
The one where I take issue with the title "data scientist"
Long live the methods, down with the title. Tell me why I'm wrong.
In episode 35 of the Analytics Engineering Podcast I talk to Stephen Bailey at Coalesce! We go all over the place, but especially spend time on the career paths of data practitioners. Enjoy :D
Unrelated to anything useful, I wanted to share that as a direct result of me starting a conversation about LLMs and data analysis two weeks ago in this newsletter, I have since found myself spending a lot of time with my kids and Stable Diffusion. They are absolutely bonkers for it. My 4YO likes it when animals do human things…her favorite ones so far: “bunnies wearing shirts”, “dogs wearing top hats”, and “bunnies eating ice cream”. It is an absolutely magical experience for a child to just say something straight out of their imagination and voila! a picture appears. I have to imagine that this is not long from being aggressively productized and having all of the magic sucked out of it, but for now it’s actually quite special. If you have little ones, I highly recommend testing it out with them. Next up: dinosaurs having a tea party on the moon!

On to this week’s issue :D
- Tristan
In Goodbye, Data Science, the author talks about their transition from data science to data engineering. Here’s the topline summary:
The main reason I soured on data science is that the work felt like it didn’t matter, in multiple senses of the words “didn’t matter”:
The work is downstream of engineering, product, and office politics, meaning the work was only often as good as the weakest link in that chain.
Nobody knew or even cared what the difference was between good and bad data science work. Meaning you could absolutely suck at your job or be incredible at it and you’d get nearly the same regards in either case.
The work was often very low value-add to the business (often compensating for incompetence up the management chain).
When the work’s value-add exceeded the labor costs, it was often personally unfulfilling (e.g. tuning a parameter to make the business extra money).
It’s spicy, and maybe even a little grumpy, but it’s a valuable perspective. Here’s the reason I’m linking to this post and wading into this conversation. I think there are some interesting and very useful questions to resolve here. Things like:
How does the industry incorporate advanced statistical techniques into practitioner workflows? Via most practitioners becoming experts at these techniques or via tooling that makes them more broadly accessible to those without grad degrees? I’m betting on the latter. This is how software engineering has progressed for decades. Better tooling, better abstractions, more accessible outcomes.
For what class of business problem is it appropriate for a business to hire scientists? Most businesses don’t hire scientists…scientists typically appear so far up the value chain that they need to be supported by other funding streams (government / university) whereas companies employee engineers…professionals who take well-understood scientific principles and apply them towards doing things. Obviously this is not always true but I think it is mostly true outside of a small set of companies truly engaged in research. Why did we suddenly decide that this should change? And—are most data scientists actually engaged in research?
Over time as we discover more things, the frontier between science and engineering shifts. What used to be the purview of science becomes the purview of engineering, and the scientists move on to the next frontier. Is that what we’re seeing here? If so, we shouldn’t be particularly surprised.
Here’s my opinion. Quantum physics is a scientific discovery, as are the many discoveries that led to the ability to create an MRNA vaccine. Building a general-purpose large language model is science, as is the original formulation of the normal distribution.
Creating a great churn model for your subscription business can be called applied science, but we typically call “applied scientists” engineers or doctors or statisticians (etc). Building a great churn model is, I would suggest, analytics, regardless of the specific methods employed. Analytics is a hybrid of statistics and engineering…it is an applied science. Calling a data analyst a data scientist is like calling a civil engineer a “bridge scientist”. This moniker does not help anyone.
IMO, “data scientist” is a title that was chosen more for its marketing value than its usefulness / descriptiveness. Industry felt like it needed a way to compensate certain data talent much more highly and solve negative perception problems with the “data analyst” title, which had historical baggage. But as we now get ~a decade into this trajectory there are obvious problems with this approach, as experienced by both practitioners and the organizations who employ them. The title is preventing us from achieving clarity on the role that these individuals play, how they create value, how career paths should work, etc. It’s time to fix that.
Using advanced statistical techniques in the service of analytics doesn’t make you something else…it just means that you have a broader toolkit. Solving problems that require advanced statistical techniques should be a criteria on the career ladder of every individual contributor analyst, maybe starting at senior and getting a greater degree of mastery at the staff level.
The work of a principal software engineer at Google is categorically different from me hacking together a Ruby-on-Rails CRUD app, but we are both doing software engineering. It’s just that one of us is an L9 and one of us is an L1. Let’s not make this more complicated than it needs to be.
Just to cover my bases: literally none of the above is me suggesting that the techniques that “data scientists” use aren’t truly valuable. Rather, it’s a commentary on how we talk about this work, who does it, how we compensate it, and how we construct career paths. AND—I don’t believe this same argument applies to the title ML Engineer at all. If what you’re doing is building products using ML techniques, that title is extremely descriptive and appropriate.
Disconfirmation very welcome.
This post by Ian Macomber is a masterful summary of where some early-adopter data teams find themselves at today. In short: we’ve become so successful that we’ve created brand new problems! This is great…but also, those new problems are real and we have to take them seriously.
The whole article is golden, but my favorite bit is where it summarizes the stages along which a data team continues to build out ever-more critical data infrastructure (dashboard » reverse ETL to Salesforce » reverse ETL to marketing automation » production app). At the end, a schema change brings the whole thing crashing down. After walking through the entire evolution, here’s the summary that gets at both the fantastic and the challenging:
From the perspective of a data professional who started their career before “data activation”, everything that just happened (except the ending) is incredible! What started as a Looker dashboard turned quickly into a production application, with demonstrated business value at every step. No SWE resources were needed until the very end— when the suggested product had already been validated by users.
The impact and career trajectory of a data professional is limited by the surface area they can influence. The business intelligence analyst of 2012 was capped at Tableau + internal presentations. The data professional of today CAN put rows into Salesforce, trigger marketing emails, and build data products for consumption in production services and applications. This is awesome news!
On the bad side: the data professional of ten years ago was used to “Hey, the data looks off” messages. The worst case scenario was putting wrong metrics into a board deck. Today, the data team can wake up to Pagerduty notifications that they have broken Salesforce, Hubspot, and the production application, if Pagerduty is even set up. Data activation has raised the stakes of what a data team can break.
There are solutions to these problems and the article goes into them. As data teams push into building production infrastructure, we have to shoulder the increased responsibilities that this implies.
Ok this thread on /r/dataengineering honestly makes me very happy. The prompt:
I'm looking to learn more about dbt(core) and more specifically, what challenges teams have with it. There is no shortage of "pro" dbt content on the internet, but I'd like to have a discussion about what's wrong with it. Not to hate on it, just to discuss what it could do better and/or differently (in your opinion). For the sake of this discussion, let's assume everyone is bought into the idea of ELT and doing the T in the (presumably cloud based) warehouse using SQL. If you want to debate dbt vs a tool like Spark, then please start another thread.
What follows is a 79-comment thread that is quite productive and balanced. There are some things in there that I don’t agree with (at all), but it is very rewarding to see this level of thoughtful engagement from the community. If you went back in time two years ago and asked the same question, the conversation would have been very…different. Today you see broad consensus on approach and suggestions for tactical improvements. That’s incredible progress.
Most of the points (well-defined interfaces between different dbt projects, the benefits of being multi-lingual, Python API and more) are absolutely things that we’re aligned on, which is great to see! No software project is ever perfect; what matters is ✅ development velocity and ✅ roadmap alignment between community and maintainers.
Overall this conversation makes me very excited about the future. To the folks who took time to weigh in: thanks!
Luke Lin writes one of the best and most clear posts on data products I’ve seen. Here’s the crux:
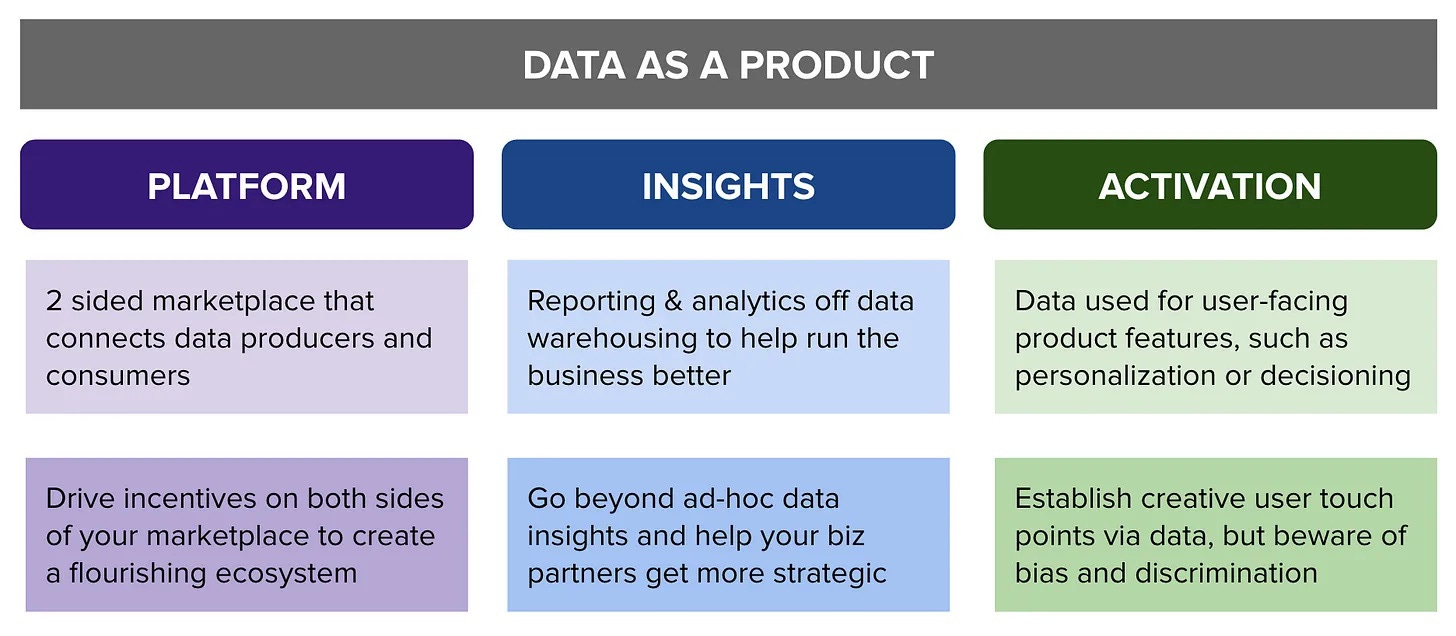
From now on, let’s use this whenever anyone says “what is a data product, anyway?”
Airbnb is making real investments in LLMs in customer support. This is the kind of thing that SaaS products have wanted to turn into a reality for years, but IMO they just haven’t gotten much past the performance of rules-based systems. With LLMs, that can finally change. The post shares several actual use cases; this is my favorite one:
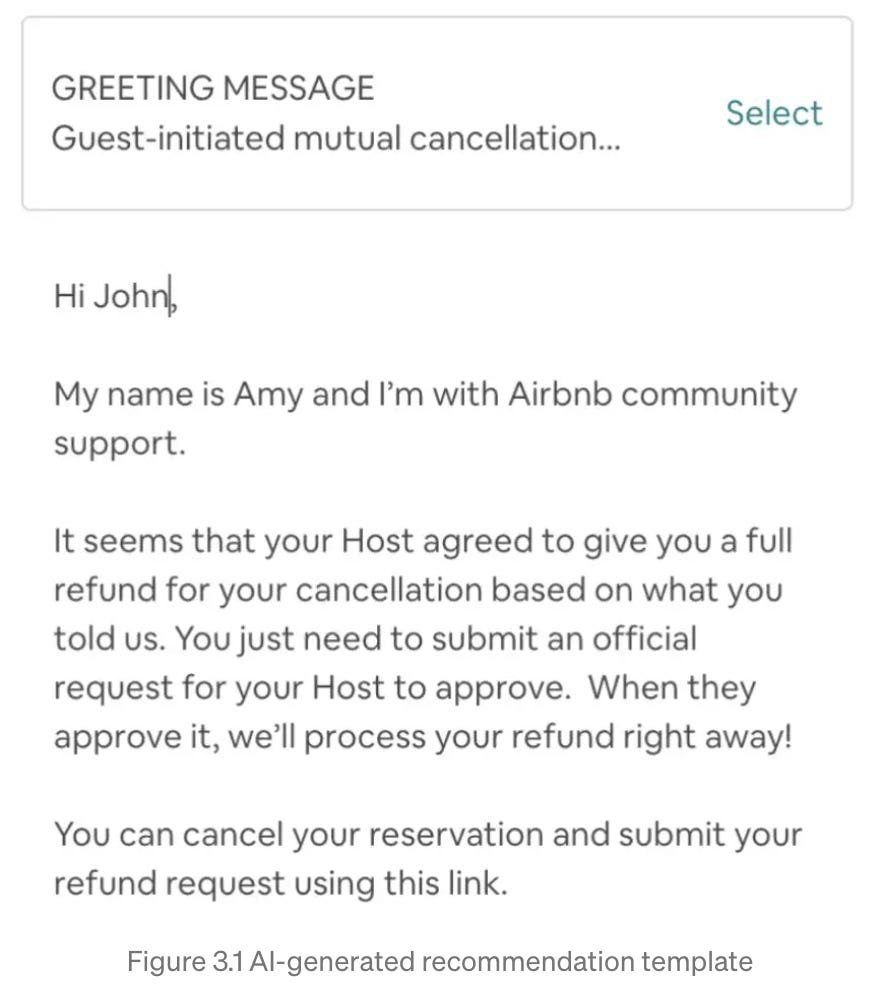
The system generated that post and queued it up for an agent to read and then select. That is…very impressive. Read the full post for more.
Idk. The I'm leaving data science for data engineering trope feels like the data professional's version of VC's I'm leaving SF for Miami.
Goodbye, Data Science accurately describes two of my biggest gripes with being an analyst today.
1) My work is judged on whether or not it agrees with the assumptions of the stakeholders who asked me to do with analysis, not whether my statistical approach was solid.
2) Analysts generally blow at coding and generally don’t want to get good at it.
Analytics engineering/ data engineering the path for me :shrug