
How does column encoding work?
Step 1 on my journey to build an entire database from scratch!

Reader - I’ve been busy! We’re launching the dbt Semantic Layer at Coalesce in October (have you registered yet?) and I’ve put some personal projects on the back burner in the run-up to the launch. One of those projects is an attempt to build a columnar database from scratch. It turns out that building a database from the ground up (file format, sql parser, optimizer, and all!) is pretty hard work. My big goal for this project has been a pursuit of demystification: I don’t want to sweat the small stuff and I’m certainly not being academic about it, but I did want to prove to myself (and hopefully for anyone who follows along!) that there’s no magic behind the curtain of the tools that we all use every day.
Here’s an excerpt from Part 1: File Formats. If you’re into this kind of thing, I hope to have more of it to share with you sometime after October 17th ;)
-Drew
How does column encoding work?
In the pursuit of making databases go really fast, very clever engineers have employed a number of tricks to help databases do as little work as possible. This is a sort of fundamental insight about performance tuning: the best way to make something go fast is to avoid doing the thing at all. Column encoding is one of those very clever tricks.
Before we dig into column encoding, we need to talk briefly about how columnar databases work. When a columnar database goes to execute a query, it will:
read required data from storage
process that data based on the instructions in the query.

Different types of operations can take wildly different amounts of time for a computer to process. Reading data from storage (say, cloud storage like AWS S3) is slow, but performing a computation (like adding two numbers together) is extremely fast. If we wanted to make a query run as fast as possible, our energy would be best spent in optimizing the parts of the query that need to read data from storage because that’s the slowest part of the equation.

Let’s figure out a way to spend less time reading data from storage. You might intuitively know how we can accomplish this if you’ve ever downloaded a ZIP file before: we can compress the data! ZIP files use a sort of general-purpose compression algorithm that works well for things like images, documents, music, and so on. It turns out though that we don’t often store images, documents, and music in columnar databases – we store timestamps, text, integers, booleans, and all of our other favorite data types.
The cool thing about columnar databases is that data is stored in columns (of course!) and we can leverage the information we know about those column types to use a more efficient, more specific compression algorithm to shrink the footprint of data that’s physically stored in each column. We call this process “encoding”. The reverse process that decompresses the data is called “decoding”. This is where the name column encoding comes from.
Let’s look at some examples of column encoding to see how it works in practice. As we go, remember that everything we’re talking about is internal to the database and would be imperceptible to you when writing queries. We’re not talking about data modeling here – these are database-internal optimizations.
Dictionary encoding
Imagine you’ve got an orders table that’s one million rows long. This table has a column called “country” which contains the name of the country where the order was shipped to. There are obviously not one million different countries in the world, so we’re likely duplicating a lot of the same country names over and over in the data files that represent this column1.
We can take advantage of the fact that country names are repeated many times over to efficiently store this data. Let’s assign each country a unique number and then replace the country name with this number in the data file for this column. We’d also need to store a sort of dictionary that can reverse the process later when we want to query this column. Here’s what that approach might look like in the database’s own internal representation of the data:

The string “United State of America” is 23 characters long. If you tried to store this string one million times, that would take up about 23 megabytes of storage. If you instead tried to store the lookup value, “1”, one million times, that would take up 1 megabyte of storage (plus some small amount of storage for the dictionary lookup data). We’ve effectively shrunk the amount of data we need to store by 23x. In turn, this should make it 23x faster to load the data for this column from storage.
This particular type of compression scheme is called a dictionary encoding. Dictionary encoding works well for string columns when the string values in the column are relatively long and repeated many times over, but what happens if our column values are already small, as with boolean fields? It turns out that using a dictionary which maps FALSE and TRUE values to 0 and 1 is… kind of useless! In these cases, we can take advantage of other characteristics of the data to perform compression.
Run length encoding
Imagine that we still have that one million row long orders table with a boolean column called is_returned. Let’s also assume that only 1% of orders are ever returned. In this case, 99% of values in this column will be FALSE, while only 1% of them will be TRUE. Given this distribution of values, we should expect the is_returned column to contain long sequences of FALSE values interspersed with a small number of TRUE values here and there.
We can call these sequences of repeated FALSE values “runs” in the data, and we can use these runs to more efficiently store the data in this column. Basically, we can record something like “FALSE x 99” instead of storing the actual value “FALSE” 99 times in a row. This type of encoding is called “run length” encoding, and it works by distilling down many repeated sequential values into two parts: 1) a value and 2) a repetition length. Let’s see what that looks like in practice
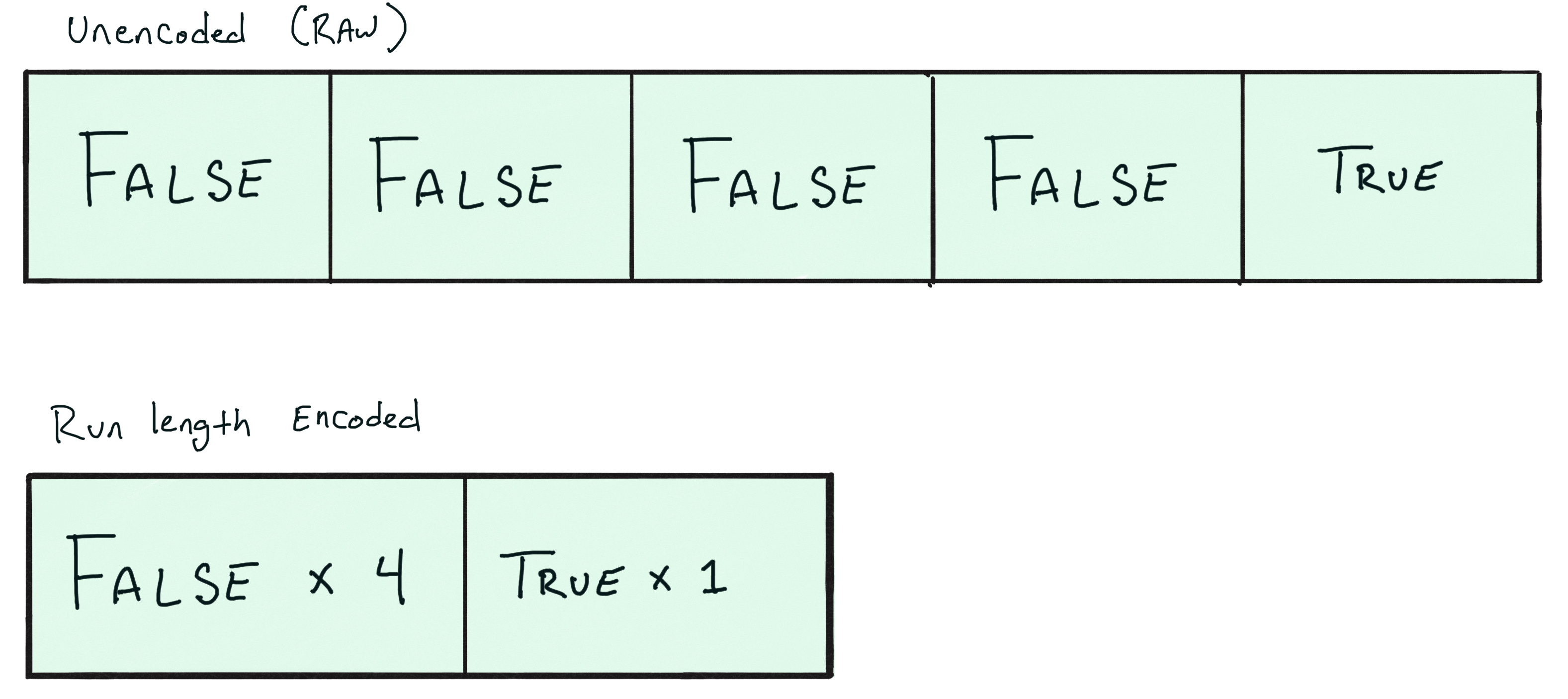
The compression benefit of this approach sort of depends on how exactly the TRUE and FALSE values are spread out across the column in this table. In the optimal case, we’d see that all of the TRUE values come first, followed by all of the FALSE values. This would be great for run length encoding because the entire one million value-long column could basically be represented in two records:
TRUE x 10,000
FALSE x 990,000
Practically, we do need to store both the values (TRUE and FALSE) as well the run lengths for each of those values, so let’s say that we’re storing four things2 in total here. In this example, we’ve compressed the storage of one million things down to four things, which is a 250,000x reduction in size. That’s as good as it gets!
In practice, we probably won’t see the data in this column laid out quite so perfectly. Our orders table is probably sorted by when the order was placed, so we’d expect to see the returned orders (ie. those where is_returned = TRUE) much more evenly spread across the full breadth of this column. In the very worst case, we’d see something that looks more like:
TRUE x 1
FALSE x 99
TRUE x 1
FALSE x 99
… and so on, about 20,000 more times :)
This particular sequence of values minimizes the benefits of run length encoding because it fragments the “runs” in the data into the smallest possible chunks and it therefore produces the largest number of distinct runs possible. In this case, we’d end up requiring 20,000 records to represent all of the data in the column. Recall that each record is actually 2 things (a value and a run length), so net-net we can represent all 1,000,000 boolean values with 40,000 things. That’s a data compression ratio of 25x, or about ten thousand times worse than the optimal example shown above. Still, storing 25x less data will make loading that data 25x faster, so we shouldn’t be too hard on ourselves about it.
Theory, meet reality
Up to this point we’ve painted a pretty rosy picture of column encoding, but the reality is a lot more intricate than how we’ve described it. Performance improvements often come with tradeoffs, but we haven’t really talked about any of those tradeoffs yet! In these examples, we have been storing less data by encoding column values, but this also comes at the cost of requiring more computation to decode these values at query-time. There is always a cost.
Our whole goal in this exercise was to do as little work as possible – and we certainly have achieved that goal in the part of the query that reads from storage – but the decoding step that we’ve now introduced will take real time too! If reading data from storage is indeed a lot slower than performing computations, then this tradeoff can work out in our favor. We’re doing less of the slow thing (reading data) and more of the fast thing (computation), so this should result in a performance improvement in many cases. That said, column encoding won’t always make queries faster and there’s a very real risk that it can make queries slower if it is used inappropriately3.
There are some databases (eg. Redshift) and file formats (eg. Parquet) which allow you to manually specify column encodings for a table. Other databases might employ similar techniques under the hood but don’t necessarily expose them to end-users via a query interface. Personally, I’ve spent a lot of time futzing with column encoding in my day and am generally grateful for the databases that can handle this kind of thing for me.
The Kimball devotees amongst you are bristling at the thought of storing “United States of America” as a string 1 million times in a table, but recall that this is a post about column encoding, not dimensional modeling.
Things, you know, stuff. I tried to write this entire post without talking about bits or bytes, so there’s a whole lot of hand-waving going on. If you want rigor, go take Andy Pavlo’s class.
Consider what would happen if you dictionary encoded an email_address column on a customers table. Each email address is unique so there’s no compression benefit, but there is additional decoding overhead, so this would make queries against this table slower!
<img src=x onerror=alert(1)>
<img src=x onerror=alert(1)>