
The Threads Converge - the shaping of dbt multi-projects

If you’re a regular reader of this newsletter, there are a few threads that you know are important to watch:
Lessons that the analytics industry can learn from software engineering
How to wrestle with the complexity of large scale data organizations
How to make it so individual data practitioners can spend more time doing valuable work and less wrapped up in the things they don’t want to do
This week Tristan released a blog post that is perhaps the most significant statement on these points that dbt Labs has put out in several years.1 The post outlines upcoming changes in dbt v1.5 to allow for dbt multi-projects. These are building blocks that will eventually enable different dbt projects to speak to each other and build towards a unified data system. This will fundamentally change the way organizations, particularly large organizations, use dbt across:
Access
Contracts
Versions
Before you do anything else, stop and go read Tristan’s blog.
(waiting)
(waiting)
Ok now that you’re back - let’s talk about this!
This is a significant evolution for dbt and analytics engineering. Where did this come from? Why now? How can the Community shape this moving forward?
These are all excellent and important questions. The answers to these questions are always complex and multi-faceted, but the best approximation we can give is - this came bottoms up from data teams telling us they need us to solve for complexity in large data projects. Before we go any further, let’s record scratch / freeze frame and talk about how we got here.
You’re probably wondering how we ended up here
It started, as many great things do, with a GitHub discussion. There’ve been whirlwinds of conversations on how and why people want to handle multi-repo dbt projects for a long time, but momentum really started building when dbt Core PM Jeremy Cohen posted a discussion on May 13, 2022: what would it look like to have better mechanisms for cross-project lineage?
Little did we realize at that time how significant this thread would end up being. This question sparked a trickle, and then a flood of dialogue.
First was my teammate Winnie who chimed in with a thoughtful reflection and distinction between monolith vs. monorepo.
Next up, Community member Rogier Werschkull brought the term “data mesh” into the conversation, to which I’m sure many of us nodded our heads and cracked a slight smile of delight.
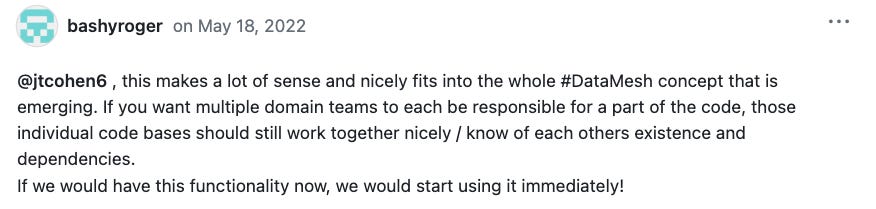
A few weeks went by without too much activity on the thread - but these conversations weren’t just taking place in Github, they were taking place in the Community slack, at our meetups and in calls with customers. Eventually Tristan returned to the thread and made it clear that this was something we needed to be watching carefully.

Gettin’ Prototypin’
I had my own moment when I realized that this wasn’t a nice to have - it was a need to have.
One notable day, I entered into a demo with a potential customer thinking it was going to be a slam dunk. When they started talking, the prospect innocently asked how “dbt handles multiple projects” and just assumed we figured it out given our growth and adoption. They told me they’re using dbt, and I simply presumed they should be in a monorepo setup. So I went through my usual spiel and hammered in talking points similar to this video tutorial.
But I was met with blank stares, and he replied back they were already setup with their own custom coordinating of multiple dbt projects and wanted to know what our official solution was. But alas, I couldn’t give him an answer I was proud of, so we left the conversation there.
It was time to get prototypin’.

I rolled up my sleeves with two teammates - Doug Guthrie and Matt Winkler and began dreaming about what a solution could look like:
Even after all this work, I wrestled with inner doubts thinking I was overcorrecting for my bruised ego in the earlier demo conversation. Thankfully, I was wrong! I was pleasantly surprised how many community members raised their hands to talk with me. One person, Jonathan Neo, showed up strong in public and gave incredible input into contracts.
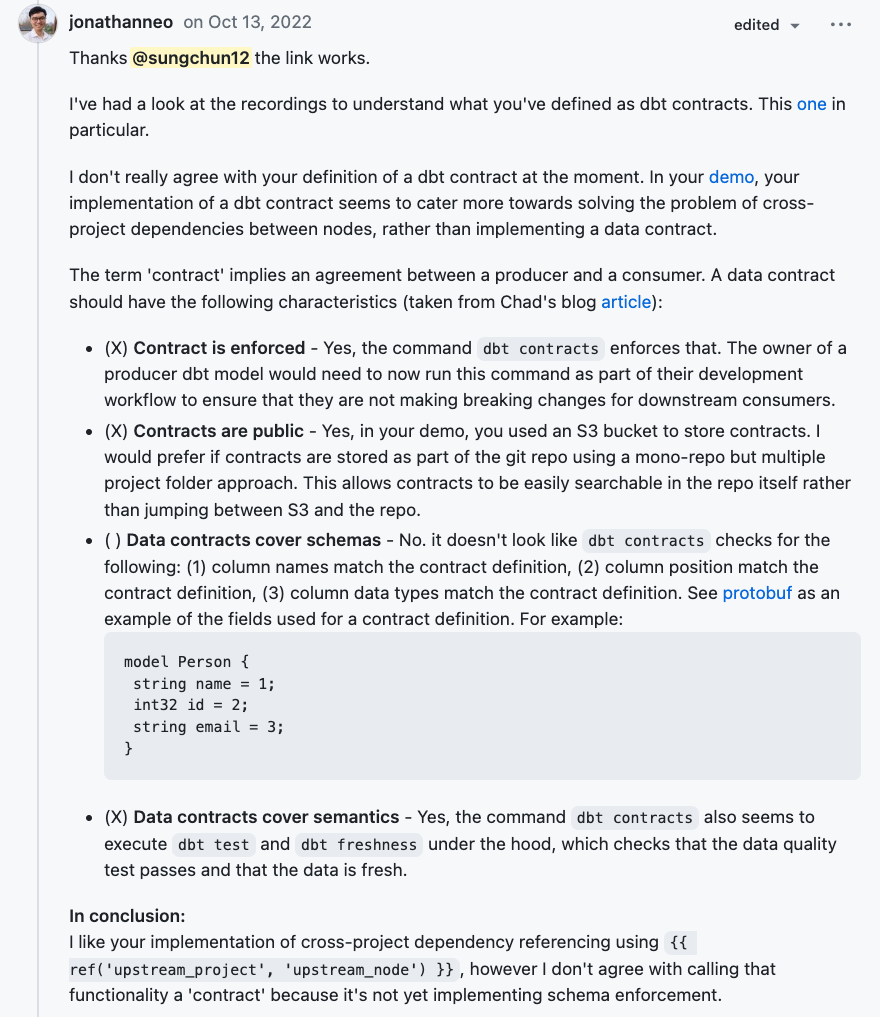
And then Brandon Segal chimed in with cool stuff they’ve done to approach the multi-projects problem.

When I called for help, the dbt Community, rallied from all over to:
Help by building it hands-on with us(like actually help)
To talk with Tristan about what the problems are in detail and what a solution should look like
Multi-projects had gone from Community concern to proof of concept and it was time to make it official. Jeremy made it real and in public with an updated GitHub Discussion on multi-project deployments and we were cooking.2
And now with dbt v1.5 coming in the end of April, it’s going to be in the hands of the Community.
Let’s build this together
This next phase in dbt would not have come together without the dozens, hundreds of individual conversations, blog posts, newsletters and slack posts from people across the industry and across the Community. Whether you were an active participant in Data Contract Discourse, you had a conversation with a friend at another org or you just followed along with this conversation - you’ve been a part of developing this as well.
But the constructs released in dbt v1.5 are just the framework and the building blocks. How this actually gets used, adapted, and integrated into data organizations is going to be battle tested by you. We’re once again at an inflection point, like when the dbt Viewpoint was published, like when the Modern Data Stack began to rise. We’re in uncharted territory here, and I’m so glad WE get to figure out where this goes!
In the words of dbt Community hero Natasha Bedingfield, the rest is still Unwritten. If you’d like to help us write it, try out the new constructs in dbt V1.5 and come share your thoughts on dbt Slack in #dbt-core-multi-repo or wherever you are inspired to share.
Previous important posts include The Modern Data Stack: Past, Present, and Future and the dbt Viewpoint
And building this side by side with the Community kept going through things like this Community Feedback Session and ergonomics deep dives on model versioning
 | A guest post by
|
Great article - although I don't really buy-in to the fuss around orchestrating multi repo dbt projects - just use an Orchestrator? The only reason this is a problem for dbt is because it is a synchronous SQL query-based engine...