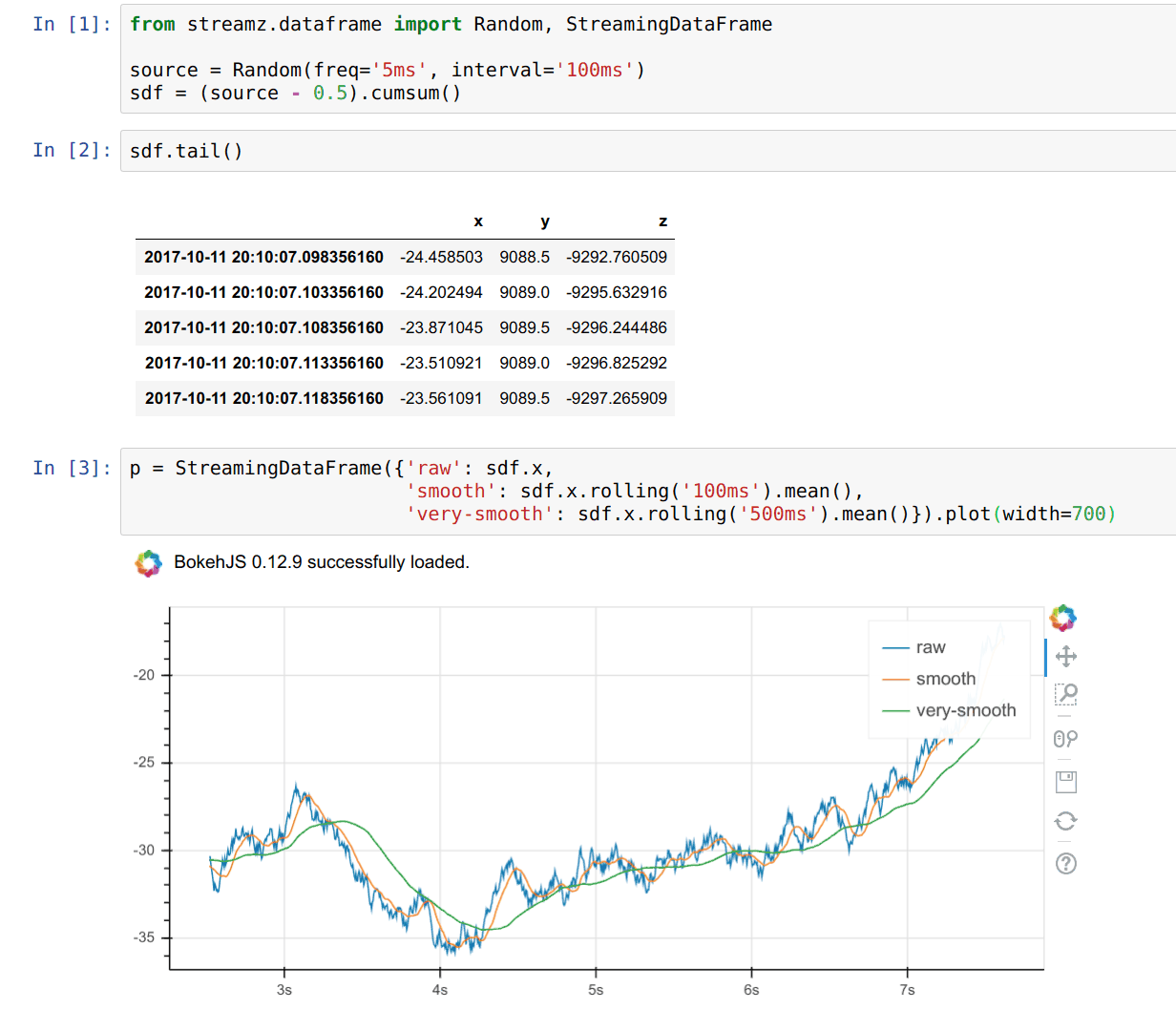
'We can't compete': Why Universities Are Losing Their Best AI Scientists
Interesting piece on the talent drain from academia to industry within AI. I am not sure that I completely agree with the post that this is necessarily a bad thing—there is plenty of fundamental research being conducted and published from big tech cos, and if that’s where the resources are to get the work done, maybe that’s ok.
Related piece from the NYTimes. This trend isn’t going anywhere any time soon.
From OpenAI:
We’ve developed a hierarchical reinforcement learning algorithm that learns high-level actions useful for solving a range of tasks, allowing fast solving of tasks requiring thousands of timesteps. Our algorithm, when applied to a set of navigation problems, discovers a set of high-level actions for walking and crawling in different directions, which enables the agent to master new navigation tasks quickly.
The video below is short and excellent:

Learning a Hierarchy - YouTube
Wow. 8 years to 1.0. This post is an awesome read to get a download on the Kafka vision and current status.
Kafka has become one of the most important pieces of technology in the modern data stack and powers the internals of many of the systems you likely interact with. Stitch, for one.
Data Viz of the Week

Click through for much more. Love this.
Thanks to our sponsors!
Fishtown Analytics: Analytics Consulting for Startups
At Fishtown Analytics, we work with venture-funded startups to implement Redshift, Snowflake, Mode Analytics, and Looker. Want advanced analytics without needing to hire an entire data team? Let’s chat.
Stitch: Simple, Powerful ETL Built for Developers
Developers shouldn’t have to write ETL scripts. Consolidate your data in minutes. No API maintenance, scripting, cron jobs, or JSON wrangling required.
The internet's most useful data science articles. Curated with ❤️ by Tristan Handy.
If you don't want these updates anymore, please unsubscribe here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue
915 Spring Garden St., Suite 500, Philadelphia, PA 19123