
The 5 principles of self-service analytics
What is a metrics taxonomy? Why is experimentation so hard? Pandas' evil twin, the divergence of analytics and ML architectures, and taking back the discourse on the business value of data.

🎊🐯🎆Happy Lunar New Year to everyone celebrating this week! 🎆🐯🎊
🔌 A smol plug before we dive into regularly scheduled programming:
How dbt Labs calculates an important (and thorny!) business metric called “Time on Task”
In case you didn't get enough of Dave Connors and his dad at Coalesce in December, he (Dave, not his dad) has just published an excellent technical write up in our new Developer blog complete with sample code on GitHub. If you’ve been struggling with calculating time intervals during “business days”, check out his write up, and tell us how you've solved this problem in your organization.
Enjoy the issue!
-Anna
Productizing Analytics: A Retrospective
By Emily Thompson
Today's feature article has something for everyone:
About to embark on your first self-serve data adventure? ✅ This post has a solid set of principles you can use to frame your solution.
Tried a few times (with various levels of success) to run your analytics function like a product team? ✅ This post will commiserate with the challenges you most likely ran into along the way, and offer some steps forward.
Seasoned self-serve analytics/data-as-a-Product veteran looking for a great write-up to share with others? ✅ Bookmark this post, you’ll be coming back to it.
Emily’s piece is wonderfully self-reflexive and full of great lessons. She’s not prescriptive in her writing, but perhaps she should be ;) As I read through her retrospective, I can think of at least 5 very actionable things that everyone needs to take away from this piece if you’re looking to design a delightful self-serve data experience. (bonus points if you read that in your best Buzzfeed voice)
I’m writing these on my wall, and so should you.
1) Start with an intuitive metrics taxonomy.
What is a metrics taxonomy and what makes it intuitive? Emily writes about a set of canonical dashboards and reports that represent a “truth hierarchy”, that is the most trusted data in the organization. You could interpret this as “I need to list the dashboards and datasets that I trust the most and put them somewhere visible”.
But I don’t think this is what Emily means when she says “metrics taxonomy”. A taxonomy is a form of classification. Therefore a “metrics taxonomy” must allow its users to navigate metrics by classification. To do so, it must be opinionated. It must also reflect the most important concepts in the business and how they relate to one another.
A metrics taxonomy is not just a list of metrics like ARR, Churn Rate, Daily/Monthly Active Users. It is also the context that connects them:
How does current account churn rate affect the business’ ARR projections for the fiscal year?
What is the relationship between growing Active User numbers and recurring revenue?
What are the top three things the business is doing this year to drive its revenue goals, and how is this represented in your metrics?
This context, this connective tissue, is what makes metrics “intuitive”.
“But that takes a lot of work to build!”, you might say. Yes, that’s exactly the point. Emily has a fantastic diagram that represents this trade-off well: the closer to the access layer for your self-serve customers, the more curated the set of products, and the more engineering time is required to get there. You have to be very selective about what you focus your attention on, and optimize for maximum business impact.

2) Keep your metrics taxonomy simple
Business metrics are a framework that should help everyone in the company speak the same language about its progress, challenges and opportunities. This framework must be not only standardized and accessible outside of the data team, but it must inspire action for the rest of the company. If the rest of the business doesn’t understand how your business metrics work, you won’t succeed in aligning the company behind them.
How can you tell if your metrics “work”?
Can anyone in the company tell you what your company’s top 3-5 performance indicators are?
Can they tell you how those metrics are defined?
Do they understand what factors drive those metrics?
Do they believe they have agency to influence those metrics?
If the answer to any of those is “no”, there’s more work to do!
3) Develop a maintenance strategy and SLAs
As soon as you venture into the world of productizing your analytics, you need to start thinking about your metrics, datasets and documentation as products. Products have customers, and customers have uptime and availability expectations.
Do you know what those expectations are?
How many humans are using your self-serve infrastructure weekly?
If some of your data is delayed (either due to ingestion or maintenance you need to do), how many humans are affected?
What is their reporting cadence? Daily, weekly, start of the month, end of the month?
What important decisions are being made, and when are they being made?
What are the most “critical” times for data usage in the business? (e.g. Month End/Quarter End close for the sales team, high reach marketing campaigns, in-product experiments).
Does your SLA meet the needs of your data customers when they need the data?
Does your maintenance strategy take into account usage that if disrupted, would be business-stopping? What about business delaying? ;)
4) Remember that your data team are your customers too
Self-service analytics is not something you set up once and walk away from. It is a system that is constantly evolving alongside your business. As your customers develop more insights, they need to be integrated and shared with the rest of the business. Objectives, definitions, and data sources will change. The platform you are using will need upgrades and bug fixes.
A good experience for your data developers will result in a better customer experience down the line. The lower the barrier to entry to work with and improve the system, the better it will keep up with the pace of the business:
How painful is it for your data team to identify data problems like inaccuracies, delays and inconsistencies?
How long does it take your data team to fix them?
Can the person closest to the analytical insight easily improve your systems, documentation, and fix errors?
What is the ratio of bug reports your customers file to the number of times your customers improve the data model themselves? This measures the accessibility of your product to your customers. The best self-sustaining self-service systems will have a healthy ratio of customers working to improve documentation, edit and update metrics, and even implement fixes in the less curated layers of your self-service stack.
5) Keep a pulse on whether your self-service data product feels good
Finally, does it feel good to use your data product?
Emily called this the “fuzziest” of her principles and has partnered with user researchers to help define and monitor how the system felt for her customers. This is an amazing practice and I highly recommend for everyone to partner with a great qualitative researcher at least once to help you quantify and make known things that have previously felt squishy.
But what if you don’t have access to a great user researcher? There are a few things you can look out for:
Do users of your self-service data come back frequently or are their interactions one off?
Do you see your users progress in complexity of usage? In other words, does the level of self-service they can do increase over time?
Do new humans begin exploring and using your self-serve analytics products organically, or do you feel like you need to chase people?
How do you and your team talk about your customers? Are they “non-technical” and in need of “education”? 👎 Or are they domain experts whom it is your job to enable to be successful? 👍
Thank you Emily for the delightful food for thought this week 👏👏👏
Elsewhere on the internet…
The Experimentation Gap
By Davis Treybig
This article by Davis Treybig hits home on a number of fronts. Davis talks about the gap between large (mostly technology) companies and their successful experimentation practices… and pretty much everyone else.
Davis points out (and I agree) that experimentation tooling is not yet where it needs to be to make it easy for small data teams and small engineering teams to make experiments work. Tools today remain fragmented — often focused only on web properties, and even then, desktop web properties. Meaningful product changes, user experience improvements and other in-product flows remain the domain of bespoke solutions and manual implementations or integrations.
If your experimentation is blocked on data humans instrumenting and analyzing results, and you’re not able to run more than a few experiments a month — you’re not alone.
Davis also underscores another important blocker that is harder to observe but even more damaging: a lack of an experimentation culture.
Cultural problems tied to experimentation can surface in a number of ways. Leaders and executives may be used to an environment where they can make gut-based decisions all the time, and struggle in cases where their gut is dissonant with the data. Employees without a statistics background may not understand the utility of experimentation, or may feel overwhelmed due to an unfamiliarity with statistical concepts. Teams may have simply never felt the joy of discovering an unexpected or unintuitive facet of user behavior via data, or the empowerment that comes from being able to rigorously quantify the impact of their work.
Building data-informed decision making culture is hard. Building experiment-informed decision making culture is harder. And it is harder still if the cost in time and human effort to run experiments is very high. Right now, only a few players can pay that cost and afford to develop the mostly internal tooling required to do this truly well.
Maybe the answer here is predicated on the data OS and the entity layer? On the blurring of the lines between analytical data and application/production data?
I can’t wait to see where the industry takes us next in this space. There’s still so much innovating to do!
Emerging Data Architectures
By Sudheer Sandhu By Matt Bornstein, Martin Casado, and Jennifer Li
[Edit: an observant reader has pointed out this is a copy of an article first published in 2020. Author credits and link have been updated above. Thank you for the sharp eyes, Will 🙏]
As a qualitative researcher in my past life, there’s something incredibly satisfying to me about seeing a framework presented based on a series of interviews. Especially when the framework in question is based on interviews with CEOs of some of the hottest companies in the data space.
The key question going forward: are data warehouses and data lakes are on a path toward convergence? That is, are they becoming interchangeable in the stack? Some experts believe this is taking place and driving simplification of the technology and vendor landscape. Others believe parallel ecosystems will persist due to differences in languages, use cases, or other factors.
On the one hand, we have this complex and detailed architecture diagram representing what it would look like to design your data infrastructure to support both analytics and machine learning use cases.
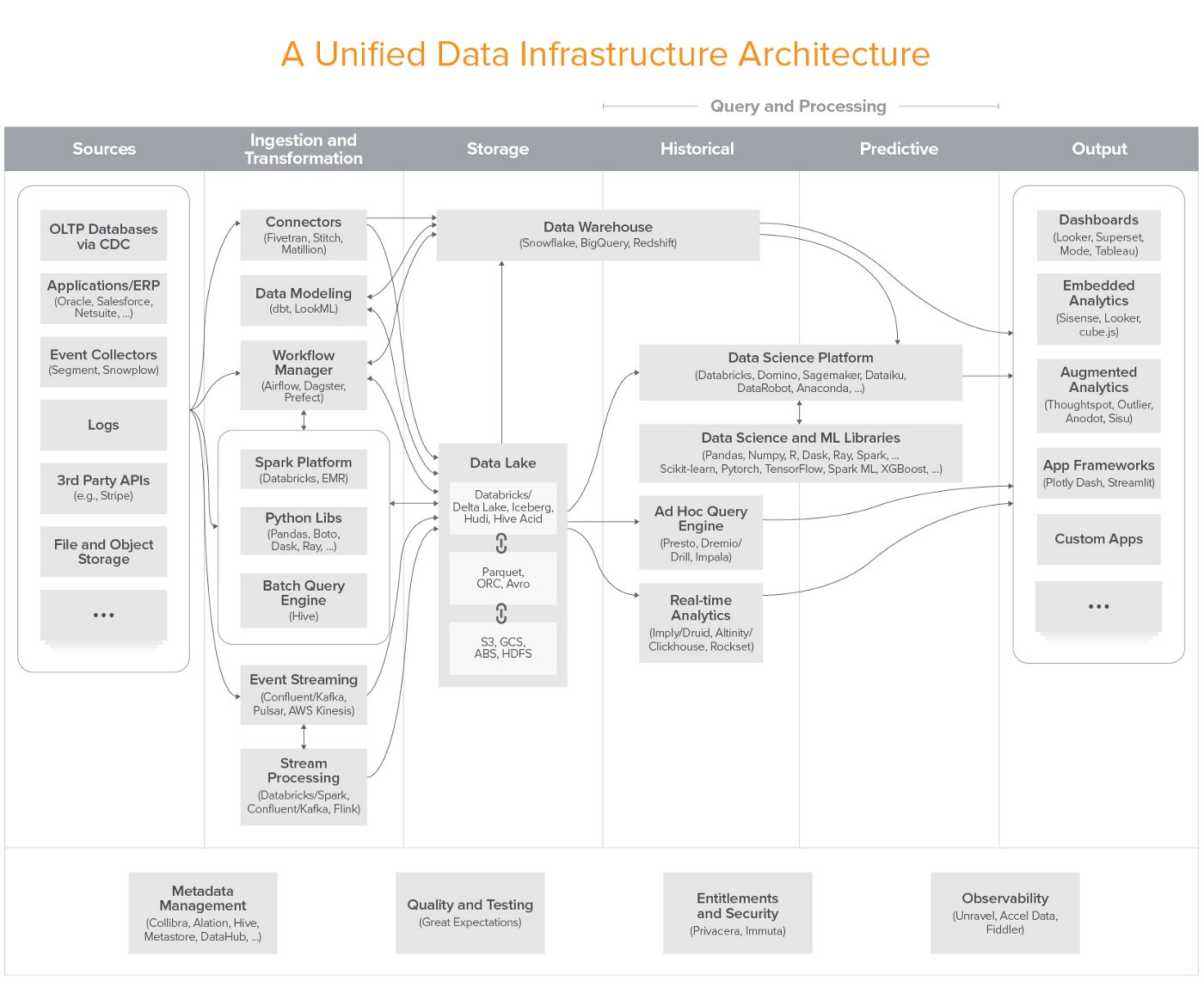
Crucially, you can get started with a smaller subset of these for analytics purposes, and then expand your footprint later.
{kind=link}
And on the other, here’s the ML-oriented architecture the industry is converging on:
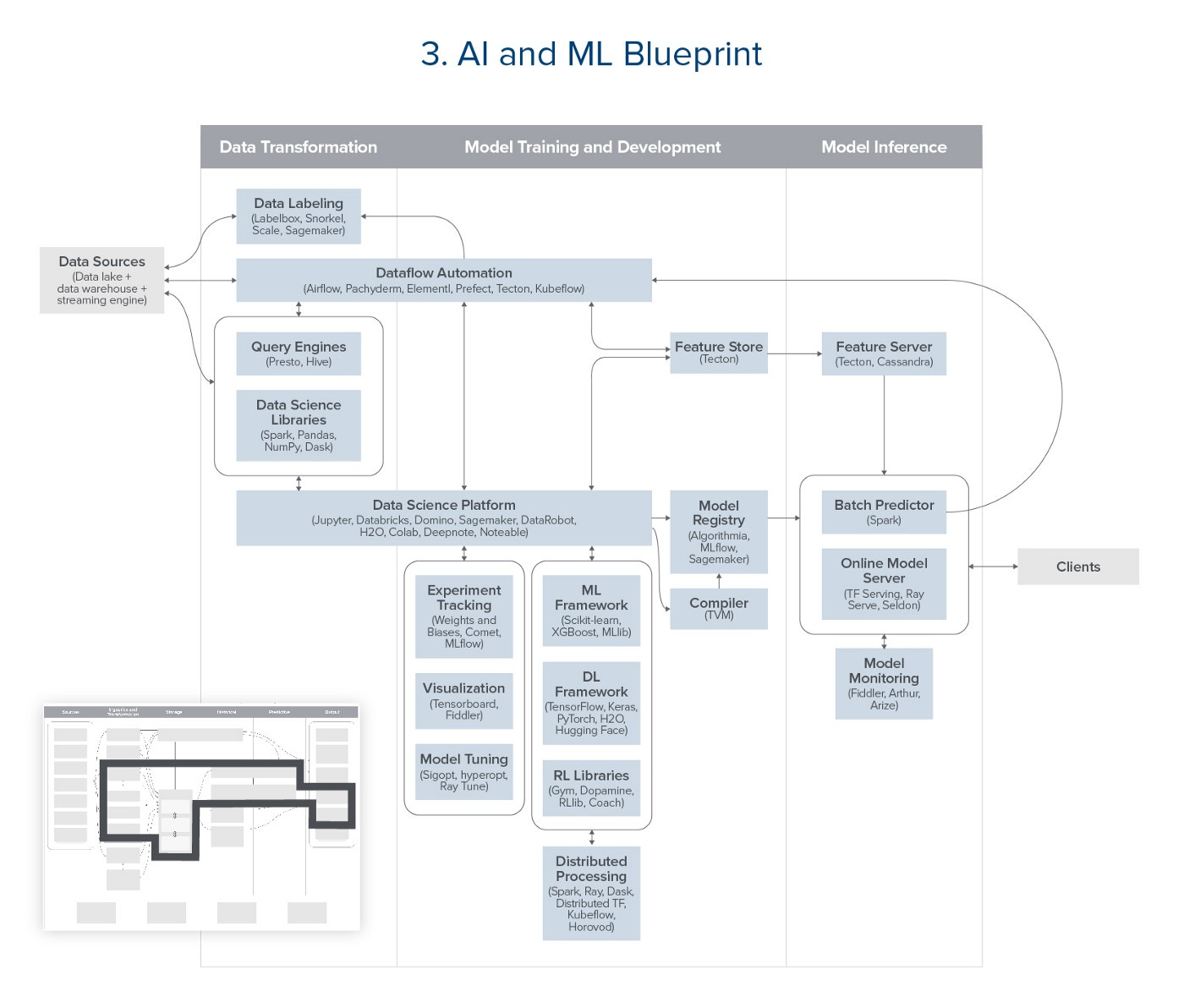
It’s a completely different set of workflows! An entirely different transformation layer and mode of data access. We've danced around this topic before in this Roundup — the analytics and machine learning worlds rarely speak to each other, and it's no surprise that our tools don't either.
Is this a problem? And for whom? Is this only a challenge faced by companies built around data products? My gut says “no, this is a problem all of us should be concerned with”.
There's so much possibility unlocked by sharing data models across analytics and machine learning use cases — predicting customer churn, lead scoring, experimentation that goes beyond a/b testing…
We need to move toward the unified architecture model for the health of our businesses, the happiness of the humans who work with and integrate these systems, and for their long term career development.
A related good read: the data folks at T-Mobile wrote a great guide on building a modular MLOps stack at a large enterprise. Spoiler alert: key to its success was an in-house solution.
Good-bye Pandas! Meet Terality — It’s Evil Twin With Identical Syntax
by Bex T.
Speaking of data science and ML workflows… did you know you can run hosted Pandas for that extra compute you might need munging a giant data file?
The question is — why would you want to do this on data this large? It makes sense that one may want to explore novel datasets, maybe even work with data that is unusually structured (geolocation data perhaps?). But do we need a hosted Pandas solution, or do we need to shorten the iteration cycle on data transformations we’re already doing elsewhere?
The other question is — how do we, as an industry, feel about someone building a company around Wes McKinney’s very much foundational open source infrastructure, the Pandas project? That is, someone who is not Wes? :) I’m reminded of Jupyter/Colab, and here hoping the folks behind Terality are contributing something back to the community that developed Pandas.
Data is the New Motor Oil
by Stephen Bailey
It’s fabled that what took a team of engineers six months to build ten years ago can now be done in one week by a gritty data analyst.
But your mother isn’t trying to build what a team of engineers was building ten years ago. She is building her own business today, and she wants to know why you think she should invest a significant chunk of her cash influx into — wait for it — creating a bunch of dashboards.
Stephen’s writing has quickly become a much anticipated event at dbt Labs, and his latest piece does not disappoint.
Humor and satire exists to drive home a point, and this week it is this: you, as a data practitioner can and should set the narrative for how the rest of the business values your work. And the narrative isn’t “we build dashboards”. The narrative is this:
The point you are making, beneath the interview, is that if the company is successful, a lot is going to change — but the destination is not. As those changes happen, there is going to be debris from old systems and ways of doing things that might get in the way of the bigger picture.
Someone needs to be able to step in, mediate consensus, flush out debris, connect the old and new, so that the company can focus on moving towards the future. That can be the data team.3
Boom!
Why Working at Google is Bad for Data Engineers
by Galen B.
I’ve written before on the changes that are happening in how Data Engineering roles are defined. That is, that Data Engineering will increasingly look more like platform engineering at larger enterprises, and ML Engineering at companies built around data products.
Galen’s piece is a take on what it feels like to be a Data Engineer at one of these larger enterprises, and their take on the future of the career. It is very honest, and doesn’t pull punches.
Thank you for sharing this, Galen!
That’s it for this week :) See you again in a few 👋
The connective thread that emerges for me through each of these different areas of discourse from self-service taxonomies, to experimentation, to underlying architectures, and finally to enduring (with humor) through change is... the future will benefit from a more ✨purple✨, holistic approach to what an organization wants to know about itself.
(https://blog.getdbt.com/we-the-purple-people/)
I find myself anchored to that question as I approach new work -- what do we want to know about ourselves? The answer to this question starts to define the data, systems, and process required as you and your team do and build things.
Separating the work of defining your analytical and information systems from the work of the activities that produce the data is a disservice to everyone imo (and experience).
Taxonomies are a great starting point, but the relationships between things is actually where ontologies become relevant, both informing the strategy of your information architecture. I argue that prioritizing this in the long-term is the the ultimate strategic advantage (the moat of the future if you will).
Take it in strides, prioritize the most business critical information, but START NOW, and make everyone at least aware of the work and the goal...in the future, every team is a data team, working from a shared ontology. This is the key to unlocking systems of intelligence, and I believe that the metrics and entity layer have the promise to accelerate this pursuit.
taxonomy vs ontology: https://www.earley.com/insights/what-difference-between-taxonomy-and-ontology-it-matter-complexity
systems of intelligence:
- https://twitter.com/jillzzy/status/1466062420795957249
- https://news.greylock.com/the-new-moats-53f61aeac2d9
- https://www.reforge.com/brief/why-systems-of-intelligence-are-the-new-defensible-moats
- https://www.protocol.com/enterprise/saas-systems-of-intelligence